高级网络 期末复习
University of Bristol
EEMEM0010 Advanced Networks
Final Review
Msc Internet of Things with AI 物联网与人工智能
布里斯托大学 2025 高级网络
所涉及版权归原作者所有
The copyrights involved belong to the original author
Program Link: https://www.bris.ac.uk/unit-programme-catalogue/UnitDetails.jsa?ayrCode=24%2F25&unitCode=EEMEM0010
其他相关课程:EENGM4211 Advanced Networks, EENGM0008 Data Center Networking
考前记忆
802.15.4: 250kbps, 2.4Ghz, 最大帧127B |
资源受限网络
Resource-Constrained Networking
无线传感器网络 WSN
Wireless Sensor Network
传统 WSN
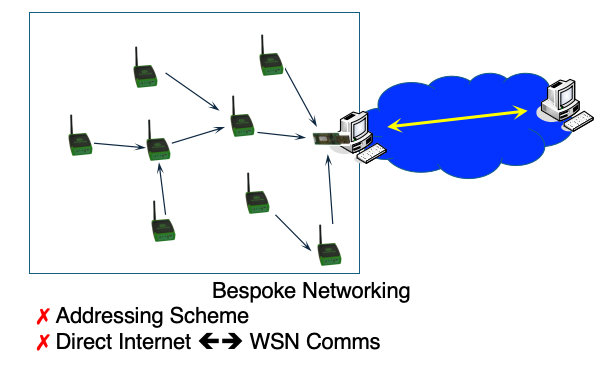
是 Bespoke Networking 定制网络
不遵循IP协议,无法直接与互联网连接
6LoWPAN
后文有详细介绍
IPv6 over Low-power, Wireless PANs 低功耗无线个人局域网上的 IPv6
由于数量原因,嵌入式设备需要使用IPv6 而不是v4
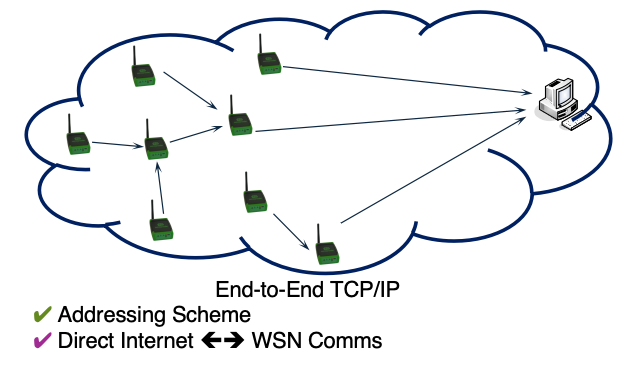
- 支持寻址、直接连接互联网
IEEE 802.15.4
802.15.4 PHY
- 极低功率
- 250Kbps
- 2.4GHz, 16 信道 (numbered 11…26)
802.15.4 MAC
- 无连接
- 最大帧长 127B
- 使用 ACK
- Distributed operation
- CRC-16 差错检测(CRC-32 in .15.4g)
- 低功耗运行:TSCH:Time Slotted Channel Hopping,时隙信道跳变
EUI-64 地址
EUI-64 是一种 64 位设备唯一标识符(地址)
长度为 8 字节 (普通 MAC 是 6 字节)
例如:00:12:4b:00:18:75:69:a5, ff:ff:ff:ff:ff:ff:ff:ff
或写作: 0012.4b00.1875.69a5
全 1 表示广播地址
可用 ff:ff (短地址模式)表示广播

UAA — Universally Administered Address 全局管理地址,出厂自带
LAA — Locally Administered Address 本地管理地址,由管理员自行设置
看第一个字节的第 2 个最低有效位来区分UAA和LAA,0表示U,1表示L
00:1A:2B:xx:xx:xx:xx:xx → 0000 0000 → UAA
02:1A:2B:xx:xx:xx:xx:xx → 0000 0010 → LAA
EUI-64 帧
EUI-64 帧最大长度为 127 字节(就是 802.15.4 MAC 最大帧长)
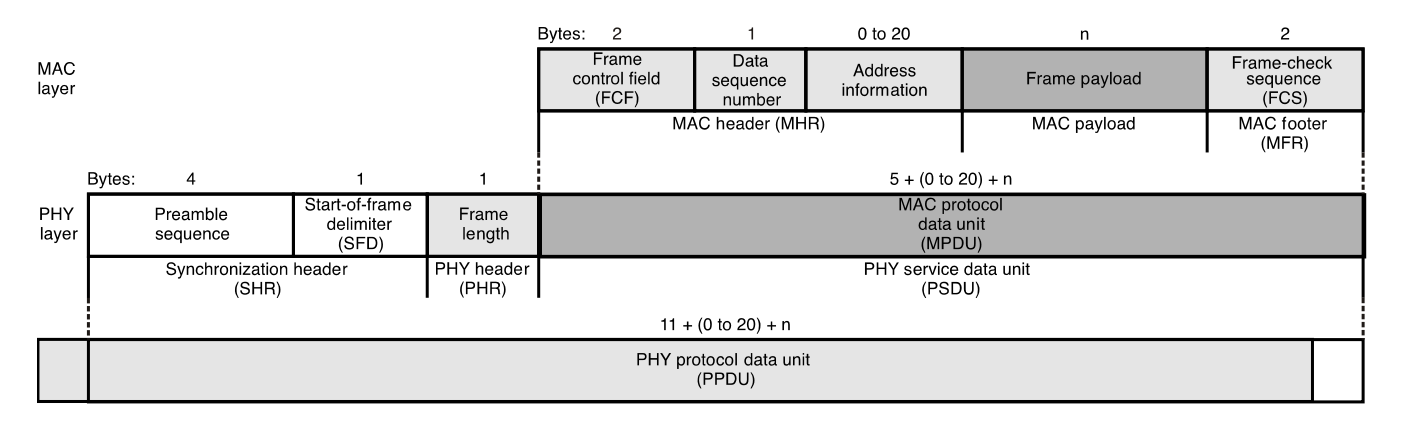
Address infomation 字段:描述 Addressing fields(寻址字段)的格式,可变长度,0 - 20字节
Addressing fields (寻址字段): 可变长度,包含 4 个子字段
目的 PAN ID:0 或 2 字节
目的地址:0、2 或 8 字节
源 PAN ID:0 或 2 字节
源地址:0、2 或 8 字节
低功耗运行
Low-Power Operation
无线电占空比
Radio Duty-Cycling
E.g. 10% radio duty cycle == radio is active 10% of the time
由于占空比,两设备若要进行通信,须同时处于唤醒状态
Asynchronous 方式
Sender-Initiated 发送端发起
发送方反复发送数据包,直到接收方响应
接收器定期唤醒,检查传入的数据包。Receiver-Initiated 接收端发起
接收器定期发送 beacons 信标信号 以表明其可用性。
发送方监听信标信号,并在信标信号到达后发送数据包。
缺点:空闲监听的开销
Synchronous 方式
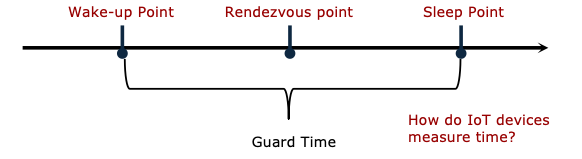
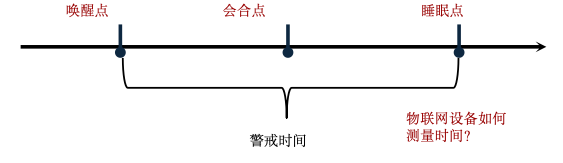
警戒时间会增加无线电的占空比(空闲监听)
物联网设备使用硬件时钟,由晶体/RC振荡器(Oscillator)提供信号。
时钟会漂移(drift)(振荡器存在误差,即使理论上相同)
Eg. 802.15.4 参数
Q: What is the default bitrate of IEEE 802.15.4 when operating at the 2.4GHz band?
