人工智能导论 极速版
zstu 浙江理工大学 2023学年第1学期 人工智能 开卷考试 期末复习
介绍
智力是学习、理解或处理新情况或困难情况的能力;
应用知识来操纵环境或抽象思考的能力

知识表示
命题逻辑
理论
命题是一个陈述句,并且必须能判断真假



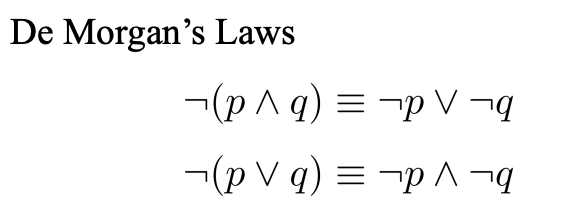

题目







谓词逻辑
理论
谓词描述关系
P(x) 或 M(x) 表示一个一元谓词逻辑
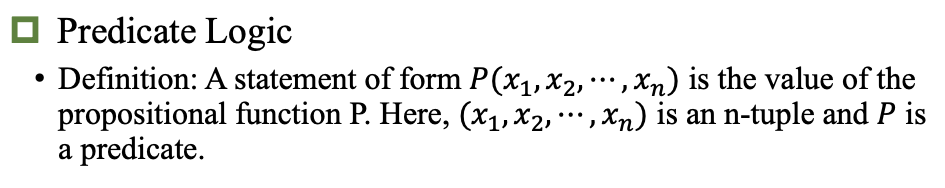


量词不能随意调换顺序
量词的优先级比逻辑联结词高



前束范式运算前先换名

题目





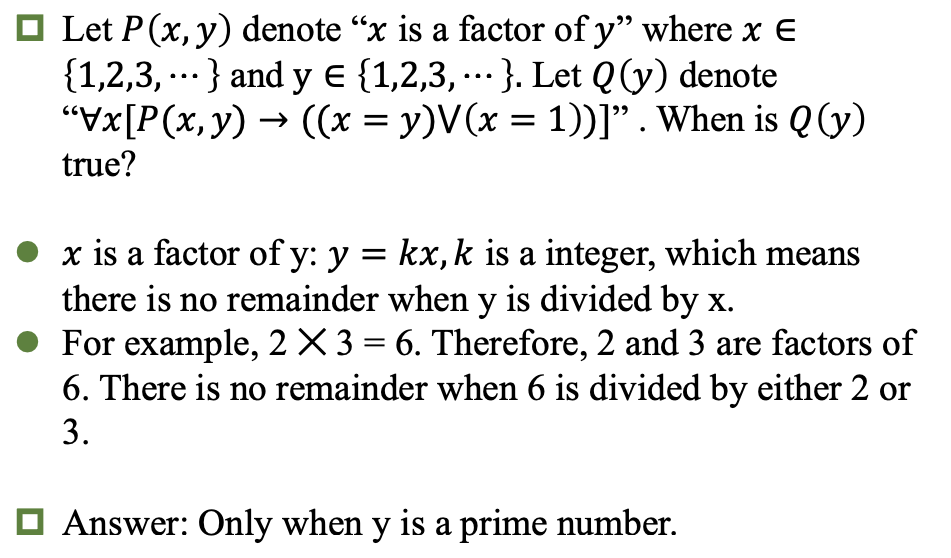
产生式系统
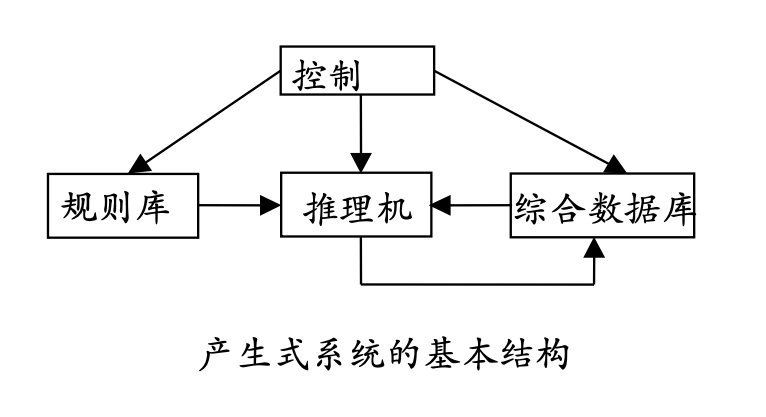




框架系统



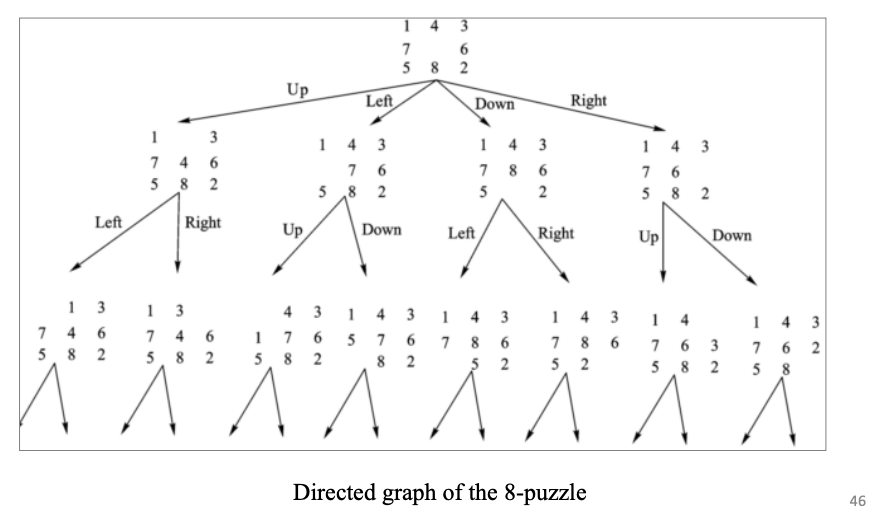
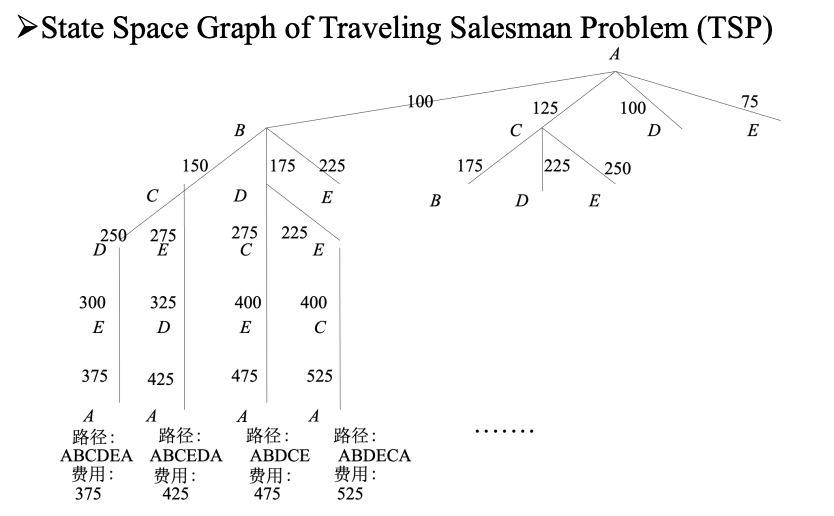
状态空间系统


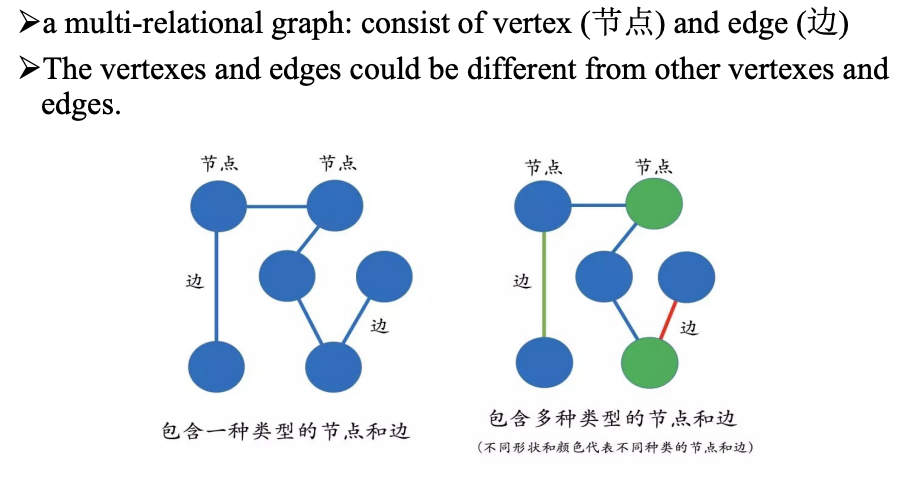
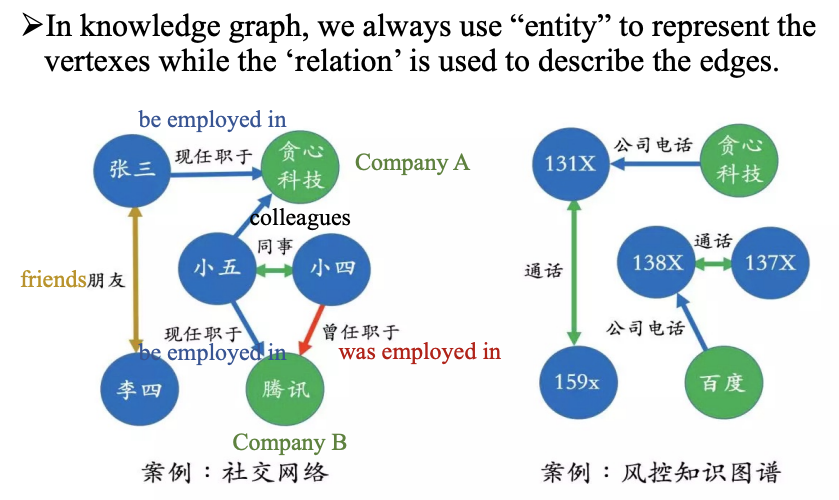
知识图谱*