A: 250kbps
Q: How much time does it take to transmit 1 byte?
A: 1B / 250kbps = 32 微秒 (μs)
Q: How much time does it take to transmit a frame of max length?
A: 127B / 250kbps = 4.064 ms
最大帧长为 127 B
Eg. Q=I*t, E=Pt
| MCU State | Current |
|---|---|
| MCU Active (Running @48 MHz) | 3 mA |
| MCU Sleeping (Paused) | 0.5 mA |
| MCU Off | 3 µA |
| RF State | Current |
|---|---|
| RF RX | 6 mA |
| RF TX – −5 dBm output power | 9 mA |
| RF Off | 0 µA |
Assume a System-on-Chip (SoC) with an integrated MCU and RF transceiver and the power consumption characteristics shown in the table
Q: How much charge is consumed to transmit 125 bytes?(MCU is Sleeping while the RF is TXing)
A: t = 125 B / 250kbps = 4ms; Q = I x t, 0.5mA 4ms + 9mA 4ms = 38uC
默认传输速率为250kbps, 1k = 1000
Q: And how much energy is consumed?(Assume a supply voltage of 3V)
A: E = P t = U I t = Q U = 38uC * 3V = 114uJ
时隙通信
Time-Slotted Communications
Dedicated / Contention-free 专用 / 无竞争
- 为各设备提前分配时隙
- IEEE 802.15.4 TSCH 模式
Contention-based 竞争型
- 立即发送,冲突重传
信道跳变
Channel Hopping
发送端和接收端按照约定的伪随机(pseudo-random)模式切换信道
TSCH
Time-Slotted, Channel Hopping 时隙信道跳变
同步式 MAC 协议(全网时钟同步)
通信基于重复执行的调度表(schedule)
信道选择基于重复的跳变序列(hopping sequence)
优点:可靠、能耗可预测
缺点:加入网络的代价高、时间同步困难、复杂度高
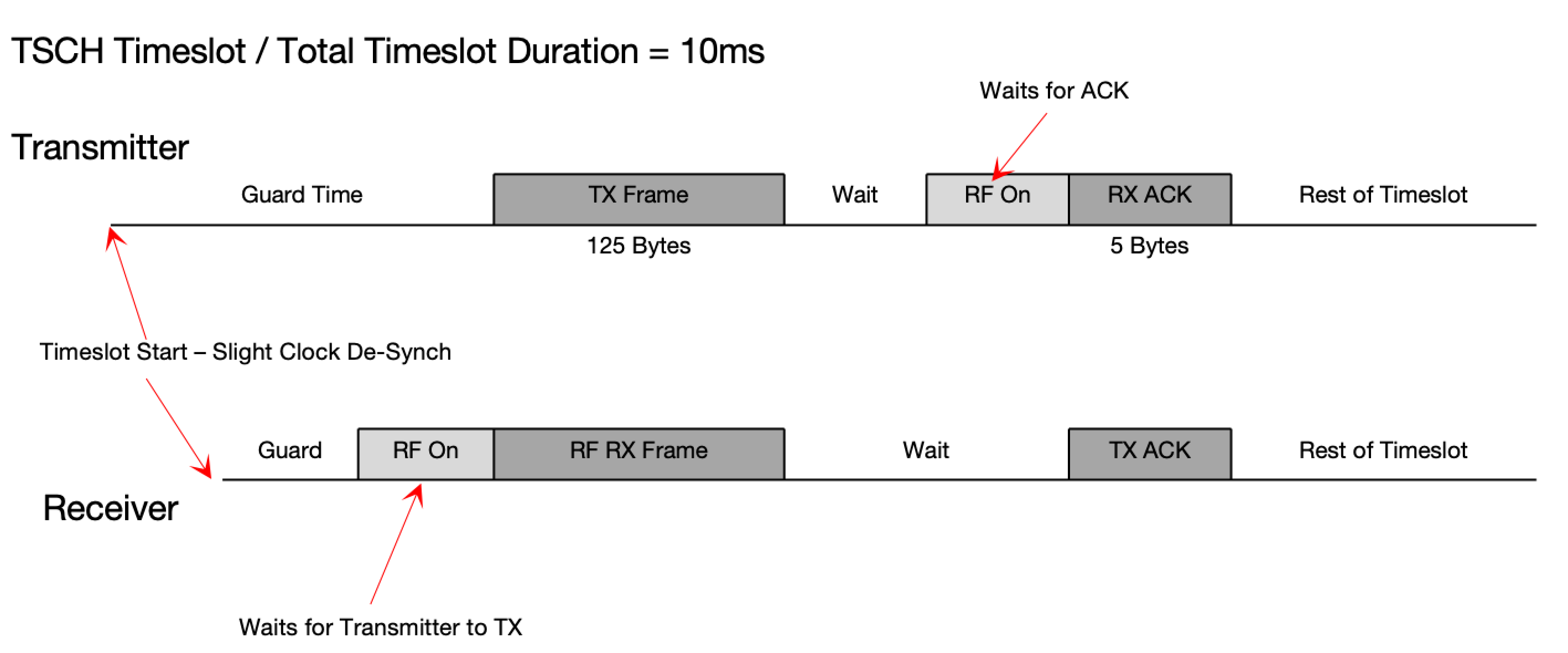
Timeslot Start – Slight Clock De-Synch 微小时钟偏移
RF On 表示打开射频 准备接收数据包
在一个 Timeslot 中要完成以上操作。
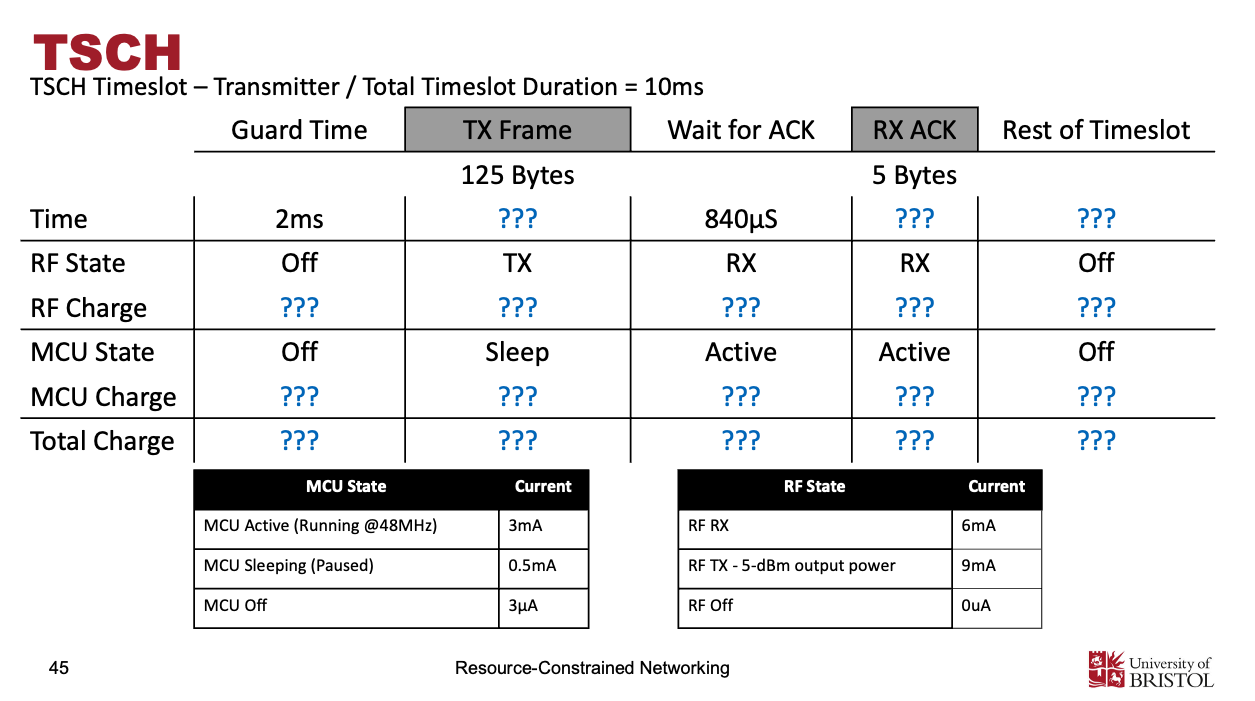
Eg. Q=I*t, E=Pt
| MCU State | Current |
|---|---|
| MCU Active (Running @48 MHz) | 3 mA |
| MCU Sleeping (Paused) | 0.5 mA |
| MCU Off | 3 µA |
| RF State | Current |
|---|---|
| RF RX | 6 mA |
| RF TX – −5 dBm output power | 9 mA |
| RF Off | 0 µA |
TSCH Timeslot – Transmitter (Total Timeslot = 10 ms)
| 项目 / 阶段 | Guard Time | TX Frame | Wait for ACK / RX ACK | Rest of Timeslot |
|---|---|---|---|---|
| 时长 (Time) | 2 ms | 4 ms | 840 µs + 160 µs | 3 ms |
| 大小 | 125 B | 5 B | ||
| RF State | Off | TX | RX | Off |
| RF Charge | 0 C | 36 µC | 6 µC | 0 |
| MCU State | Off | Sleep | Active | Off |
| MCU Charge | 6 nC | 2 µC | 3 µC | 0.009 µC |
| Total Charge | 6 nC | 38 µC | 9 µC | 0.009 µC |
| Energy (3 V) | 114 µJ |
IPv6
128 bits = 16 Bytes.
2001:0db8:85a3:0000:0000:8a2e:0370:7334
- Unicast 单播
- Anycast 任播
- anycast = 多个节点共享同一个 unicast 地址,路由至最近的节点
- 无法从地址形式区分 Unicast 和 Anycast
- 例:DNS 服务器
- Multicast 组播(多播)
- 发送到组播地址的数据报会被所有属于该组的接口接收
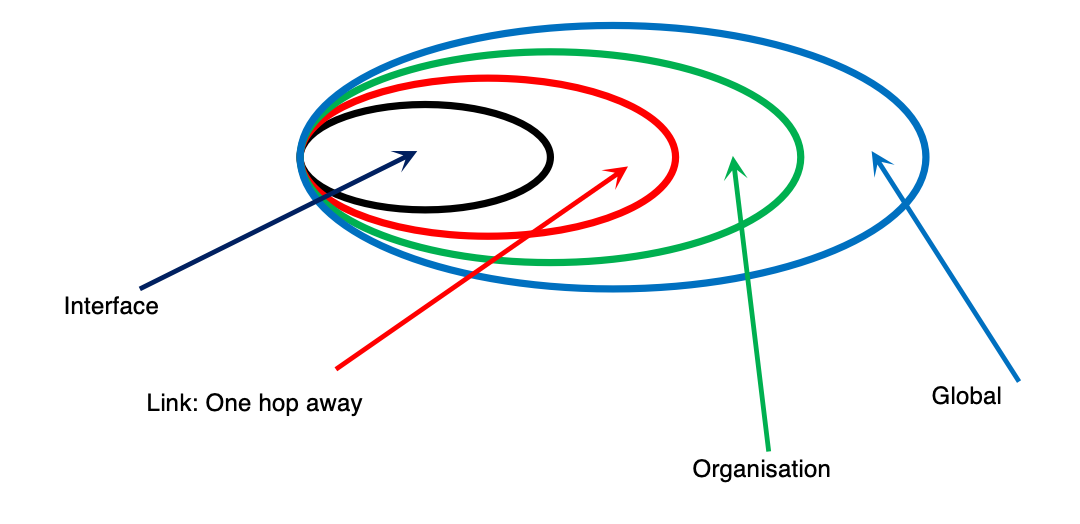
作用域
Scope
Link-local:一跳内有效,不被路由
Global(or Universal):全网有效,全球路由


SLAAC ※
应用SLAAC时,第一个字节的倒数第二位(U/L位)一定会发生反转
SLAAC 就是通过 8 字节 EUI64 或 6 字节 MAC 地址 生成 IPv6
MAC地址转换为 EUI64时,在中间插入
FF:FE
StateLess Address Auto-Configuration,无状态地址自动配置
设备使用 SLAAC 为自身接口生成 IPv6 单播地址
接口ID(Interface ID) 由 EUI-64 生成
(或由 EUI-48 / MAC-48 转换为 EUI-64 后生成)
U/L 位(Universal/Local)的语义被反转:
- 0: 现在表示 本地(local)
- 1: 现在表示 全局(universal)
SLAAC 可用于生成 链路本地地址(link-local) 和 全局地址(global)
Eg. SLAAC
直接由 EUI-64 生成
| 项目 | 内容 |
|---|---|
| EUI-64 | 00:12:4B:00:18:75:69:A5 |
| 链路本地地址(Link-local) | fe80::212:4b00:1875:69a5 |
| 全局地址(前缀 2001:db8:85a3::/64) | 2001:db8:85a3::212:4b00:1875:69a5 |
由 48 位 MAC 地址转换为 EUI-64 后生成
| 项目 | 内容 |
|---|---|
| MAC 地址(EUI-48) | 00:0C:29:0C:47:D5 |
| 转换为 EUI-64:在中间插入 FF:FE | 00:0C:29:FF:FE:0C:47:D5 |
| 链路本地地址(Link-local) | fe80::20c:29ff:fe0c:47d5 |
| 全局地址(前缀 2001:db8:85a3::/64) | 2001:db8:85a3::20c:29ff:fe0c:47d5 |
组播作用域 ※
所有 IPv6 多播(组播)地址都以 ffxy 开头
| 地址 | 作用域(Scope) | 备注 |
|---|---|---|
| ff00::/16 | 保留(Reserved) | — |
| ff0f::/16 | 保留(Reserved) | — |
| ffx1::/16 | 接口本地(Interface-local) | 不能在任何网络链路上传送。这是单播回环地址的多播等价形式 |
| ffx2::/16 | 链路本地(Link-local) | 不能被路由;仅限单跳内的设备使用。重要:需要记住 |
| ffx3::/16 | 域本地(Realm-local) | 仅供参考 |
| ffx4::/16 | 管理本地(Admin-local) | 需要通过管理方式配置的最小作用域 |
| ffx5::/16 | 站点本地(Site-local) | 限制在本地物理网络内 |
| ffx8::/16 | 组织本地(Organization-local) | 限制在组织所管理的网络范围内 |
| ffxe::/16 | 全局(Globa) | 可在公共互联网中路由。重要:需要记住 |
Eg. IPv6 缩写
IPv6 最短文本表示规则:
省略前导零:在每个 16 位的字段中,都去掉前导
0(例如0db8变为db8,0000变为0)。双冒号 (
::) 替换:用::替换一组或连续多组全为0的字段。注意:在一个地址中::只能出现一次。 如果有两处可以压缩,通常压缩最长的那一段;如果长度相同,压缩第一段。
原始: 2001:0db8:0001:0000:0000:0100:0370:00be
最短形式: 2001:db8:1::100:370:be
原始: 2001:0db8:0000:0000:0001:0000:0000:000e
最短形式: 2001:db8::1:0:0:e
(注意:中间有两段连续 0000,只能压缩一段)
原始: ff02:0000:0000:0000:0000:0000:0000:0001
最短形式: ff02::1
原始: fe80:0000:0000:0000:0000:0002:0370:00be
最短形式: fe80::2:370:be
Eg. SLAAC
已知
- EUI-64:
9C:8E:99:00:00:C0:FF:EE - Prefix:
2001:db8:1:2::/64
应用 SLAAC,求 Link-Local 和 Global 地址
翻转 U/L 位(第 7 位)
9C = 10011100 → 10011110 = 9E
接口 ID 变成:
9E:8E:99:00:00:C0:FF:EE |
压缩成 IPv6 形式:
9e8e:9900:c0:ffee |
Link-local
FE80::9E8E:9900:C0:FFEE |
Global
2001:db8:1:2:9E8E:9900:C0:FFEE |
Eg. 判断IP作用域
ff= multicast
ff02= multicast + link-local
ff0e= multicast + global
2000::/3= unicast + global (典型公网 IPv6)
fe80::/10= unicast + link-local (典型本地 IPv6)
2001:db8:1::100:370:be
- 分类: Unicast (单播)
- 范围: Global (全局)
- ff02::1
- 分类: Multicast (组播) (ffxy)
- 范围: Link-Local (链路本地) (4th char is 2)
- fe80::2:370:be
- 分类: Unicast (单播)
- 范围: Link-Local (链路本地) (starts with FE80)
Eg. 组播最短路径源树*
来源:EENGM4211 - 2023 Q5
*可能不属于考查内容
Q5: Consider the following graph. Assume that a multicast traffic source (S1) is connected to R1 and three multicast group members D1, D2, and D3 connected to R3, R7, and R5 respectively. What would be the shortest path source-based tree for the above-mentioned source/group? (8 Pts)
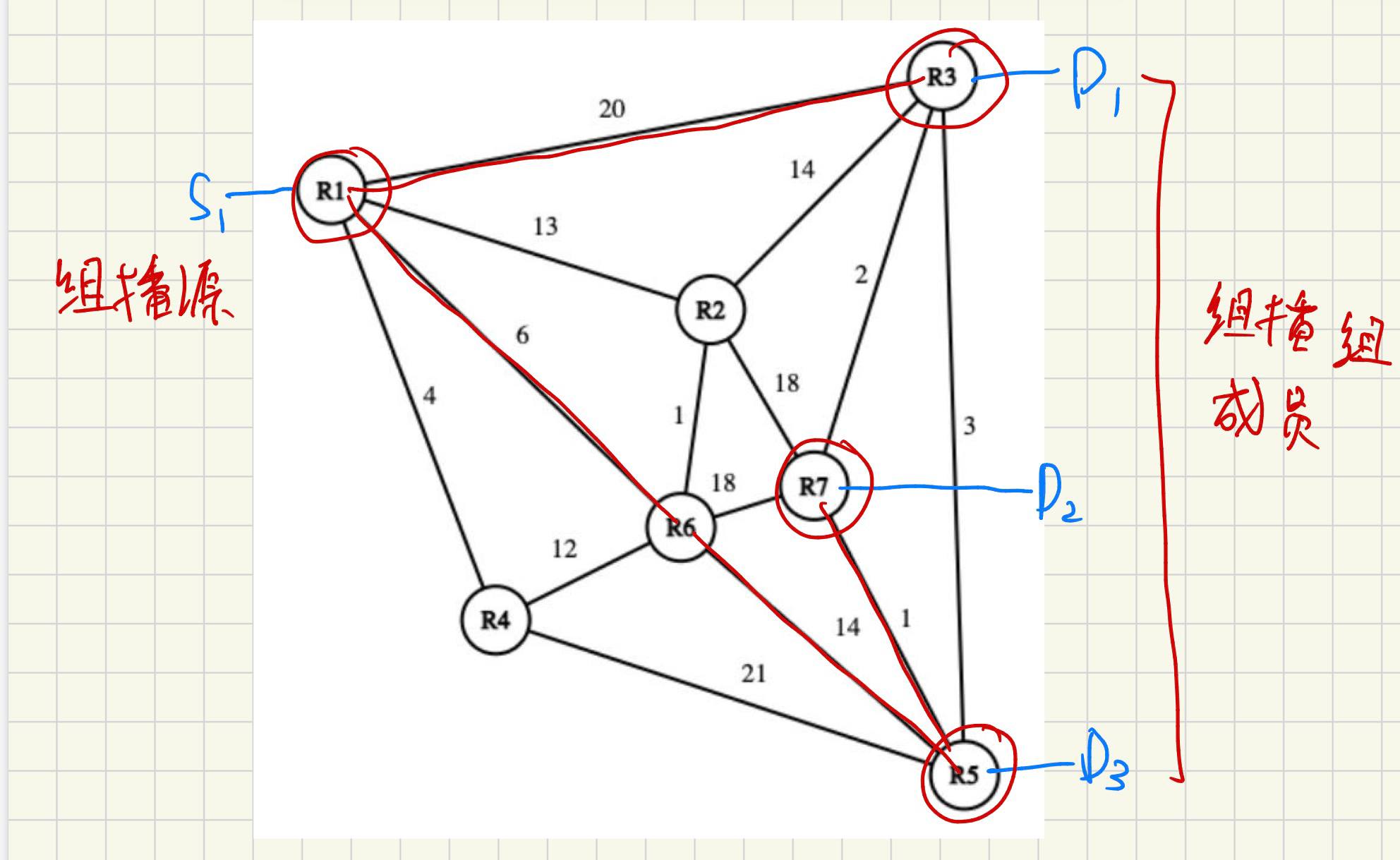
组播源 S1,分别到R3, R7, R5
最短路径为:
R1 → R3
R1 → R6 → R5
R1 → R6 → R5 → R7
因此最短路径源树包含这些边:
R1–R3
R1–R6
R6–R5
R5–R7
6LoWPAN
IPv6 over Low-power, Wireless Personal Area Networks(WPANs)
低功耗无线个域网上的 IPv6
IPv6 over 802.15.4
UDP头部太大,需要压缩