搜索
理论






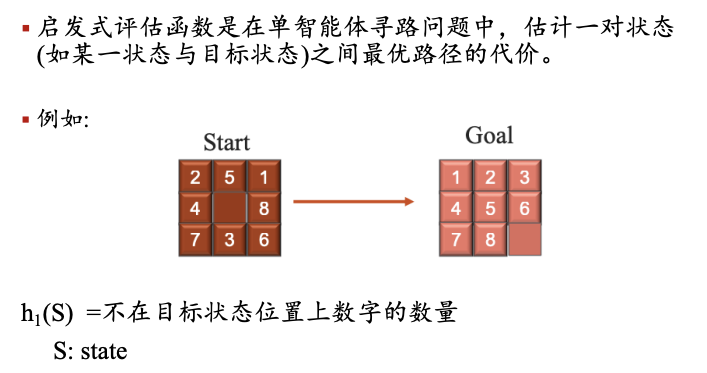

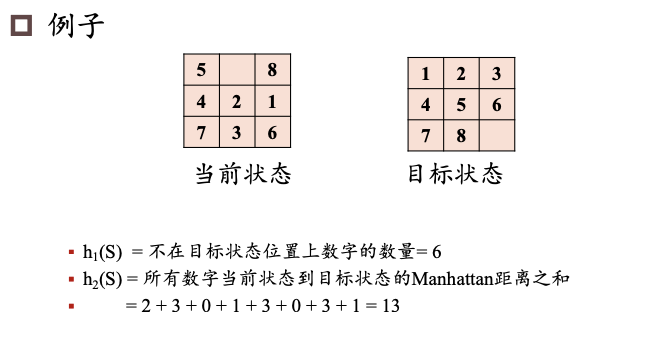
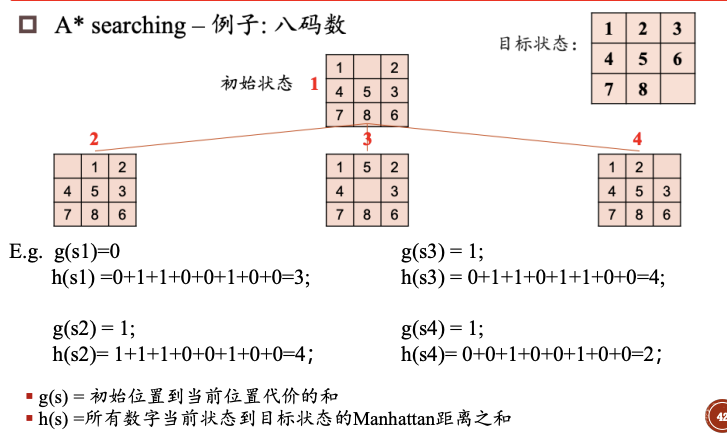
题目
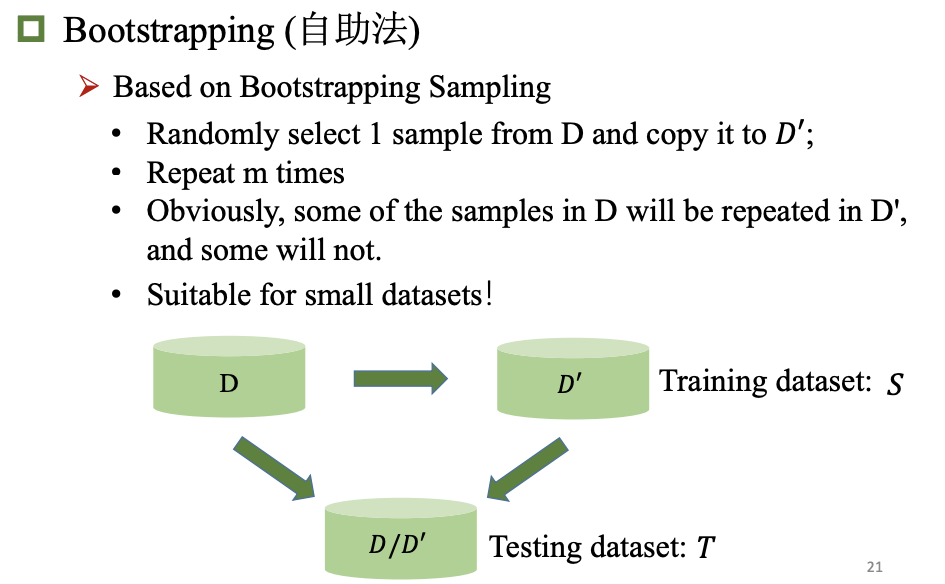
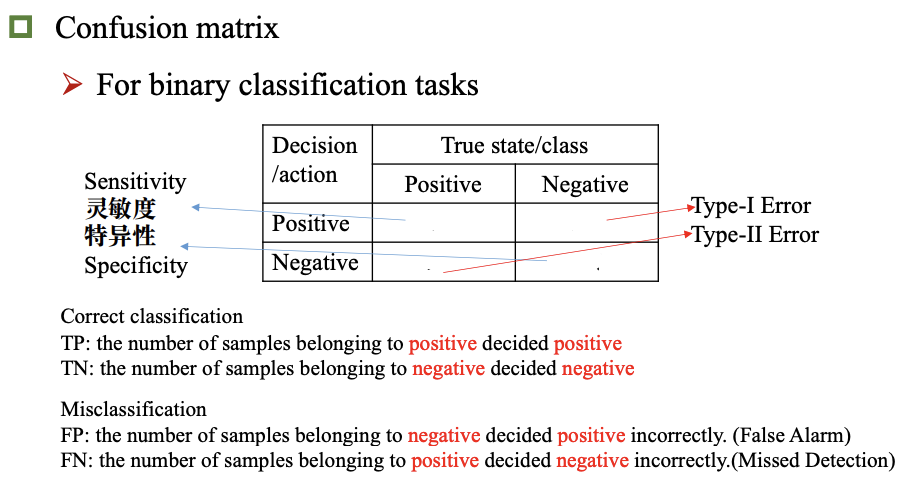
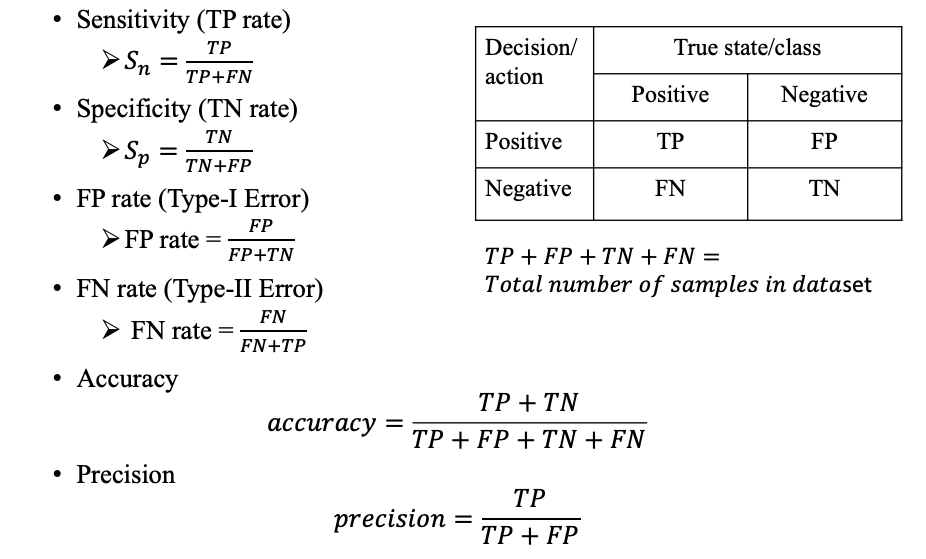
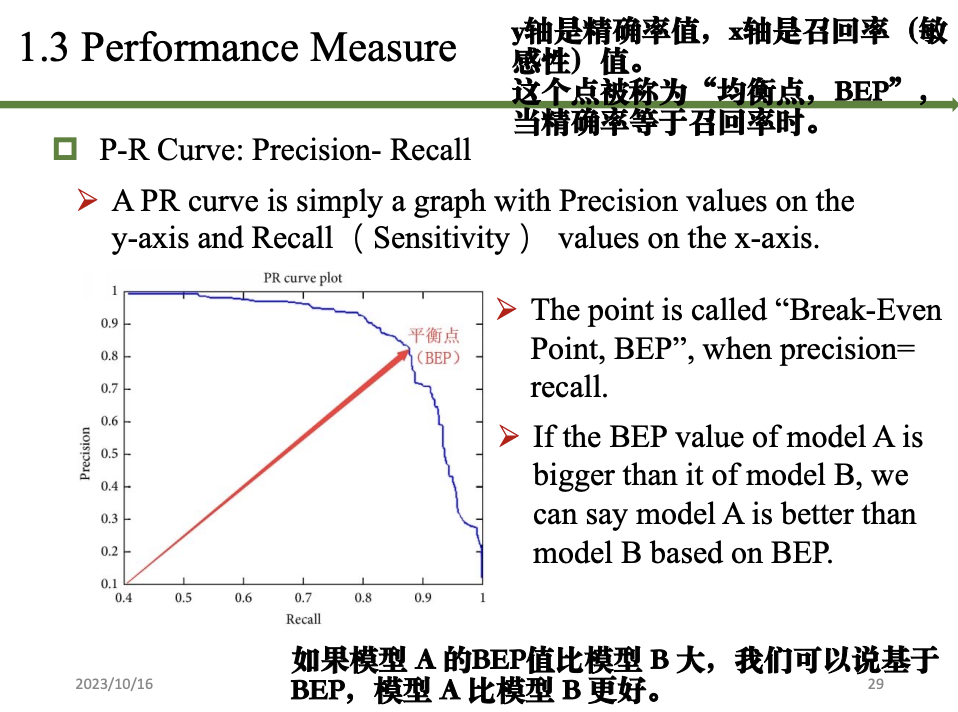
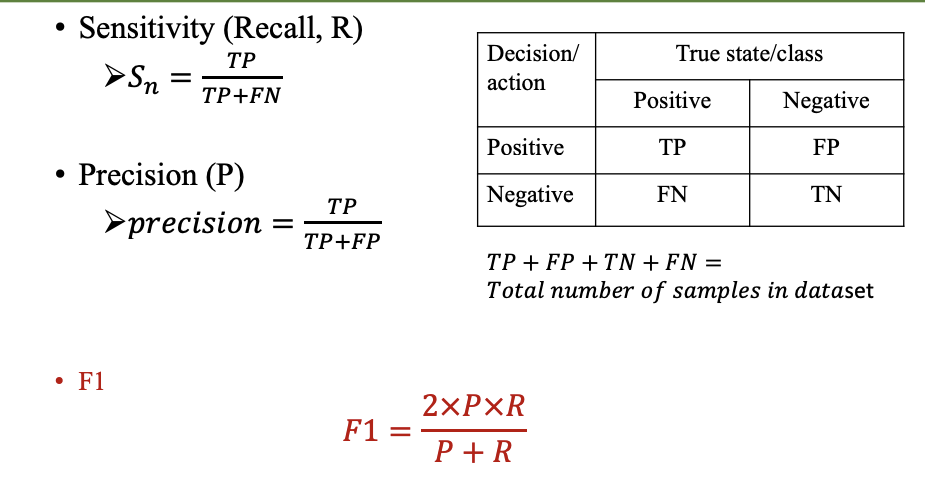
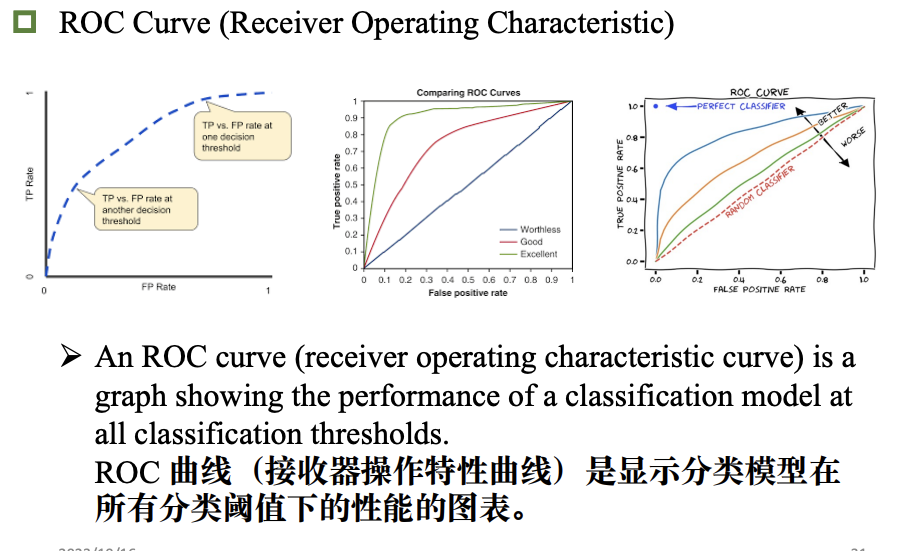
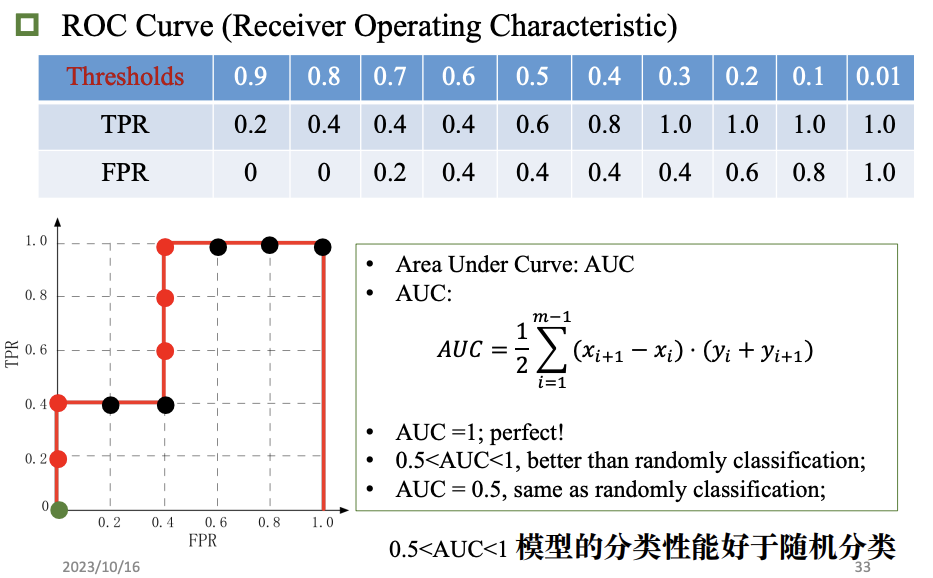
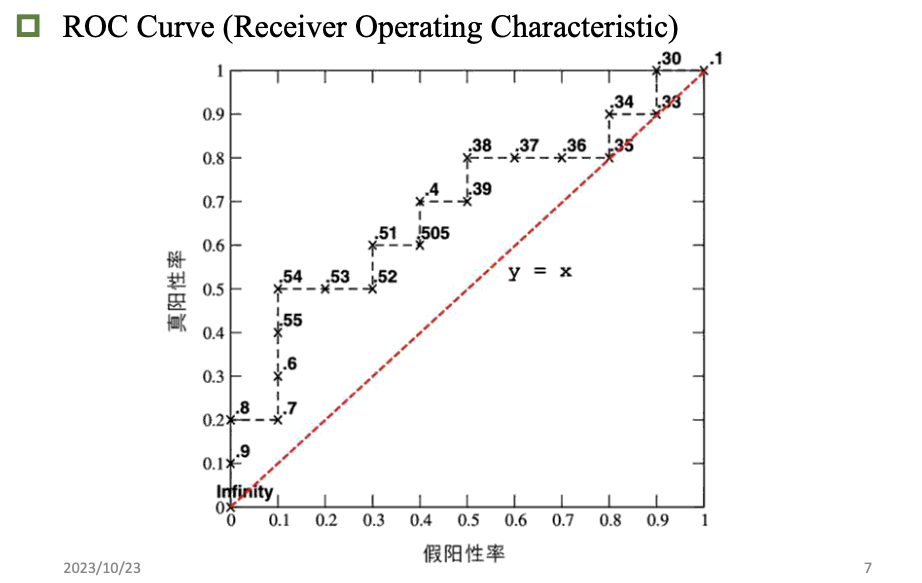
模型评估和选择
准确率 误差 过拟合