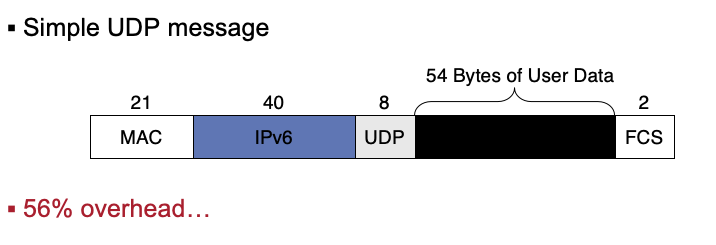
报头压缩
Header Compression
使用 6LoWPAN 适配层(adaptation layer)
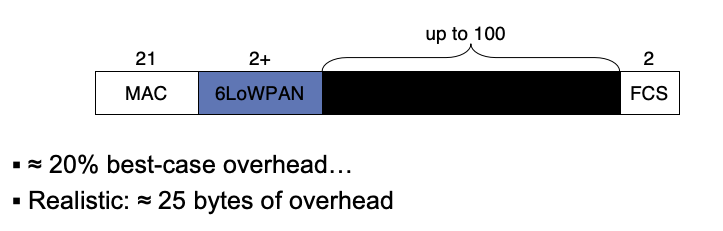
分派
Dispatch

- 6LoWPAN 报头以“01”开头,随后是“分派 (Dispatch)”字段:
分派/调度(Dispatch):
- 识别数据报使用的压缩算法
- 指定帧是否包含较大数据报的分片:
- FRAG1: 第一分片
- FRAGN: 后续分片
关键的Dispatch类型:
- 01 000001:IPv6 - 未压缩的 IPv6 地址
- 01 000010:HC1 - LOWPAN_HC1 压缩的 IPv6
- 01 1nnnnn:IPHC

IP头压缩 IPHC
IP Header Compression,IP 头压缩
压缩过程:
- 版本号 (Version) 压缩:永远是 6,移除
- 有效载荷长度 (Payload Length) 的压缩:可以从二层(链路层)的帧大小中推导出来,移除
- 流量类别(Traffic Class)与流标签(Flow Label): 引入 TF (Traffic Class - Flow Label) 标志位
- 如果
TF=11,流量类别、流标签全部省略(全为 0) - 其他取值(00, 01, 10)则保留部分信息
- 如果

字段的数值无需记忆,题目中会给出表格
下一个报头 (NH, Next Header):
NH=0:下一个报头(如 TCP/UDP)原样跟在 IPHC 后。NH=1:下一个报头也使用压缩编码。
跳数限制 ※ (HLIM, Hop Limit):
00:不压缩,原样携带(8 位)。01:Hop Limit = 1,无需携带任何信息,下同。10:Hop Limit = 6411:Hop Limit = 255
HLIM 只有 1、64 和 255 这三个特定数值有对应的压缩位(分别为
01,10,11)。其他情况都要原样携带。包每传输一次,HLIM 减一
如果 Hop Limit 在转发时从 64 变成 63,就不能再用 HLIM=10 压缩,需要 HLIM=00 并 inline 携带 63
看起来压缩效率很低(大多数情况下无法压缩),但很多 6LoWPAN 是一跳/本地通信,只要第一次压缩了就很不错

地址压缩
Address Compression
此部分最好结合课件复习
无状态地址压缩
Stateless Address Compression
无状态压缩适用于 链路本地 (Link-Local) 地址。对 IPv6 的 网络部分 (Network Part) 做出假设来简化地址。
链路本地地址的前缀通常固定(以
fe80::开头),传输时无需发送,接收方根据规则自动还原
单播地址 (Unicast):
Link-Local的网络部分始终为 64 位 且符合已知的模式:
fe80:0000:0000:0000。还可以对 主机部分 (host part) 做出假设:
fe80::0000:8a2e:370:7334
多播地址 (Multicast):
- 对高位字节(Most Significant Bytes)做出假设。
示例: 假设高 120 位 = ff02:<24 个零>:00 (即全部地址为 ff02::00XX)。
有状态地址压缩
Stateful (Context-based) Address Compression
前缀不是 Link-Local (fe80)时使用有状态压缩。
- 上下文示例:
fd00::/64 - 节点共享上下文(硬编码在固件中),最多支持 16 个 上下文
- 示例:节点共享:
- Context 0 =
fd00::/64 - Context 1 =
2001:db8:85a3::/48