评估方法



性能指标


题目


机器学习
监督学习
回归
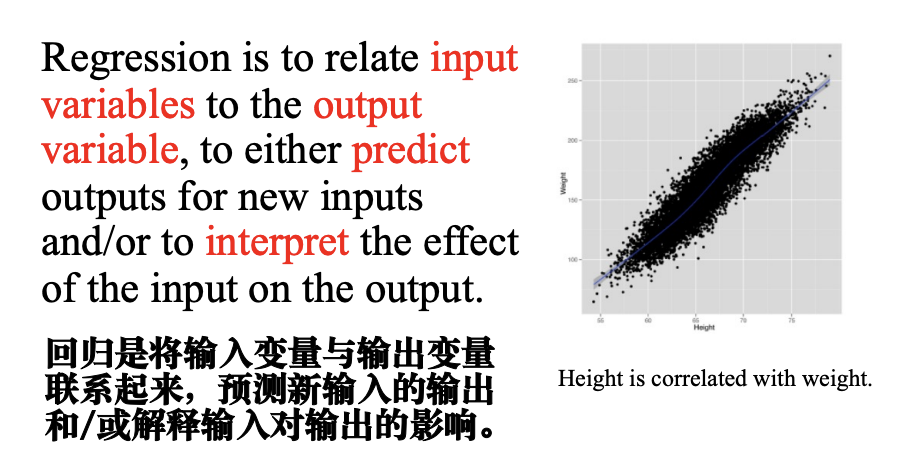
线性回归




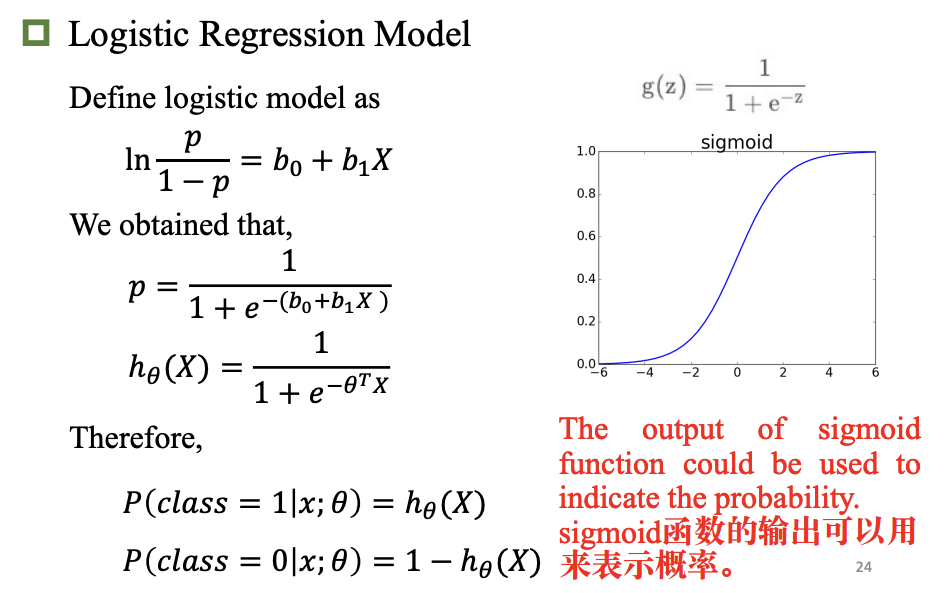
逻辑回归

分类
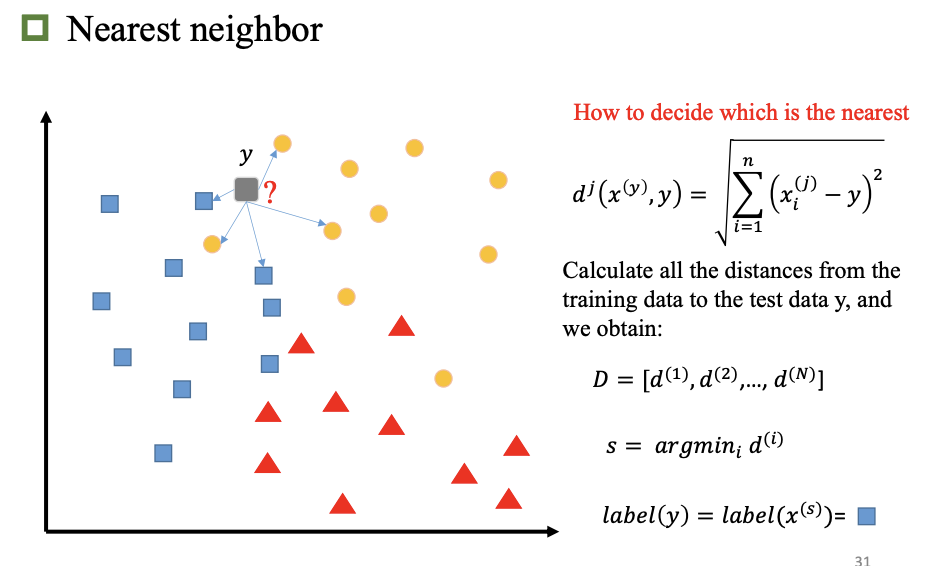
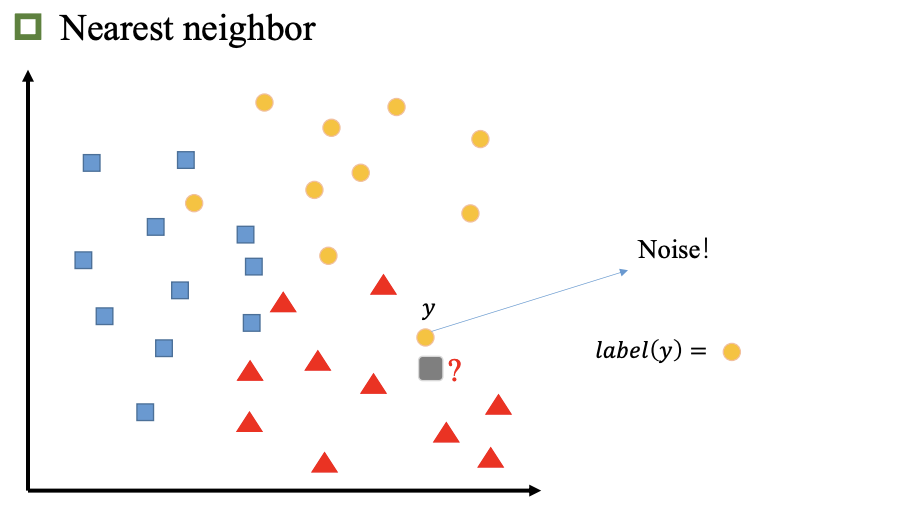
最近邻
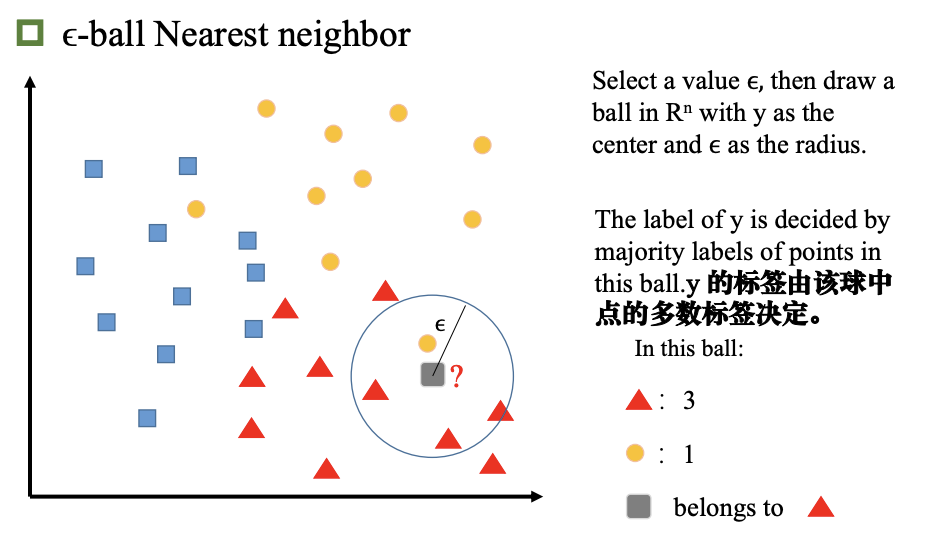
ϵ-ball 最近邻
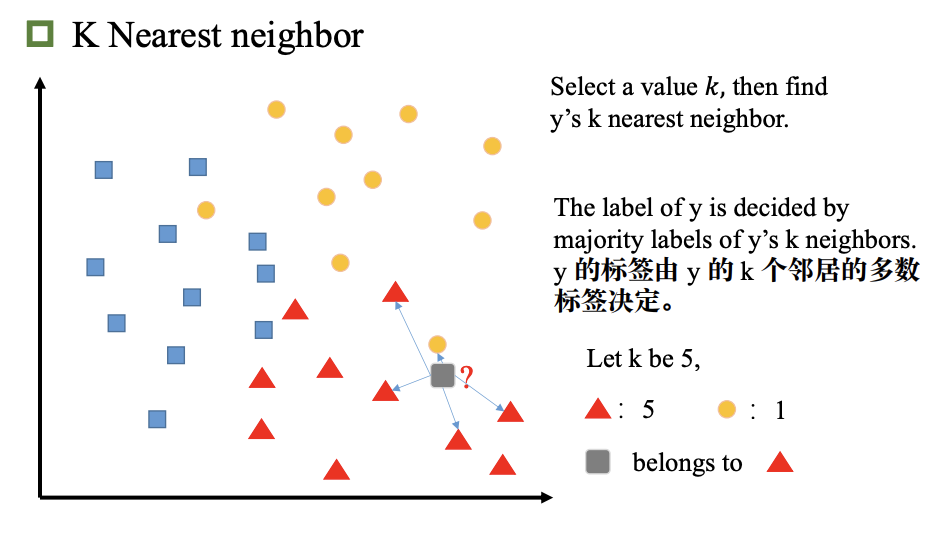
K 近邻
确定 k 近邻算法(k-NN)中 k 值的大小是一个重要决策,因为它直接影响到算法的性能。没有固定的规则来选择最佳的 k 值,但是可以通过以下方法来确定:
交叉验证:最常用的方法是通过交叉验证,特别是 k 折交叉验证。在这种方法中,数据集被分成 k 个小组(folds)。算法在 k-1 个小组上训练,并在剩下的一组上测试。这个过程重复进行,每次选择不同的组作为测试集,然后取平均误差率。通过比较不同 k 值的误差率,可以选择最佳的 k 值。
误差率:对于分类问题,可以计算不同 k 值对应的误差率。误差率最低的 k 值通常会被选择。对于回归问题,可以计算均方误差(MSE)。
启发式方法:通常,k 值的选择应该是一个奇数(如果类别数为偶数),以避免决策的平局。一个常见的启发式方法是选择 (\sqrt{n}),其中 n 是训练样本的数量。
距离权重:考虑距离权重可以减少更远邻居的影响,这样可以在考虑更多的邻居(较大的 k 值)的同时减少噪声数据的影响。
问题特定知识:有时,对问题的了解可以帮助确定 k 的值。例如,在高度不平衡的数据集中,较大的 k 值可能有助于防止算法过分偏向多数类。
模型复杂度:较小的 k 值会导致模型复杂度高,可能过拟合数据;较大的 k 值会导致模型简单,可能无法捕捉数据结构。因此,需要找到一个平衡点。
可视化工具:有时候,将不同的 k 值的效果可视化,例如通过绘制误差率和 k 值的关系图,可以帮助选择一个好的 k 值。
规则化方法:当数据集非常大时,可以使用规则化方法来选择 k。例如,可以将 k 设置为训练样本数量的一个小百分比。
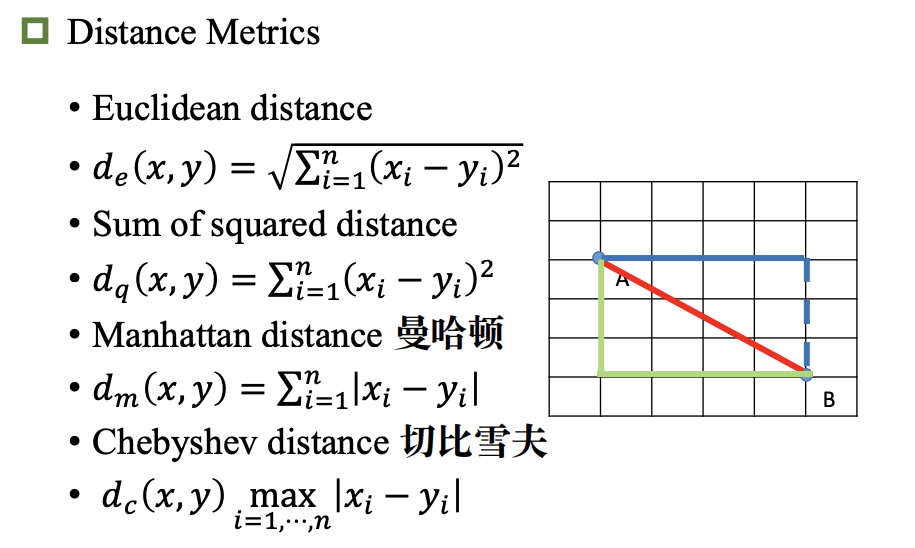
距离
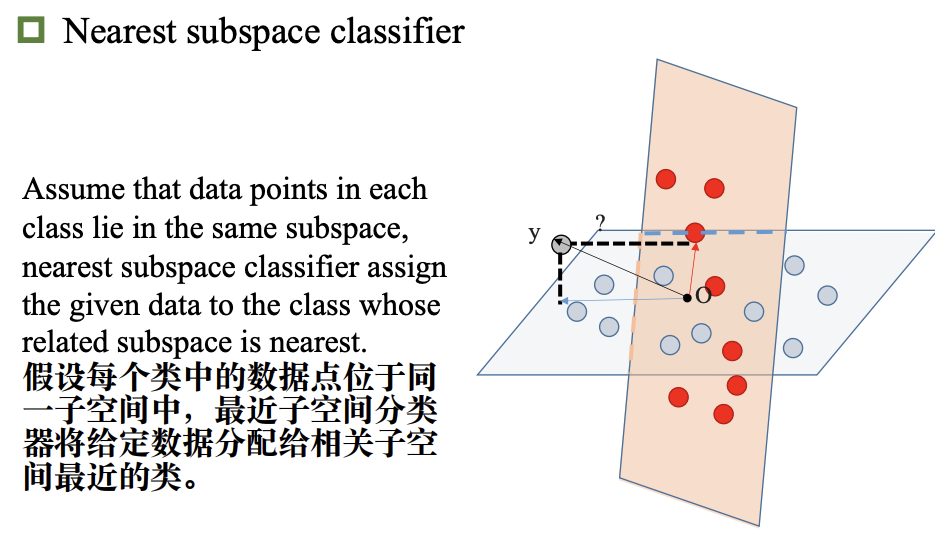
最近子空间分类器*

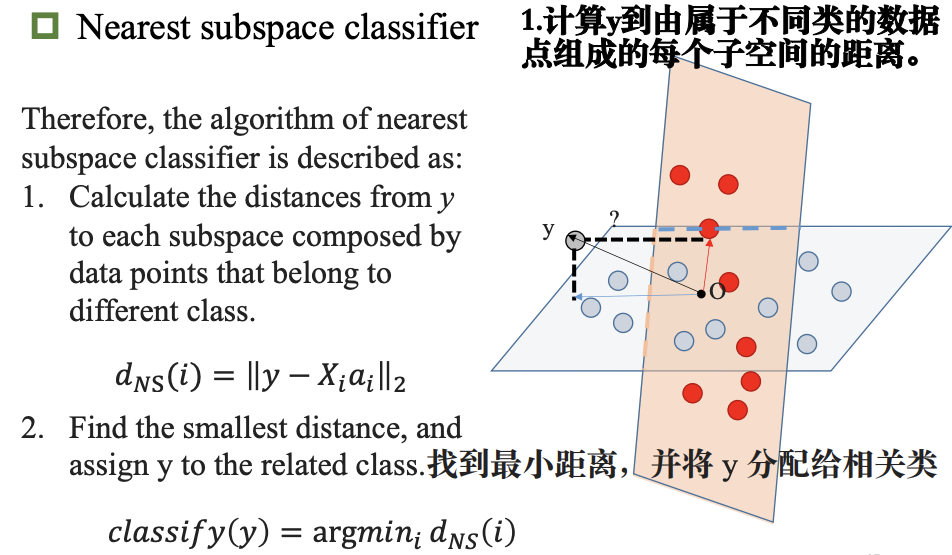
非监督学习
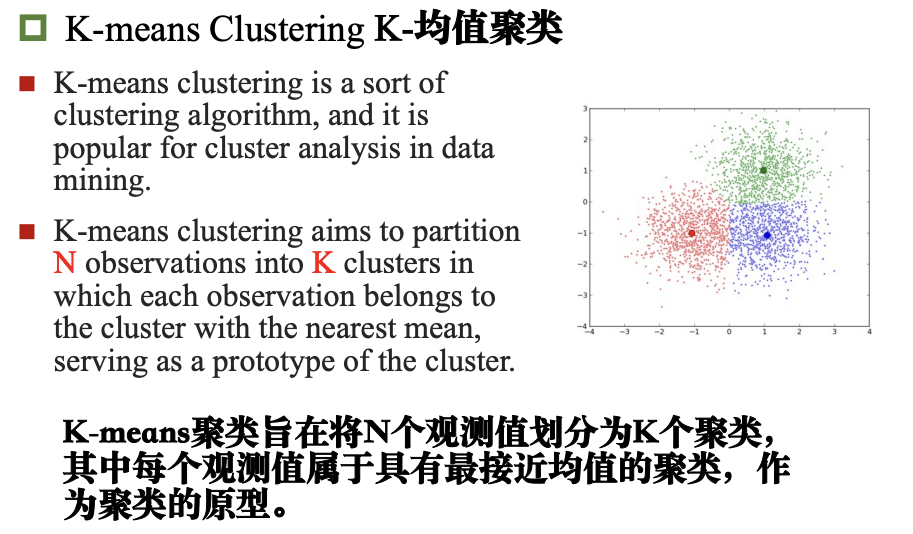
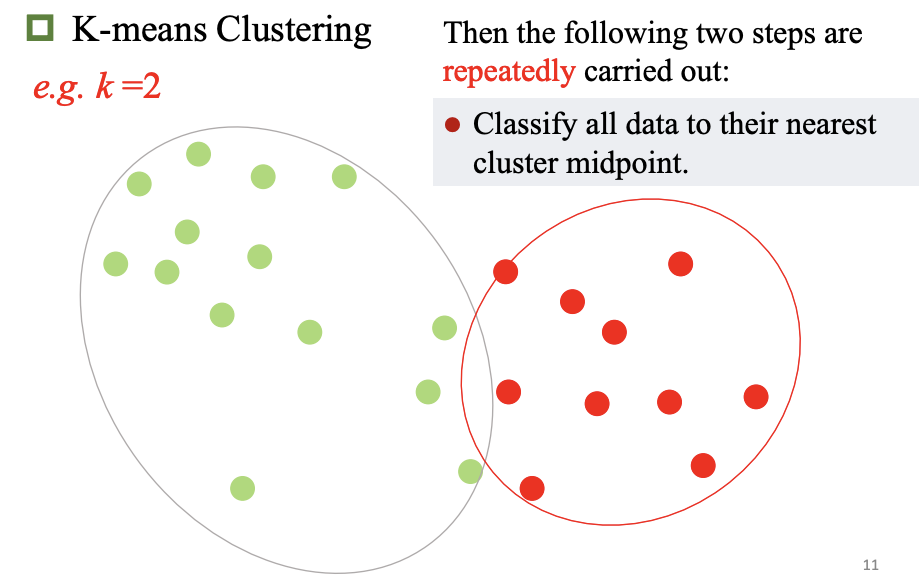
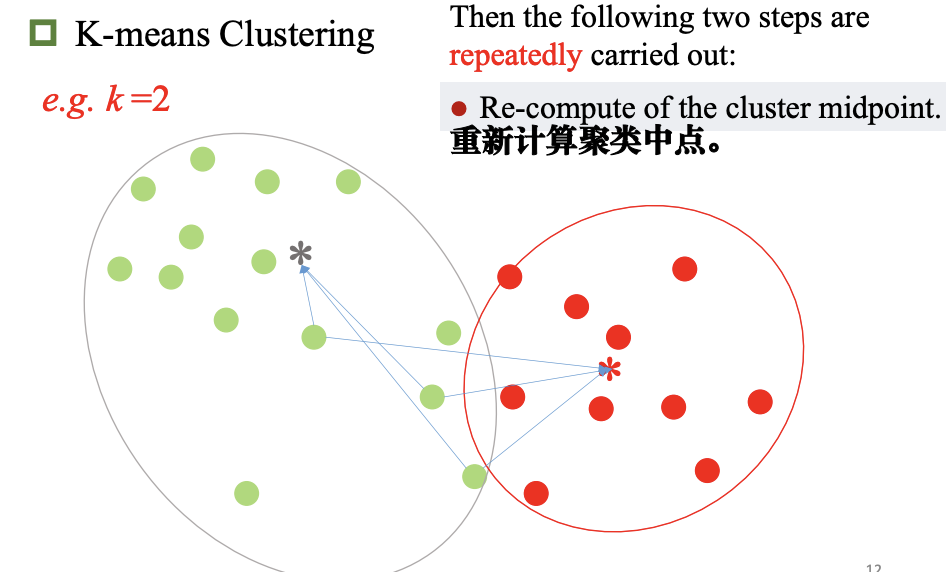
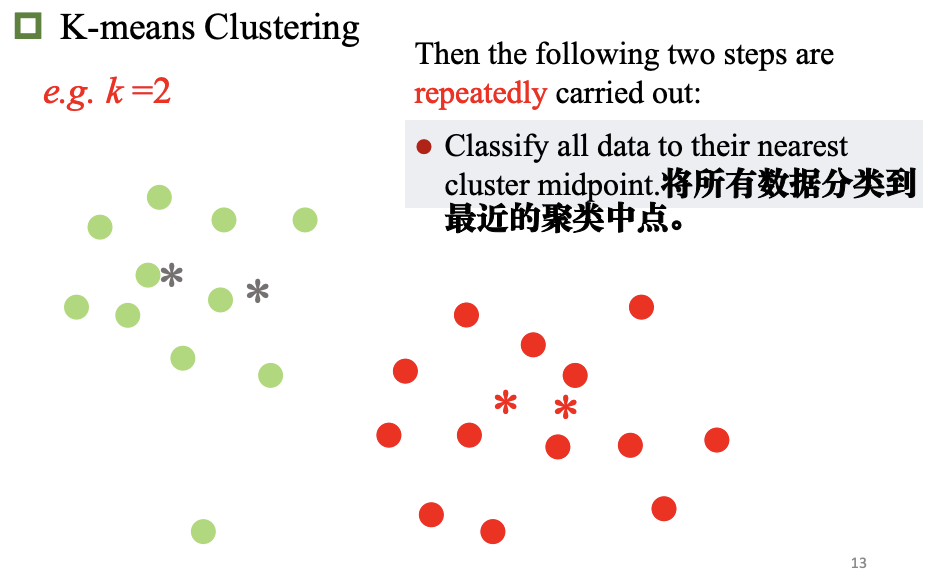
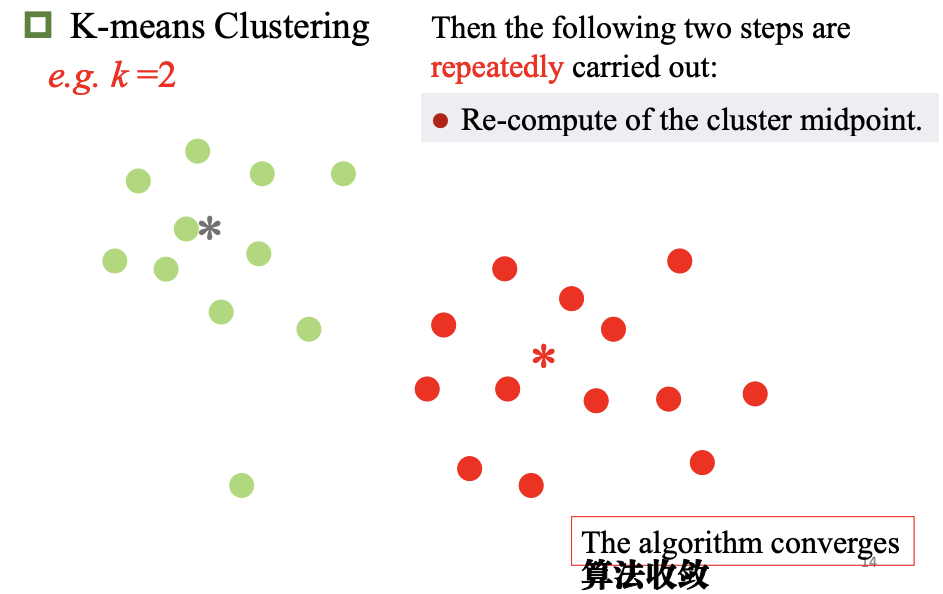
K-均值聚类





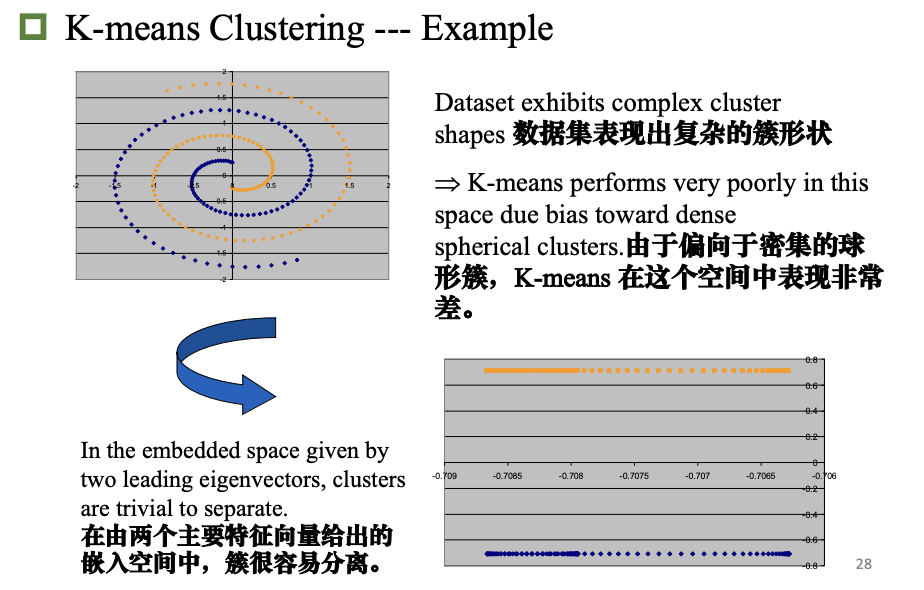
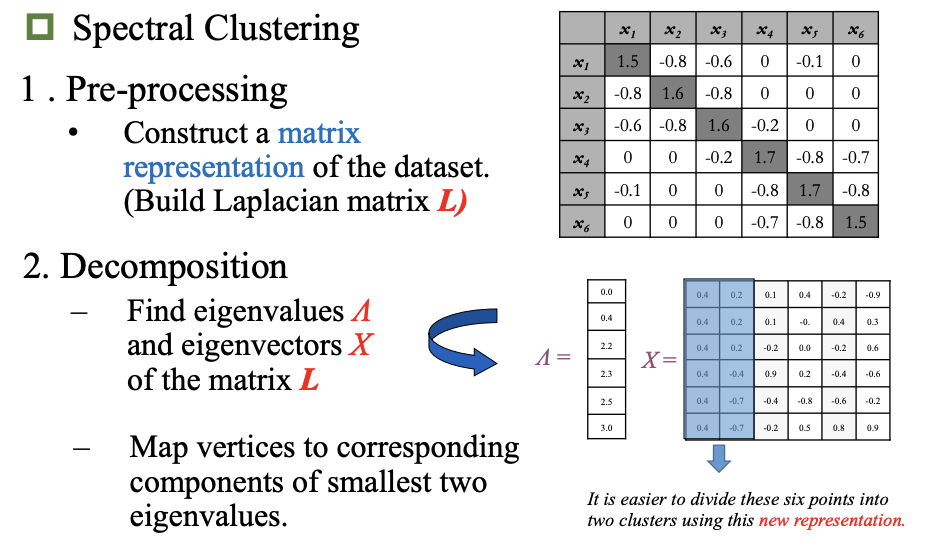
谱聚类*


题目





表示学习-线性编码*
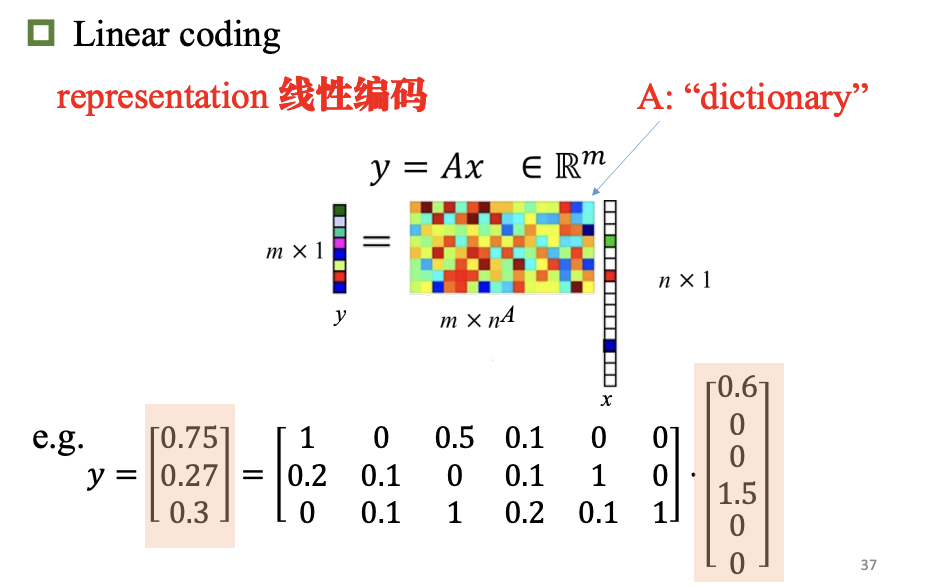

表示学习-PCA*


表示学习应用:人脸图像压缩 图像去模糊 图像去噪 形态成分分析 图像修复
强化学习




Q-Learning



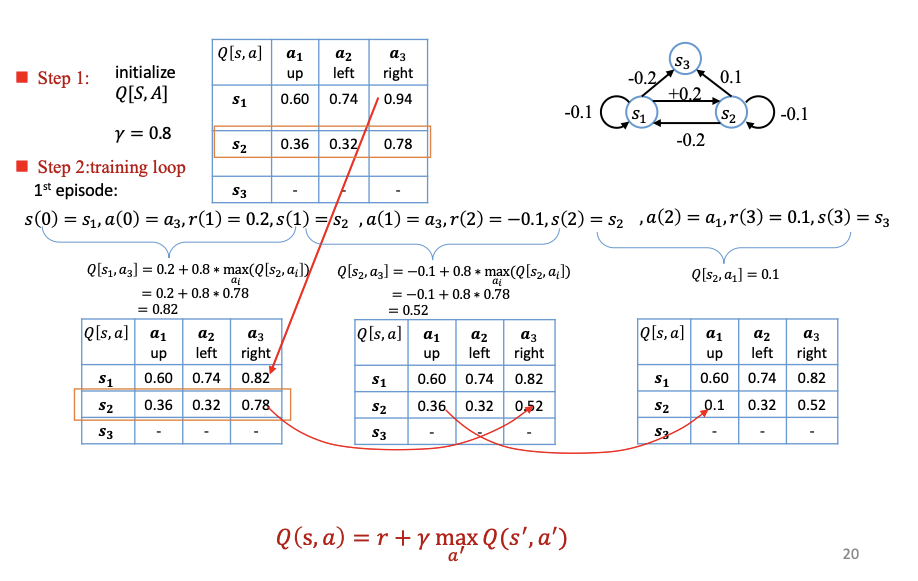

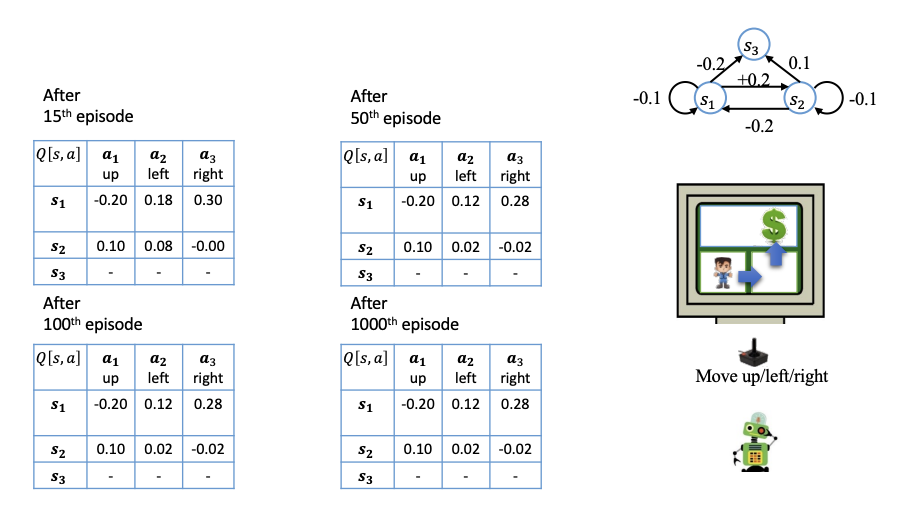

神经网络
历史
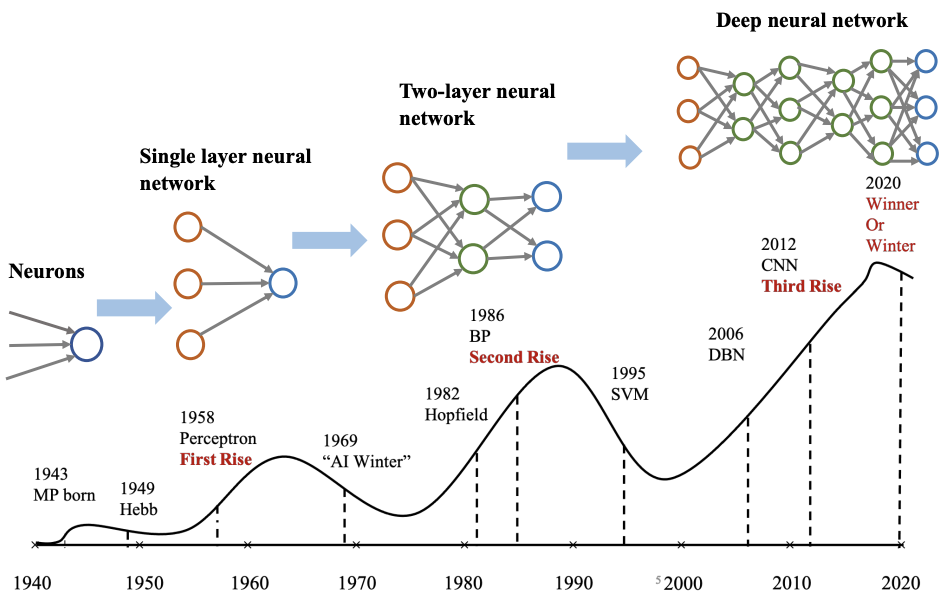
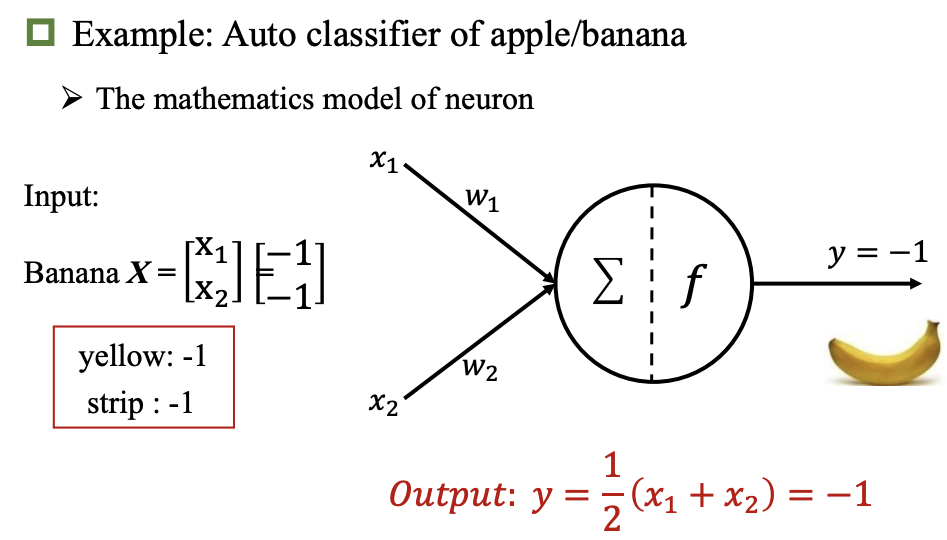
神经元
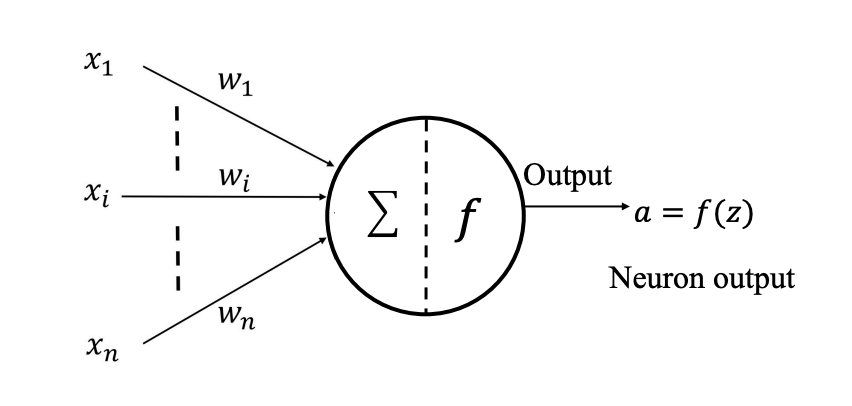
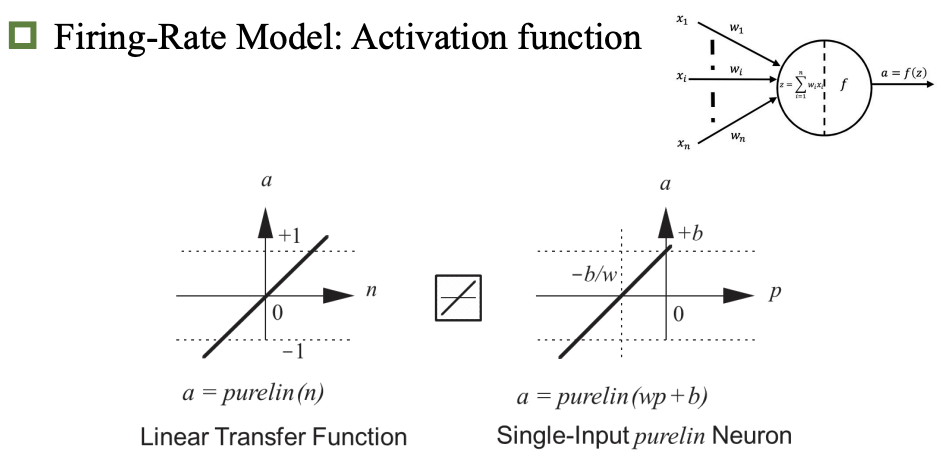
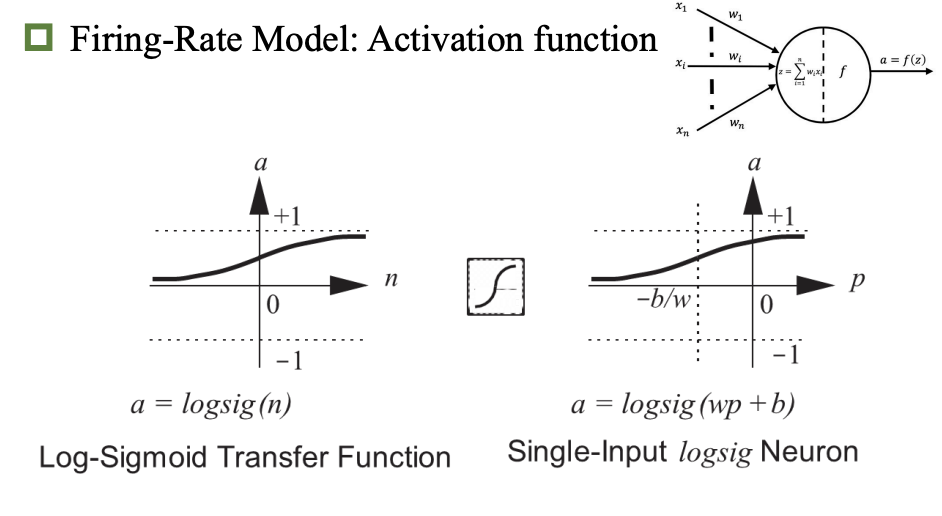
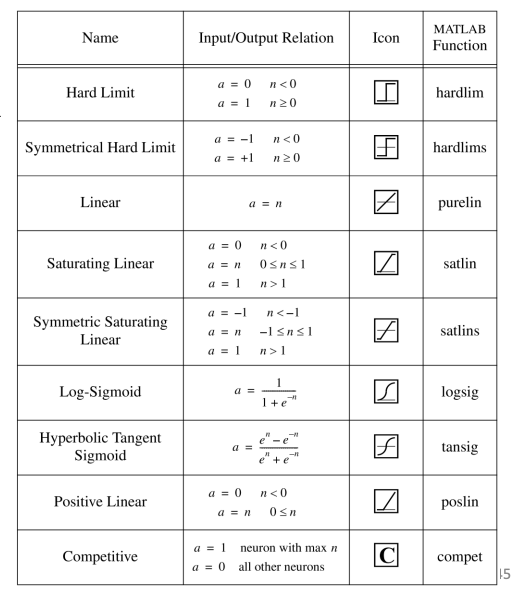
激活函数