- Context 0 =
- 不在数据包中包含完整上下文,而是包含上下文 ID (Context ID)。
源地址压缩 SAC
Source Address Compression
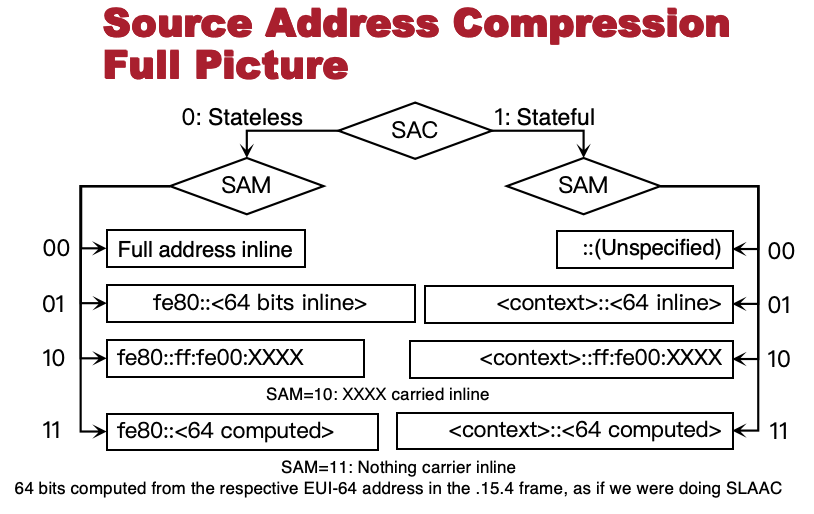
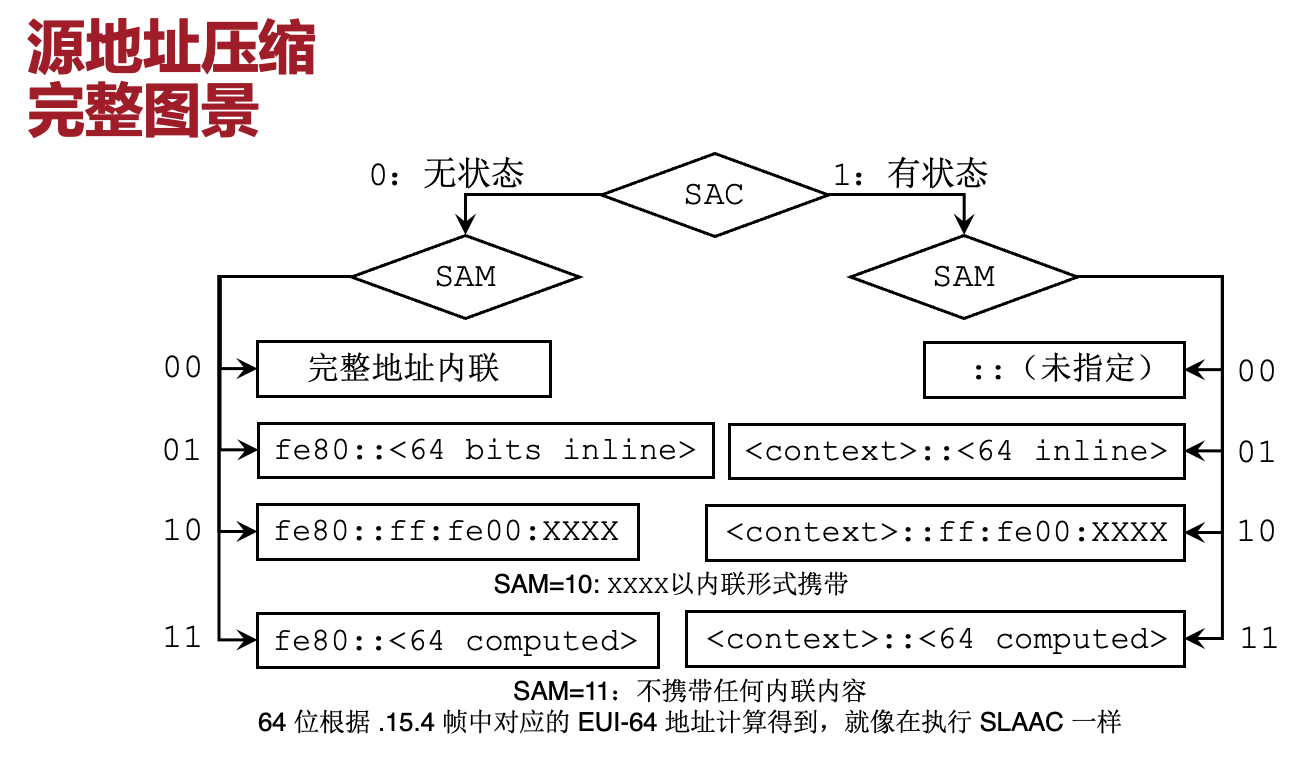
- 字段说明
SAC 源地址压缩方法:
- 0: Stateless(无状态)
- 1: Stateful(有状态)
SAM 源地址模式 (Source Address Mode): 地址中保留多少位在包内传输(Inline)。
- CID (Context ID): 有状态压缩时指示上下文ID。
- Stateless(无状态压缩) (SAC = 0)
根据 SAM 的取值,压缩程度逐级提升:
| SAM 取值 | 压缩效果 | 说明 |
|---|---|---|
| 00 | 无压缩 | 完整地址内联 Full address inline |
| 01 | 节省 64 位 | IP = fe80::内联64位 |
| 10 | 节省 112 位 | IP = fe80::ff:fe00:内联16位 |
| 11 | 全压缩 (节省128位) | IP = fe80::计算64位; 后 64 位由 SLAAC 计算,不携带 |
- Stateful(有状态压缩) (SAC = 1)
节点预先共享前缀(Context),用更短的索引来代替冗长的地址前缀。
- SAM = 00: 未指定地址(Unspecified Address, ::),全 0。
- SAM = 01: 前缀 =
<context>,携带后 64 位。 - SAM = 10: 前缀 =
<context>::ff:fe00,携带后 16 位。 - SAM = 11: 前缀 =
<context>,后 64 位由 SLAAC 计算,不携带。
目的地址压缩 DAC
Dest Address Compression,目的地址压缩
- ‘M’ (组播位) = 0:
- 目的地址是单播 (Unicast) 地址。
- 压缩方式与源地址压缩(SAC)相同,但存在以下例外:
- DAM=1, DAC=00: 保留,不使用。(课件如此,但似乎与下图不符)
- 在需要计算位(bits)的地方,计算依据是 802.15.4 帧中的目的 EUI-64 地址。
- ‘M’ (组播位) = 1:
- 目的地址是组播 (Multicast) 地址。
下面的图,如需要,会在考试中给出(真的吗)
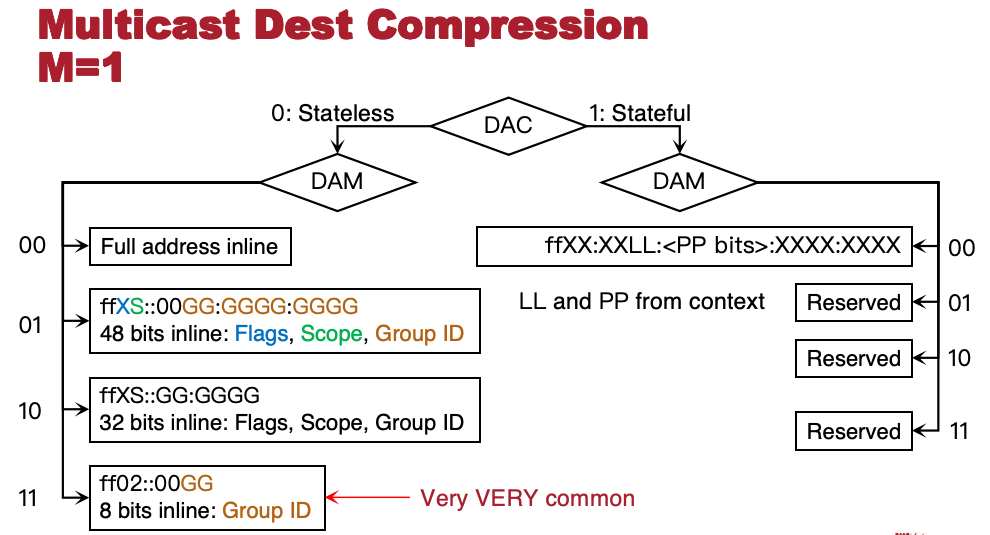
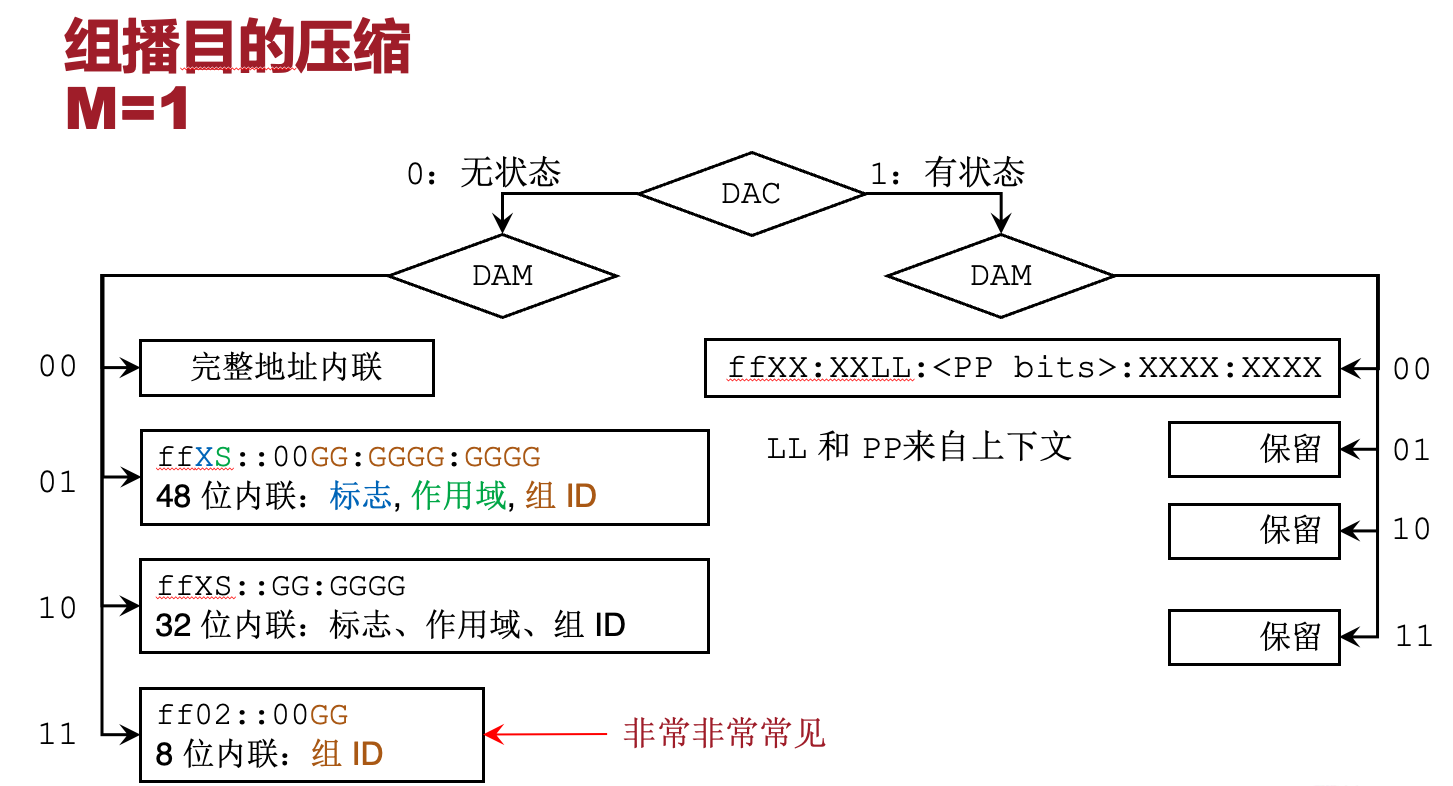
压缩方式主要由 DAC(目的地址压缩标志)和 DAM(目的地址模式)两个字段决定:
- 无状态压缩 (DAC = 0: Stateless)
- DAM = 00:全地址内联 (Full address inline)。携带完整地址。
- DAM = 01:48 位内联。格式为
ffXS::00GG:GGGG:GGGG。X=标志位 (Flags),S=作用域 (Scope),G=32 位组号 (Group ID)。 - DAM = 10:32 位内联。格式为
ffXS::GG:GGGG。包含标志位、作用域和 16 位组号。 - DAM = 11:8 位内联。格式为
ff02::00GG。包含 8 位组号。很常见
- 有状态压缩 (DAC = 1: Stateful)
- DAM = 00:格式为
ffXX:XXLL:<PP bits>:XXXX:XXXX。 LL 和 PP 位从上下文获取。 - DAM = 01, 10, 11:保留 (Reserved),不使用。
Eg. IPHC
A sends an IPv6 packet to C (via B) in this 6LoWPAN.