题目
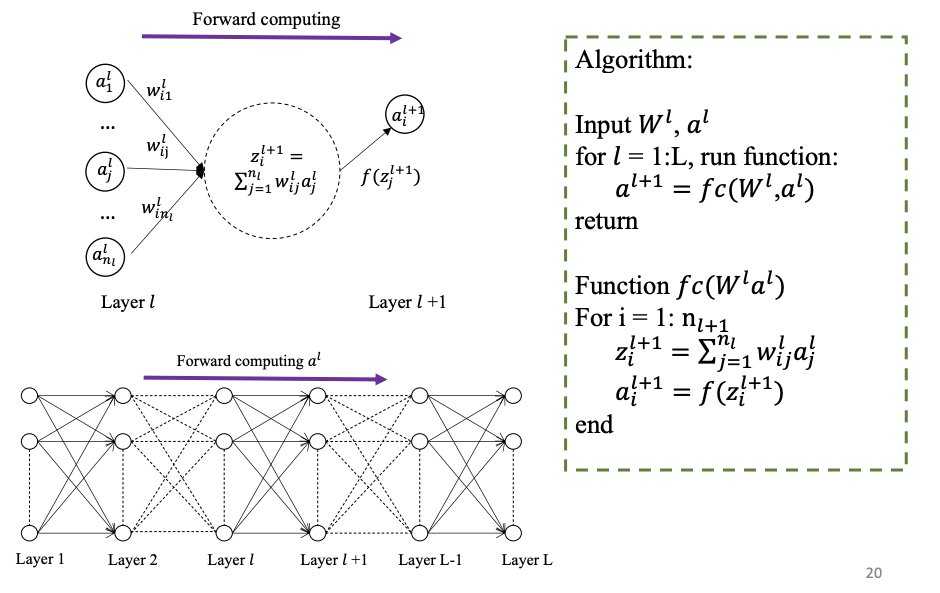
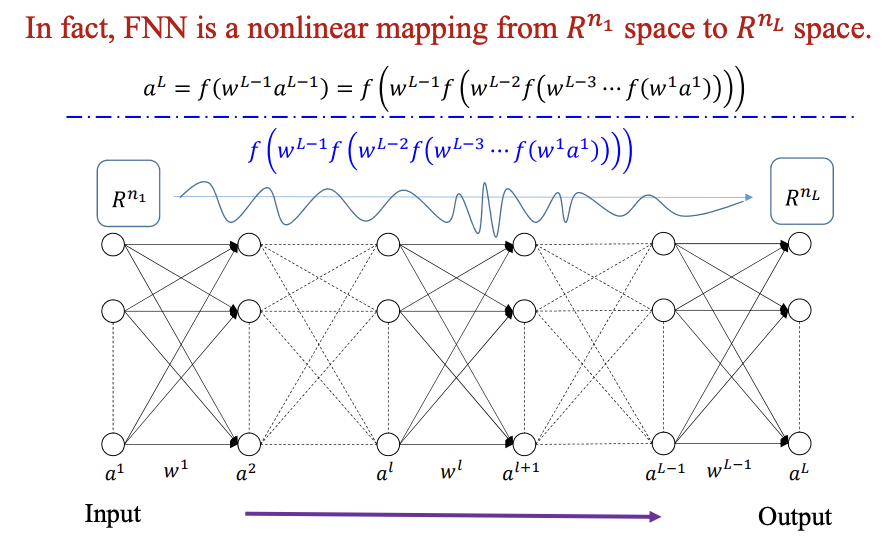
前馈神经网络 FNN
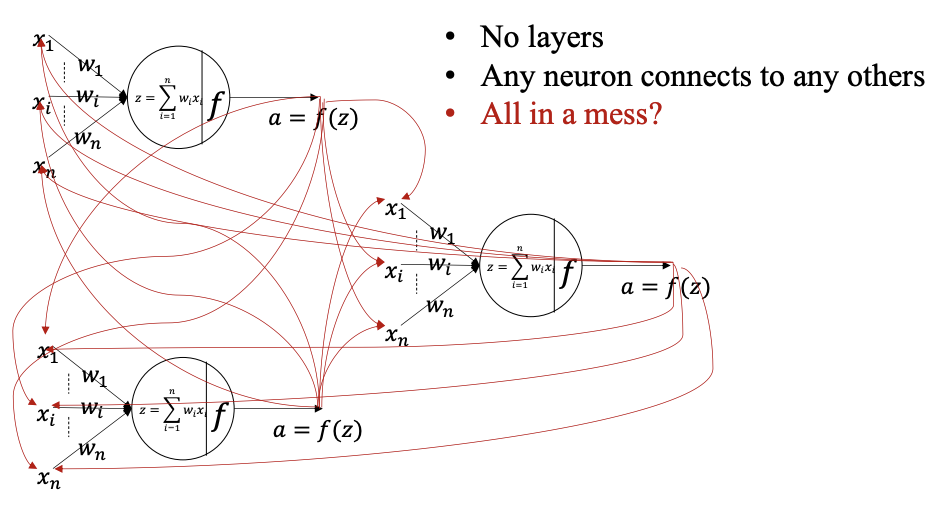
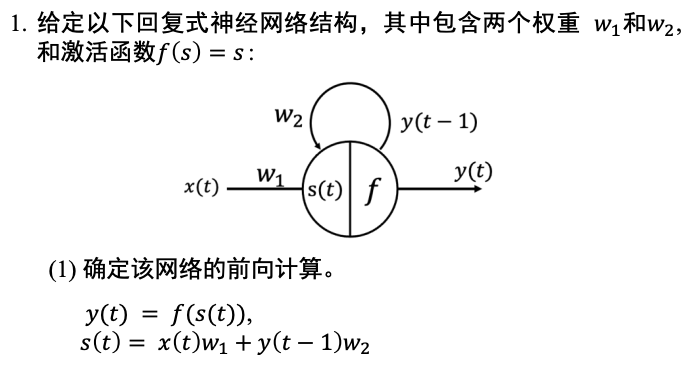
循环神经网络 RNN
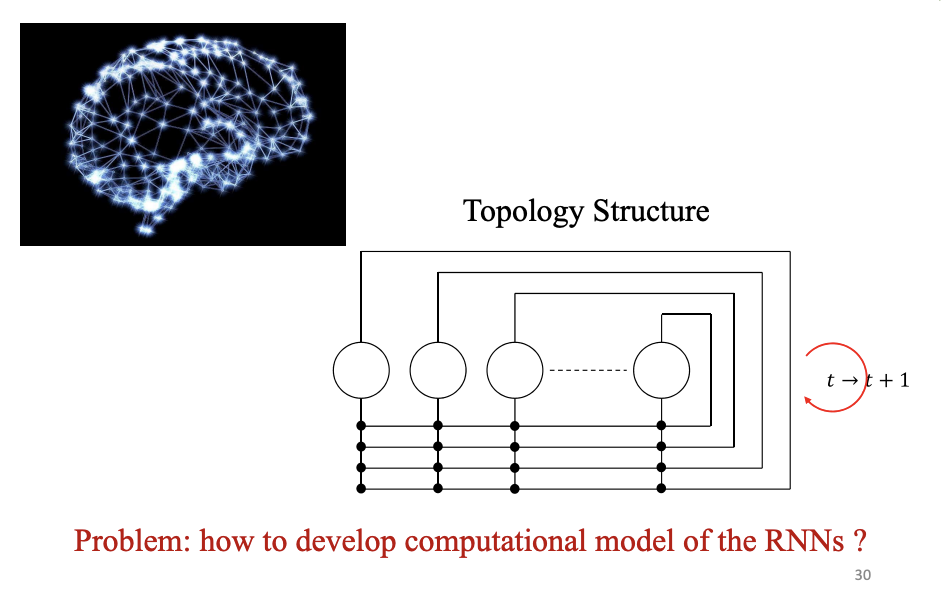
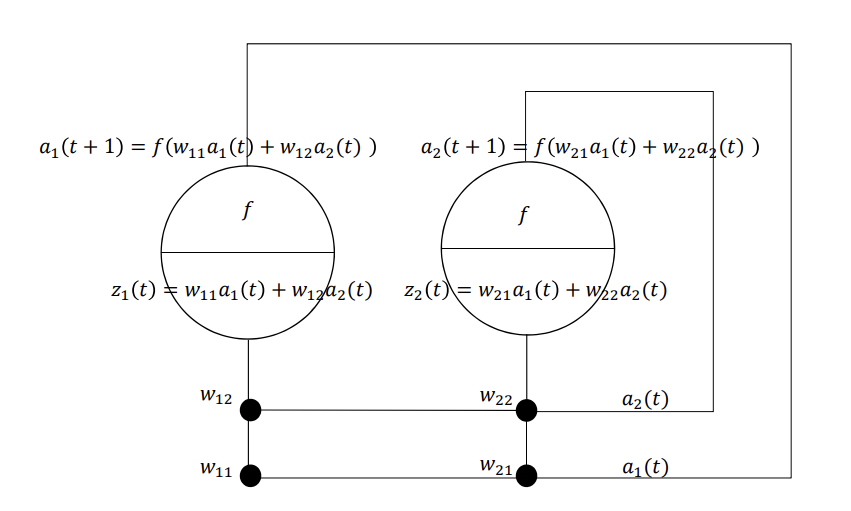
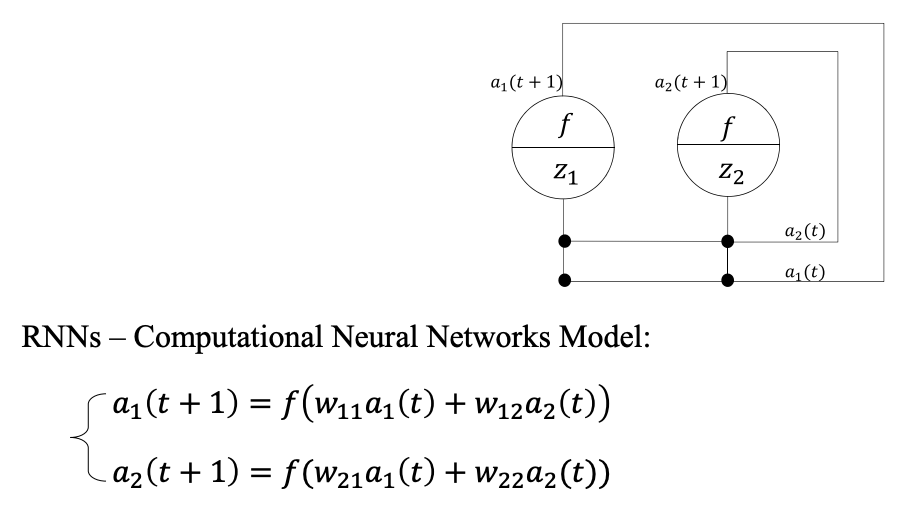
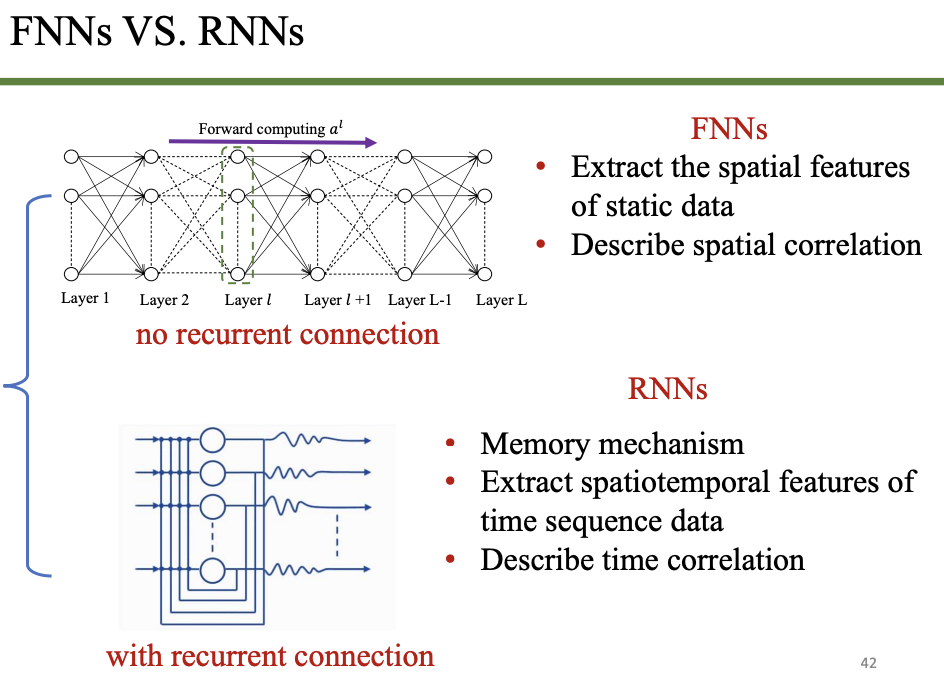
题目
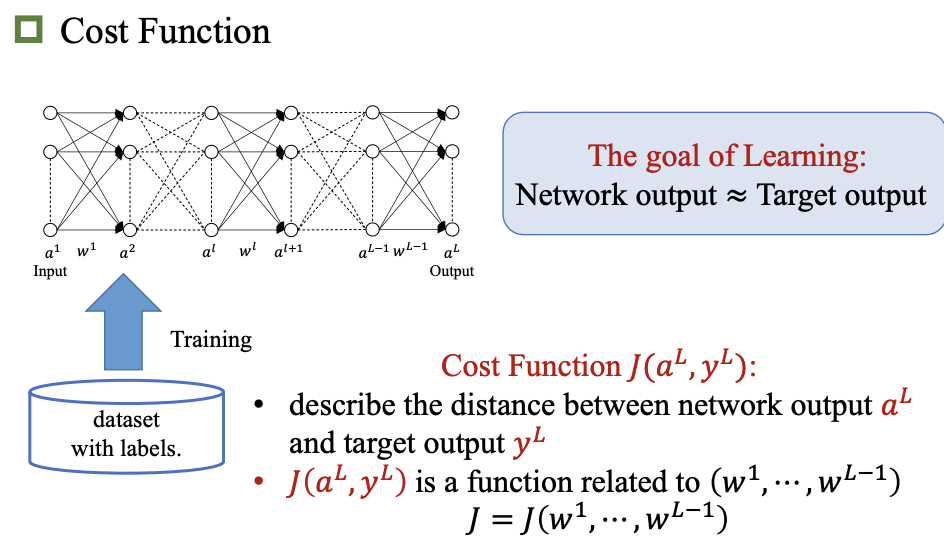
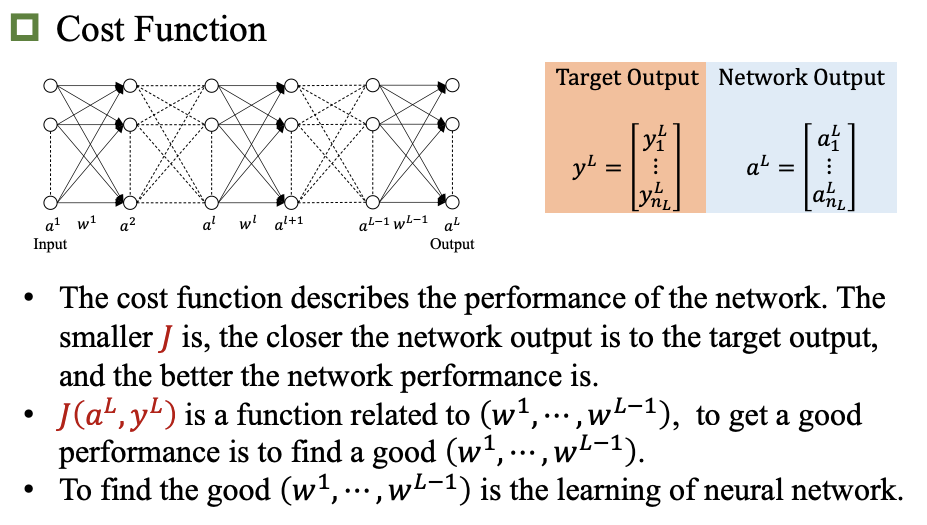
损失函数

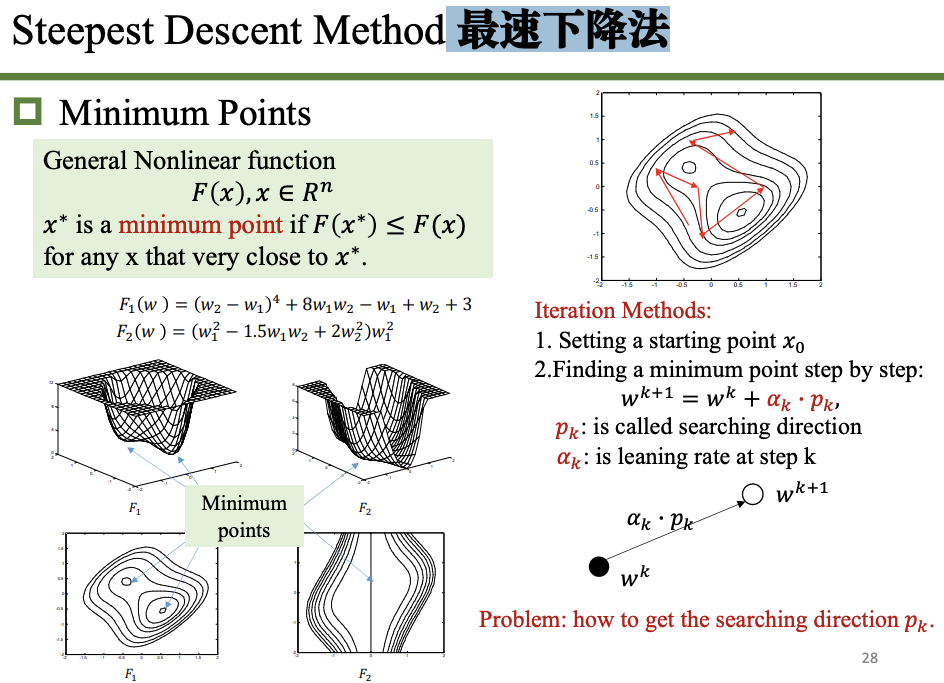
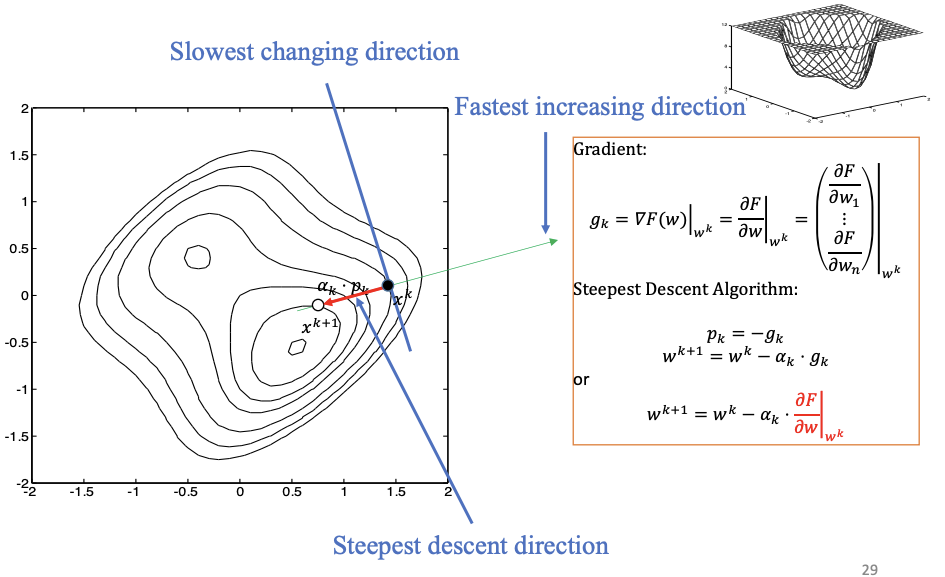
最速下降法
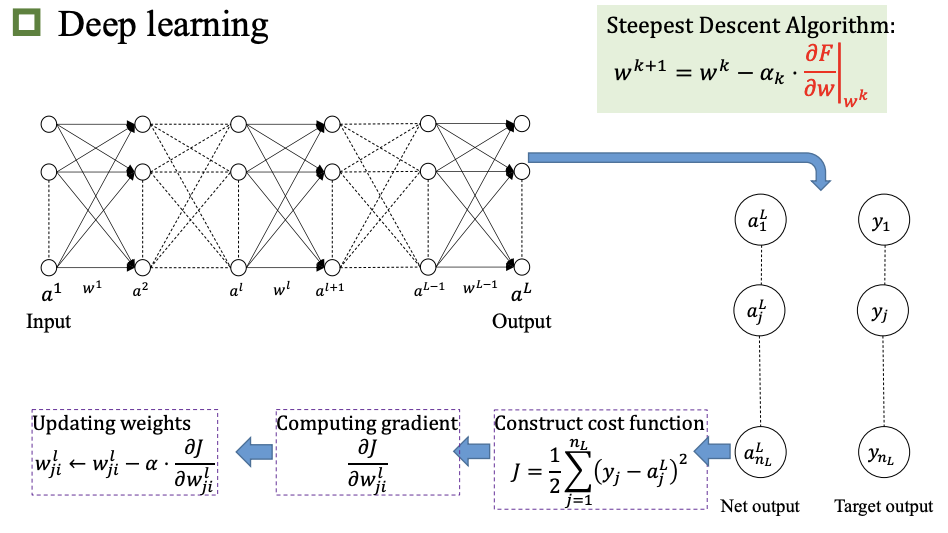
深度学习
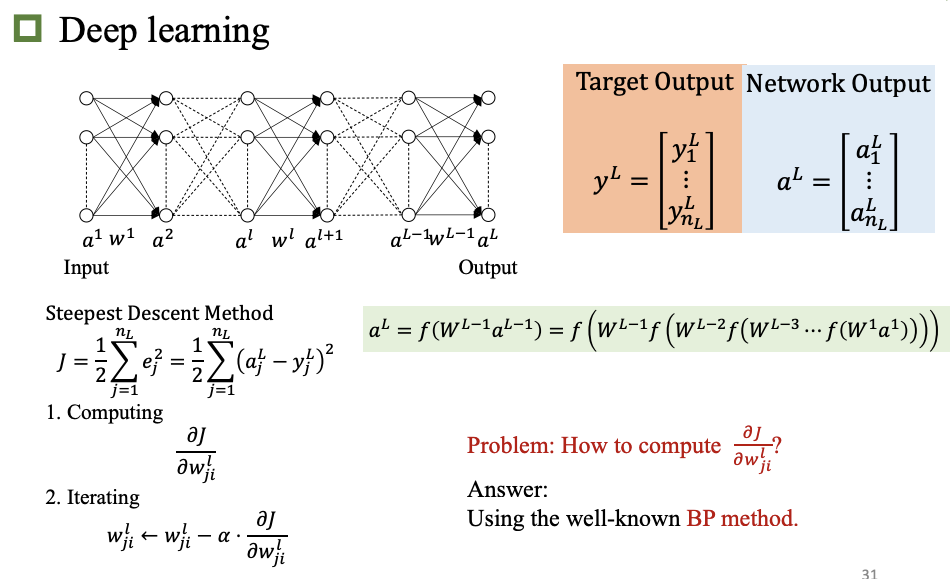
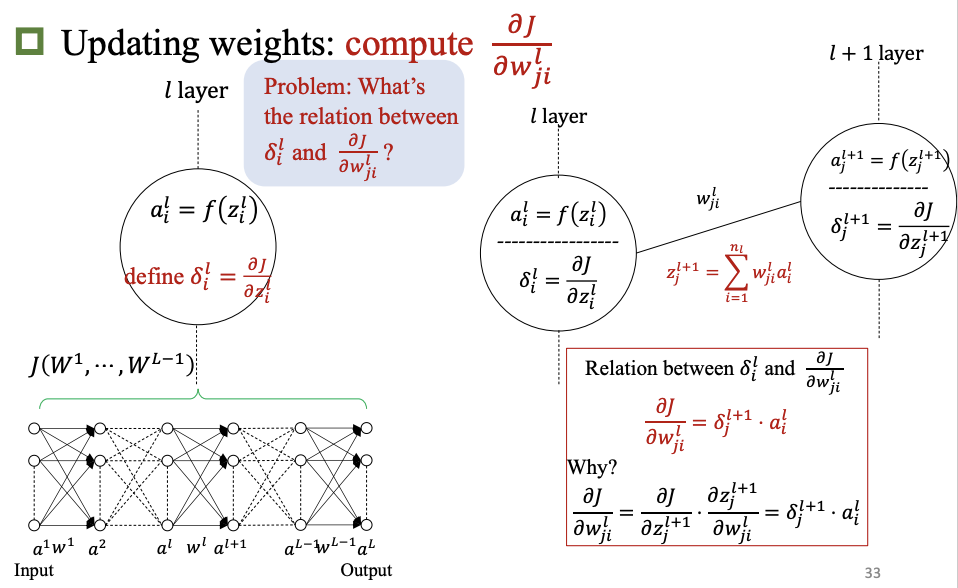
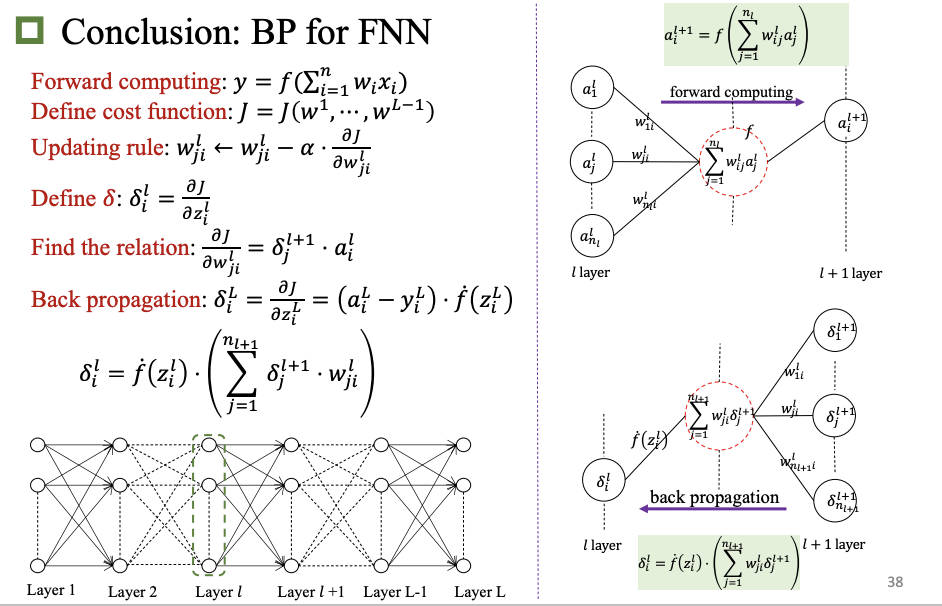
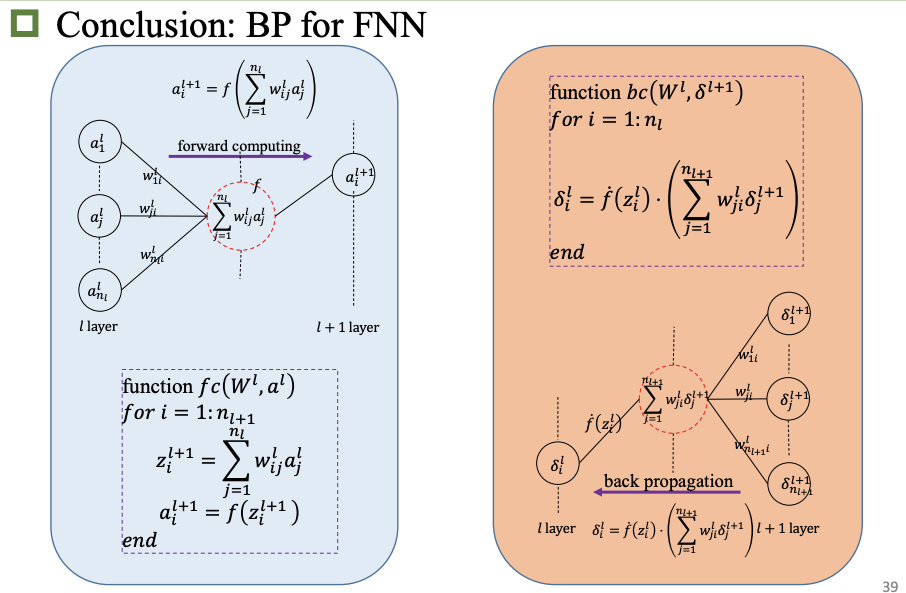
反向传播
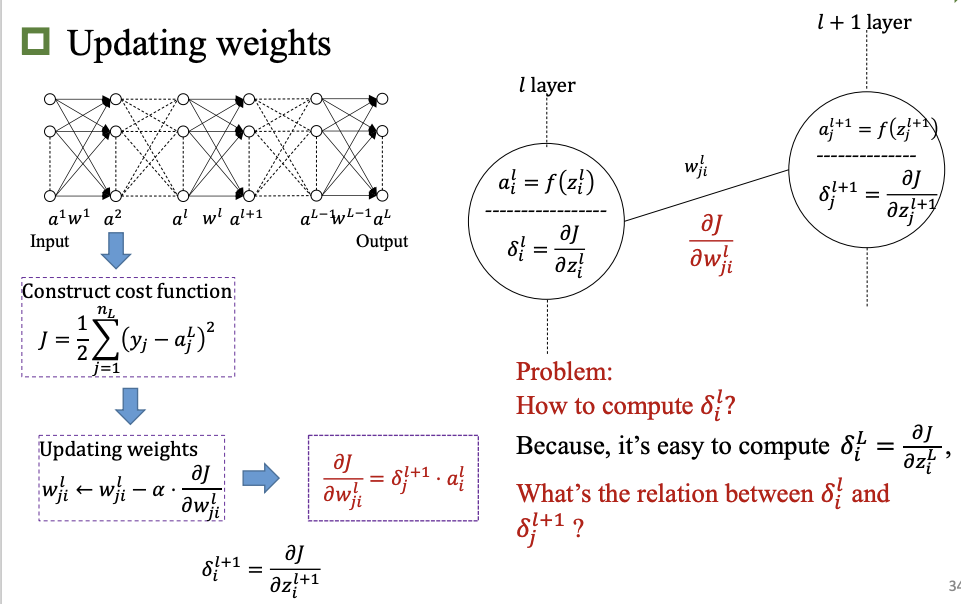
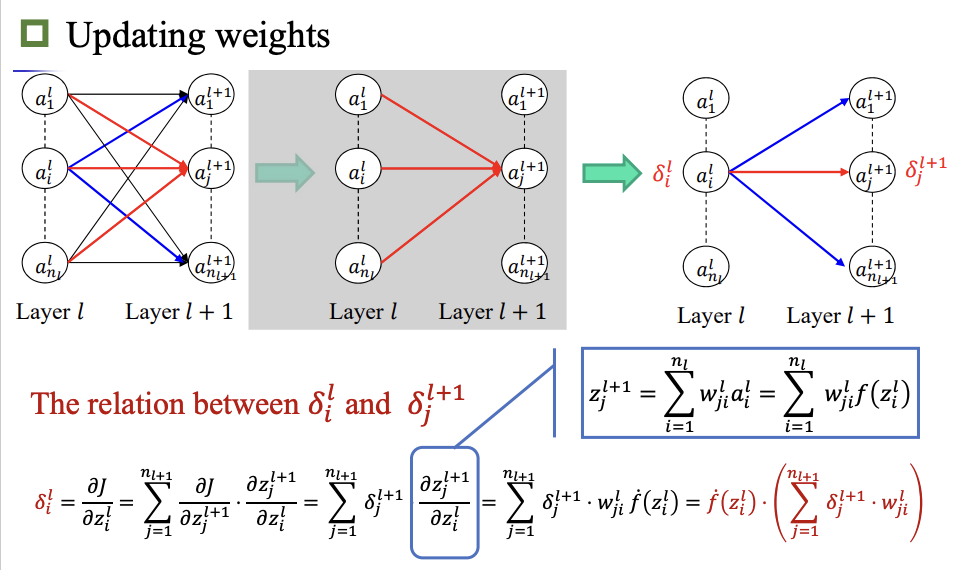
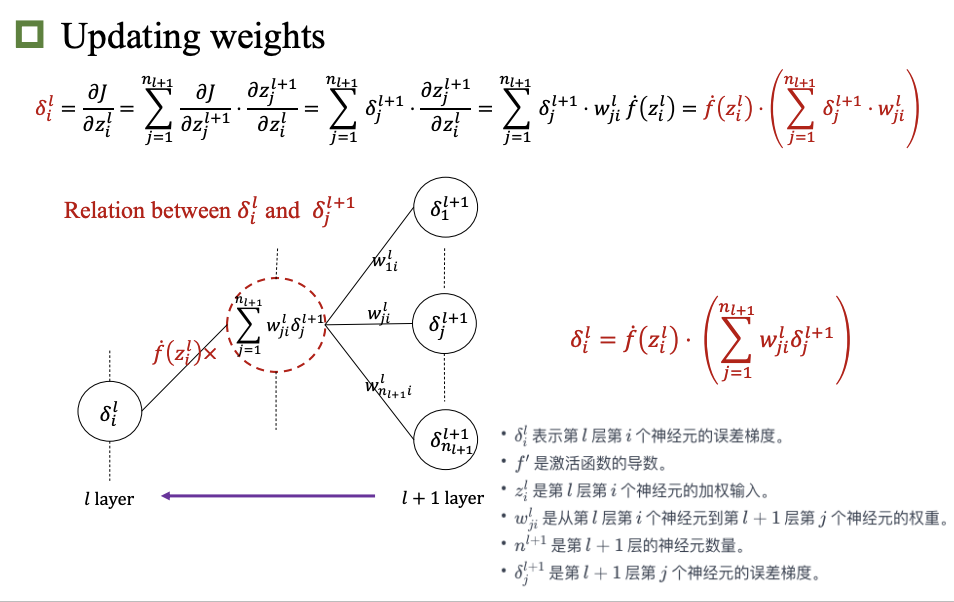
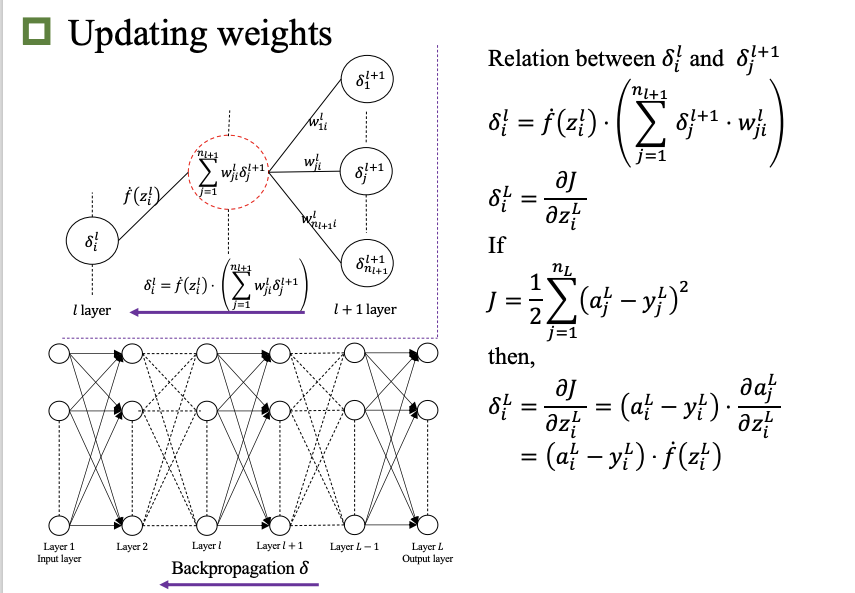
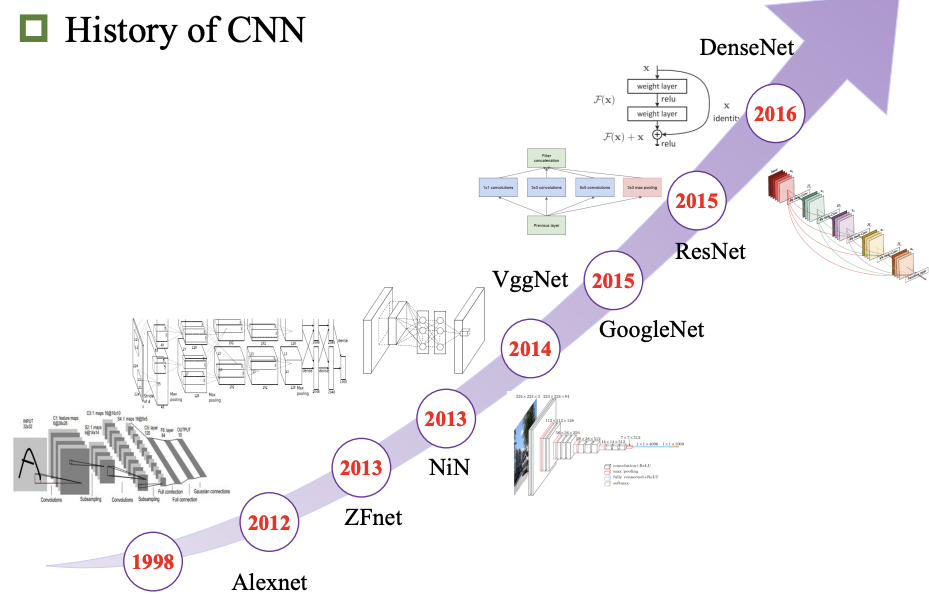
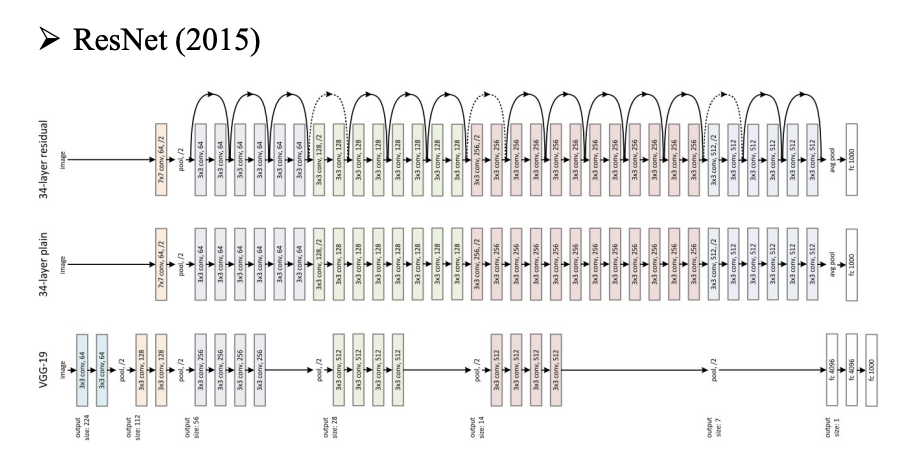
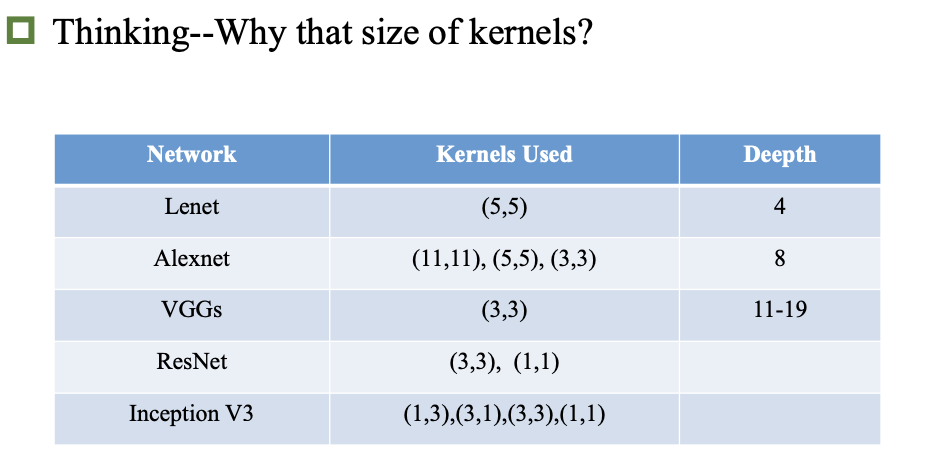