The initial value of the “Hop Limit” IPv6 header is 【64】.
(1) For the first hop from A to B:
–IPv6 src: IPv6 of A
–IPv6 dst: IPv6 of C
–MAC src: MAC of A
–MAC dst: MAC of B
(2) For the second hop from B to C:
–IPv6 src: IPv6 of A
–IPv6 dst: IPv6 of C
–MAC src: MAC of B
–MAC dst: MAC of C
Q: What is the value of HLIM in IPHC at the first hop (A->B)? Is anything carried inline?
A:
HLIM: 10. (因为题干中说Hop limit初始值为64)
Nothing carried inline
参考:IP头压缩 IPHC
只有当 HLIM 为 00 时,才需要额外携带 8 位的 Inline 数据。
Q: What is the value of HLIM in IPHC at the second hop (B->C)?
Is anything carried inline?
A:HLIM: 00, Carried inline the original Hop Limit Header, value 63
由于Hop Limit需要减一,变成63。
在 IPHC 压缩标准中,只有 1、64 和 255 这三个特定数值有对应的压缩位(分别为 01, 10, 11)。
由于 63 不属于这三个特殊值,无法被压缩。因此 HLIM 必须设置为 00。
原本 8 位的 Hop Limit 值(即 63,十六进制为 0x3F)必须完整作为 Inline 数据 紧跟在 IPHC 压缩报头之后携带
Q: Device A sends an IPv6 packet to C (via B) in this 6LoWPAN. The IPv6 addresses are:
A: FDFD::6CE:7E00:10AB:1
C: FDFD::CF1A:B600:AB:3
Apply 6LoWPAN IP Header Compression (IPHC) for the first part of the path (from A to B).
Provide values for the following IPHC dispatch fields: “SAM”, “SAC”, “DAM”, “DAC”, “M”.
Specify what parts of the source and/or destination addresses are being carried inline, if any.
If you need to use 6LoWPAN contexts, assume FDFD::/64 to be context 0.
A: M=0, SAC=1, SAM=11, DAM=01, DAC=1, Context=0
Destination v6 64bits of the host part carried inline
解释:
| 字段 | 取值 | 原因 |
|---|---|---|
| SAC | 1 | Source Address Compression: 启用上下文,因为前缀匹配 Context 0。 |