卷积神经网络
历史
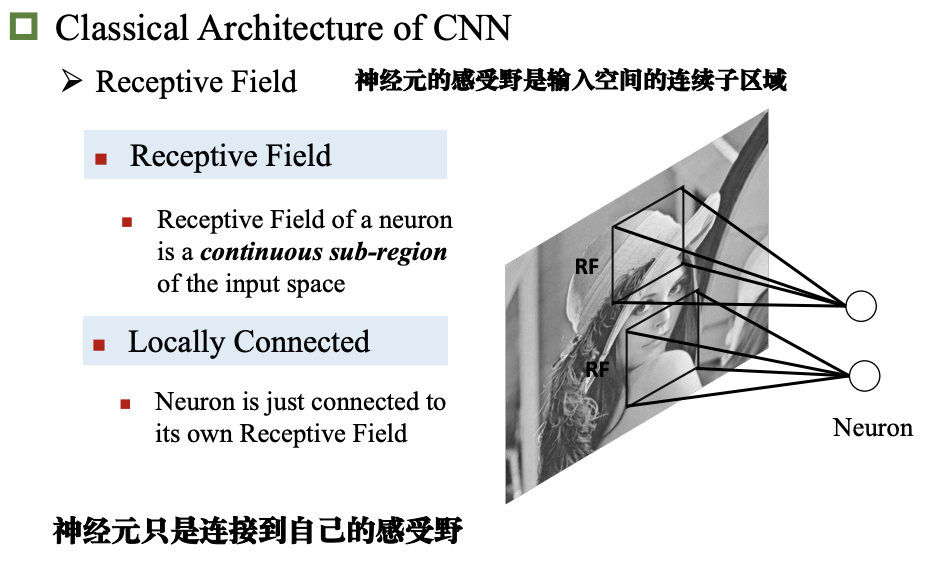
感受野
特征图
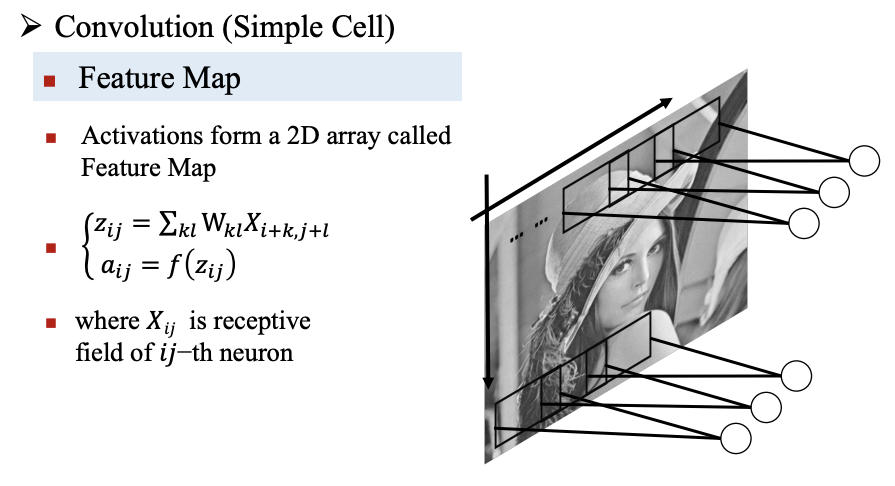
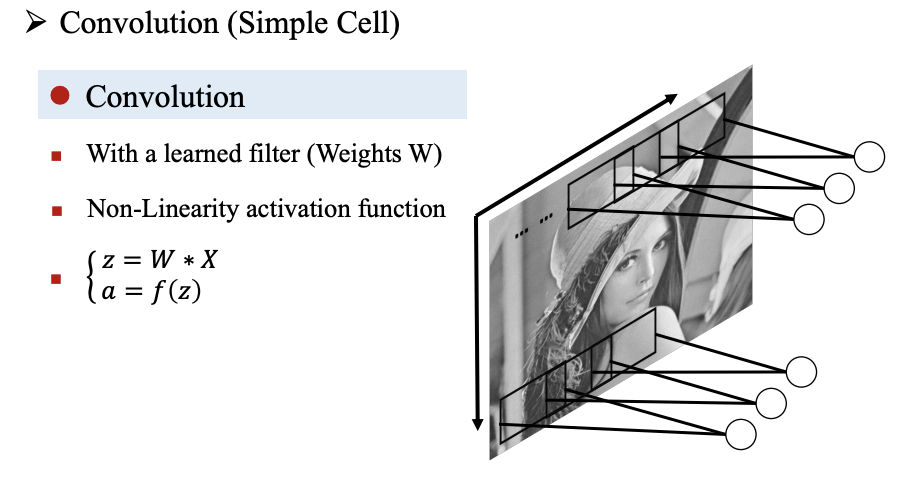
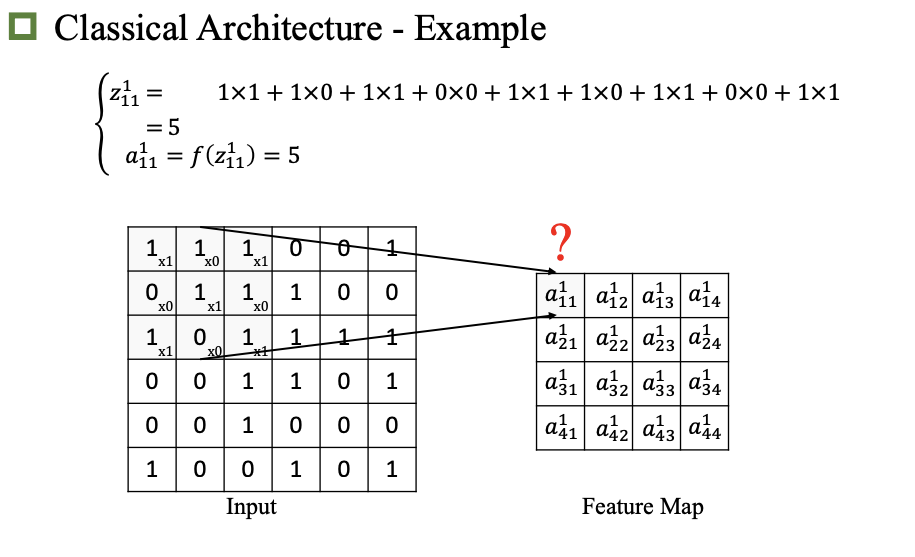
卷积
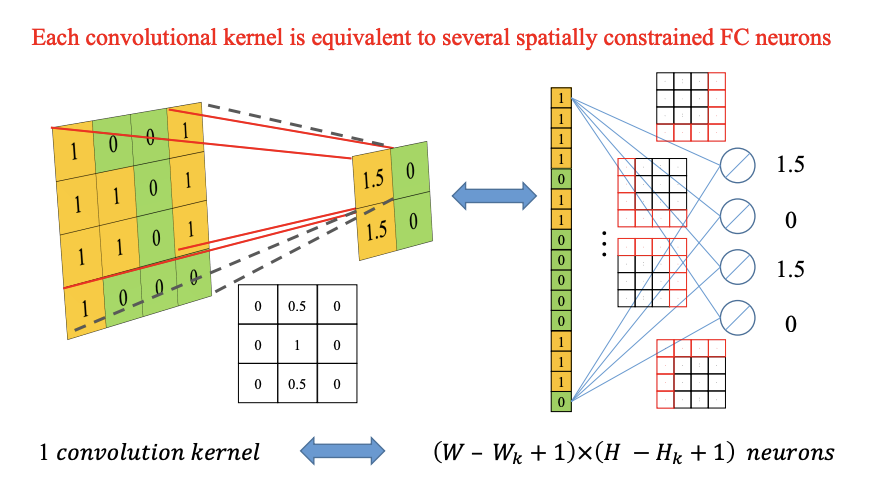
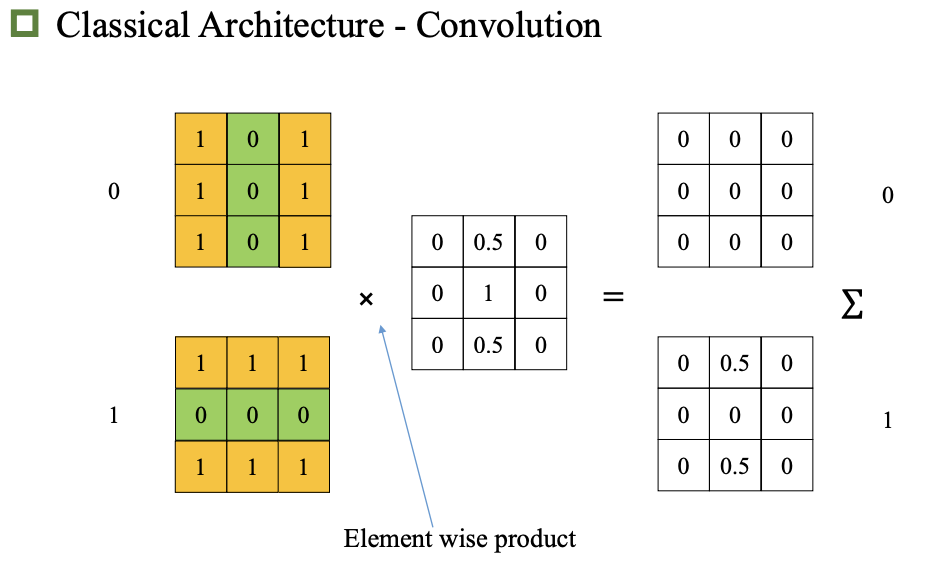
题目
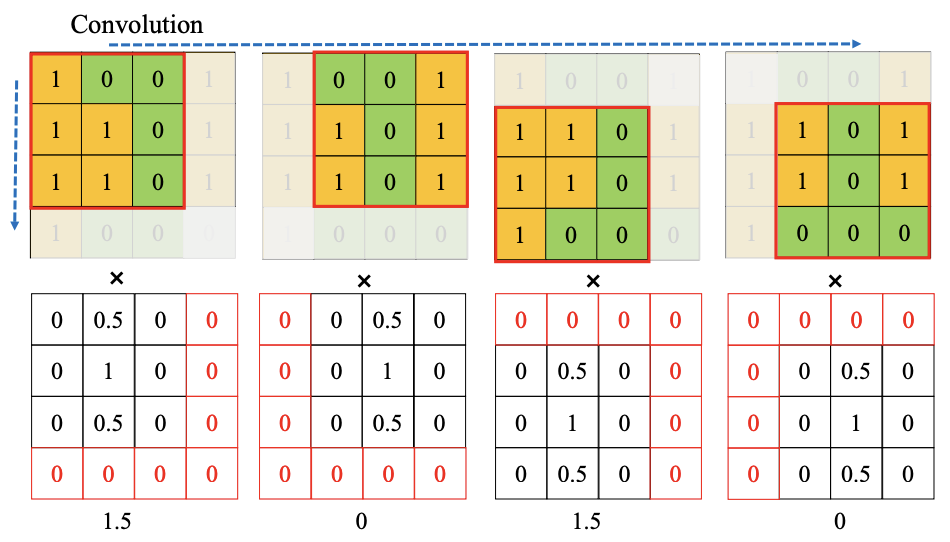
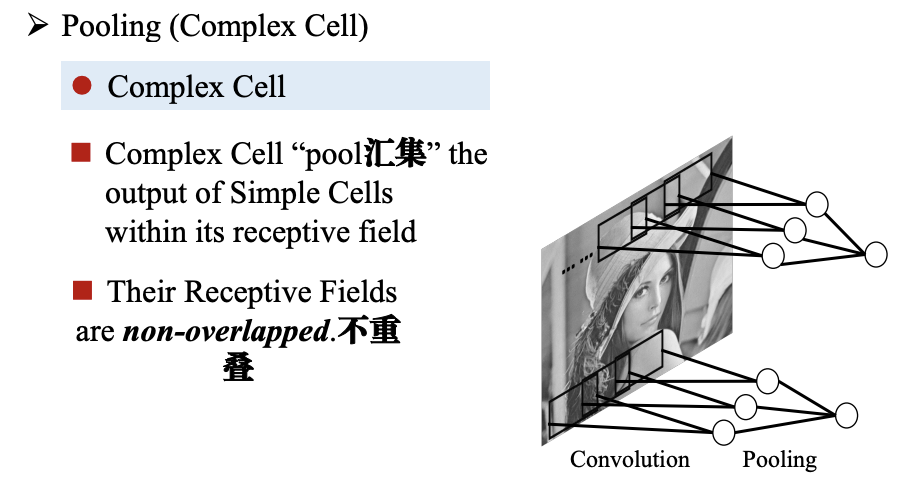
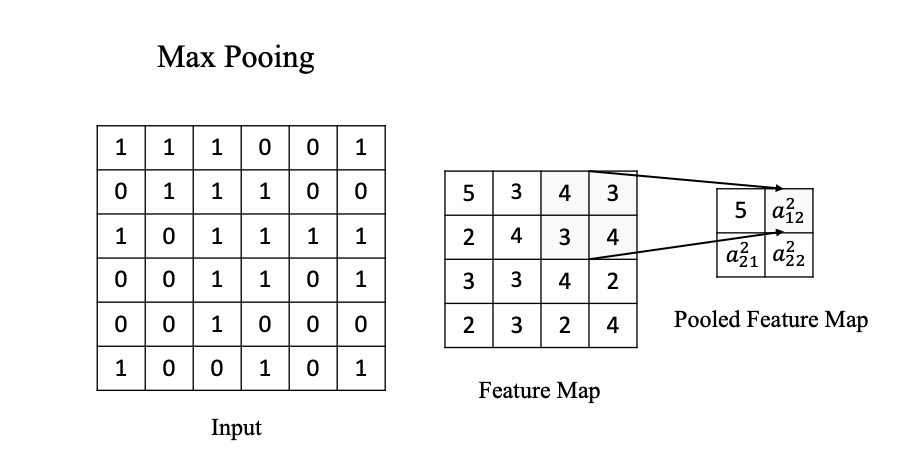
池化
题目
成就和应用
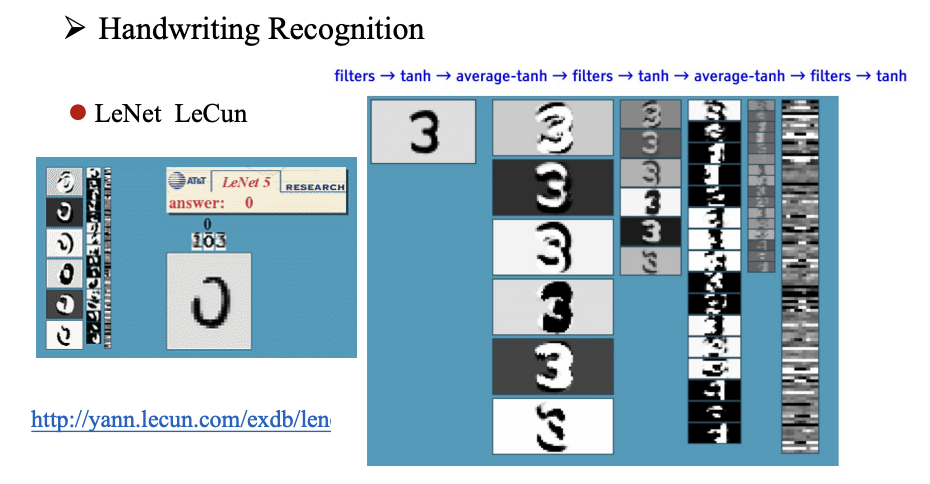
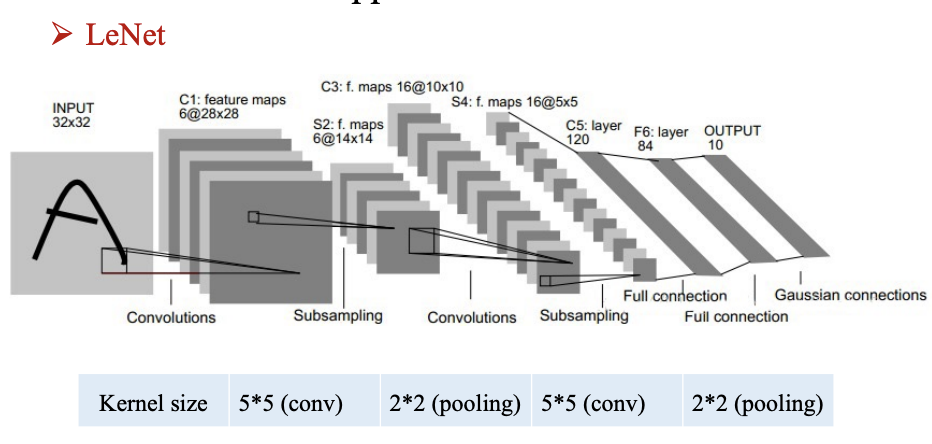
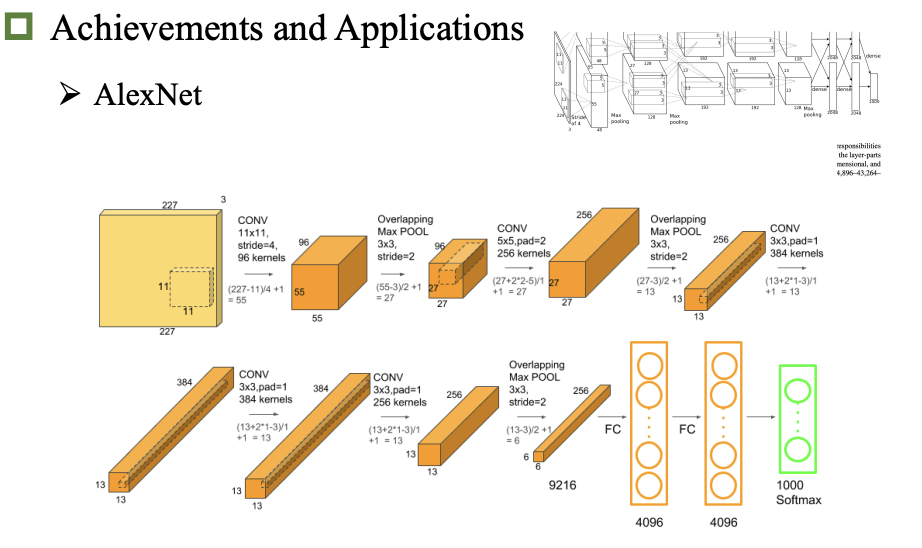
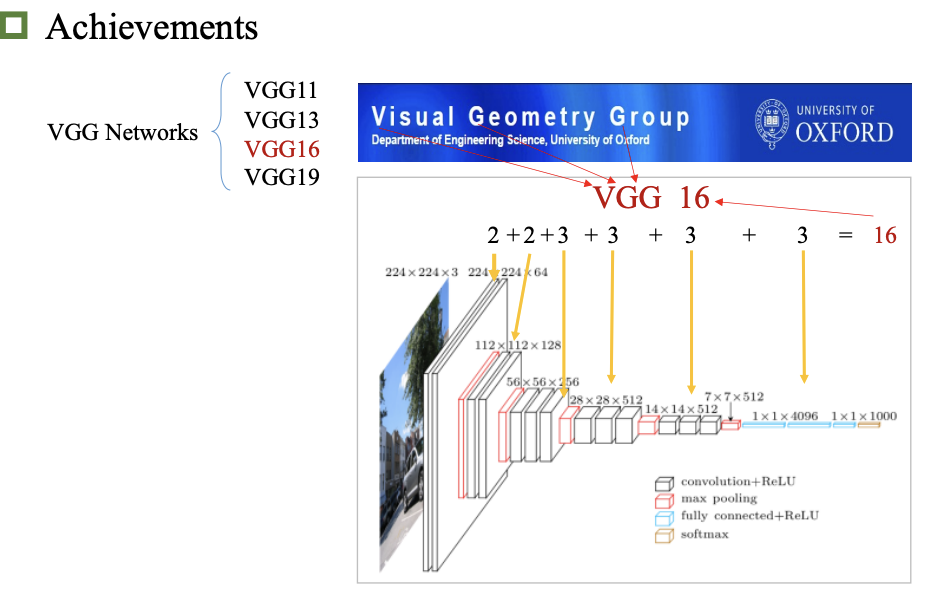
题目

序列学习*
序列学习(Sequence Learning)是机器学习中的一个重要分支,专注于从序列数据中学习模式和结构。序列数据是指数据元素按特定顺序排列的数据,例如时间序列数据、文本、语音或者视频帧。序列学习的目标是理解这些数据的内在结构,并能够预测或生成新的序列。
主要类型
时间序列预测:用于预测未来的数据点,例如股票价格预测、天气预报等。
序列生成:生成与训练数据类似的新序列,如文本生成、音乐创作等。
序列分类:将序列数据分类到不同类别中,例如语音识别或情感分析。
序列标注:在序列的每个元素上进行分类,常用于诸如命名实体识别、词性标注等任务。
关键技术
递归神经网络(RNN):一种特别适用于序列数据的神经网络结构,能够处理任意长度的序列。
长短期记忆网络(LSTM):RNN的一种变体,通过特殊的结构解决了RNN长期依赖问题。
门控循环单元(GRU):与LSTM类似,但结构更简单,效果也很好。
Transformer:一种基于自注意力机制的模型,特别适用于大规模序列数据处理,如机器翻译。
卷积神经网络(CNN):虽主要用于图像处理,但也可用于处理序列数据,特别是在处理较短的序列时。
应用场景
- 自然语言处理:如机器翻译、文本摘要、情感分析等。
- 语音识别:将语音信号转换成文字。
- 视频分析:从视频序列中识别特定事件或对象。
- 股票市场分析:预测股票价格变化。
- 生物信息学:如蛋白质结构预测。
挑战
- 长期依赖问题:在处理长序列时,传统模型(如RNN)难以记住早期信息。
- 资源消耗:特别是对于大规模模型(如Transformer),需要大量的计算资源。
- 数据质量和可用性:高质量、标注良好的序列数据并不总是可用。
序列学习是一个快速发展的领域,随着新技术的出现,其应用范围和效果都在不断提升。