| SAM | 11 | Source Address Mode: 源 IPv6 地址为 A,链路层源地址也为 A,因此可以从 A 的 EUI-64 计算出 A 的 IID。 |
| DAC | 1 | Destination Address Compression: 匹配 Context 0,启用上下文压缩。 |
| DAM | 01 | Destination Address Mode: 目的 IPv6 地址为 C,但该跳的链路层目的地址是 B,而不是 C。因此无法从此帧中的 802.15.4 目的地址计算出 C 的 IID。需要内联 64 位 目的地址 C 的主机号(CF1A:B600:00AB:0003) |
| M | 0 | Multicast: 目的地址是单播 |
Inline 携带的部分
由于无法通过 MAC 地址完全推导整个 128 位 IPv6 地址,以下部分需要以 Inline 方式放入报文:
- 目的地址 (C) 的后 64 位:
CF1A:B600:00AB:0003
Jan 2019
(e) Two devices (A and B) are equipped with IEEE 802.15.4 radios and are within range of each other. The two devices have the following MAC addresses:
(ii) Device A sends a 6LoWPAN message using IPHC (IP Header Compression). The relevant fields of the 6LoWPAN encapsulation header have the following values:
Field ‘M‘ (Multicast Address Compression): True
Field ‘DAC‘ (Destination Address Compression): Stateless
Field ‘DAM‘ (Destination Address Mode): 8 bits
Group ID: 00000001 (binary)
What is the destination IPv6 address of this datagram after 6LoWPAN decompression?
Answer: ff02::1
解释:
M:1
DAC: 0
DAM: 11
由目的地址压缩 DAC得知DAM格式为 ff02::00GG,GG为 8 位组号。
由于Group ID=00000001,所以解压后的地址为:ff02::1
ff02::1是一个众所周知的 IPv6 地址,代表 所有节点组播地址 (All Nodes Address),且其范围限制在链路本地 (Link-Local)
MQTT
Message Queueing Telemetry Transport
消息队列遥测传输
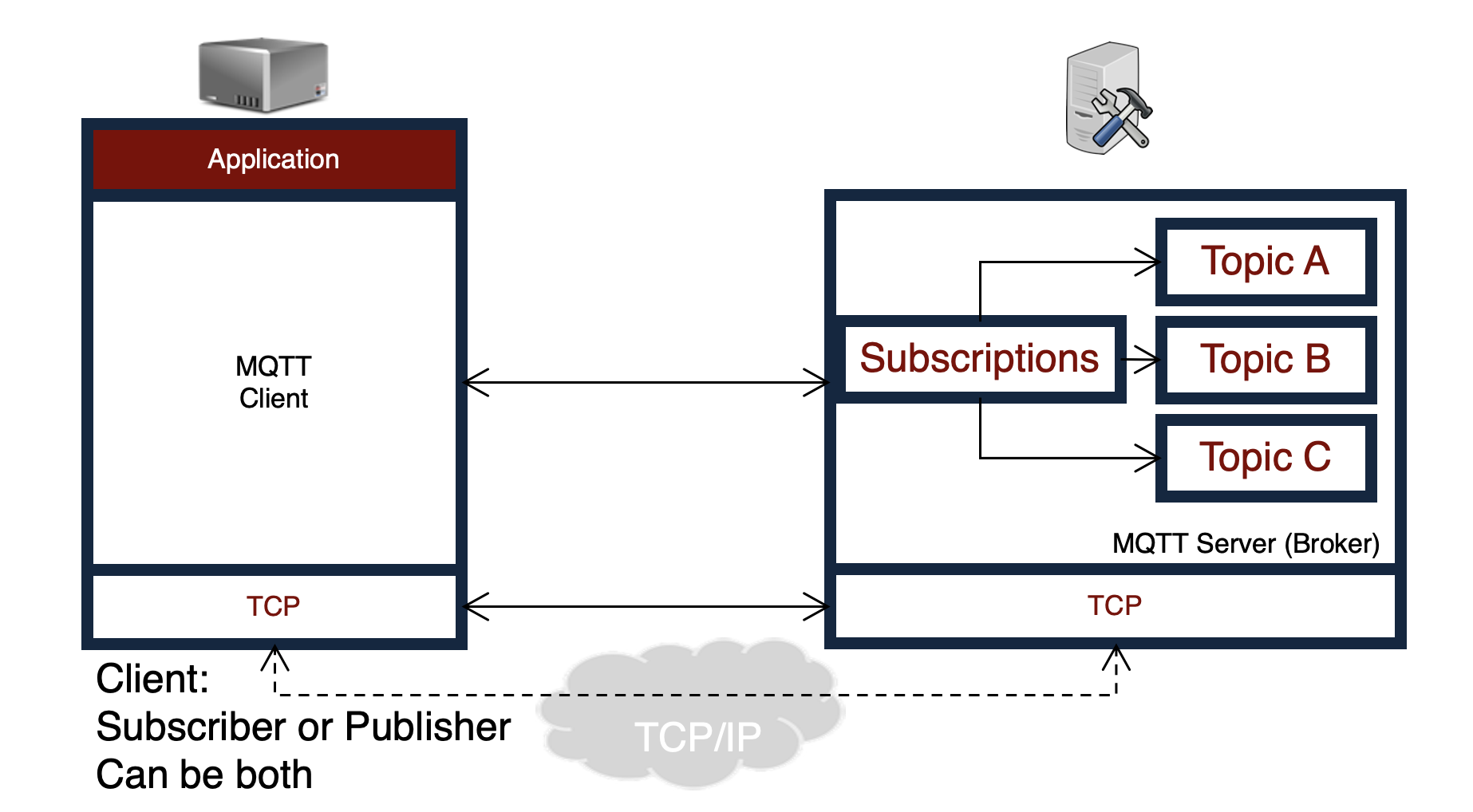
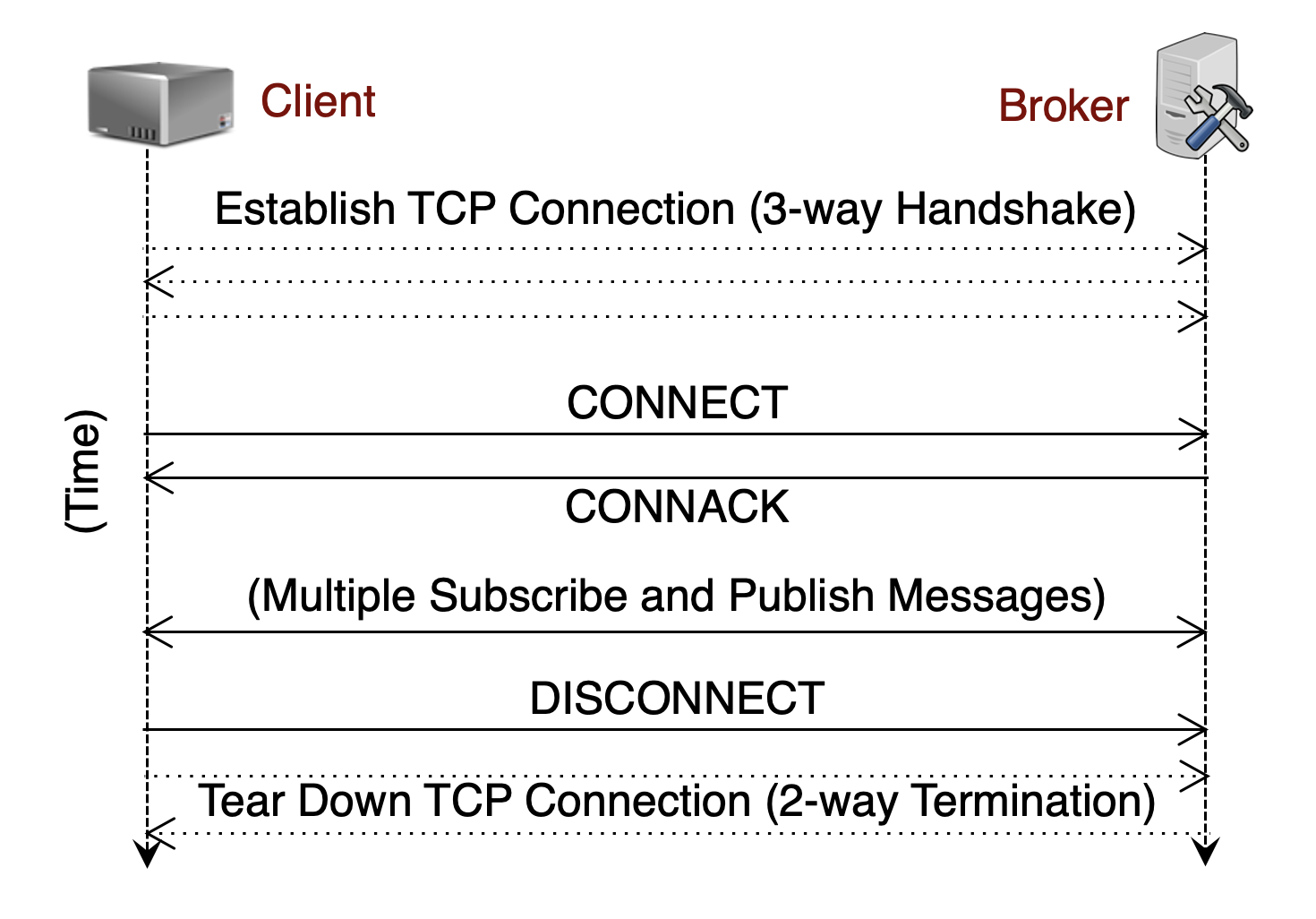
连接的建立与断开
发布与订阅的交互逻辑
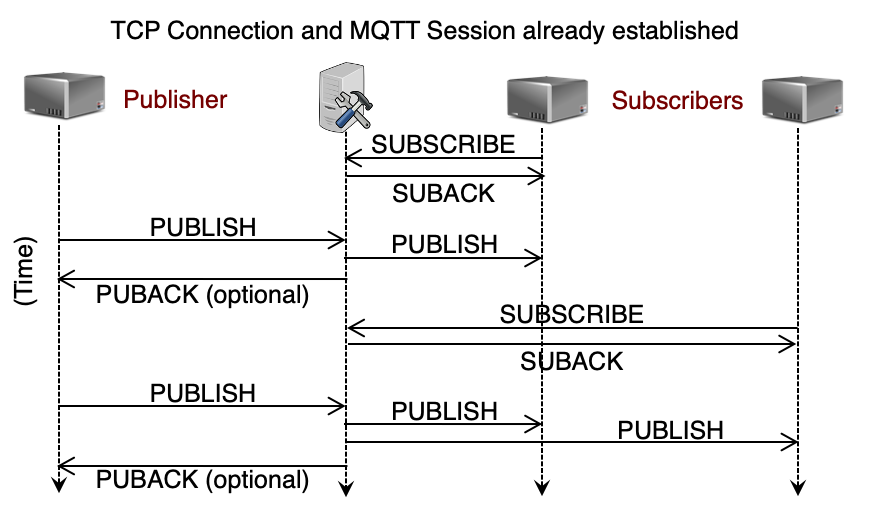
订阅流程: 订阅者发送 SUBSCRIBE 报文给 Broker,Broker 回复 SUBACK 确认。该订阅者就“挂”在了某个主题下。
消息分发:
- 当 Publisher 发布一个
PUBLISH消息到 Broker 时,Broker 将其转发给订阅该主题的 Subscribers。 - 图中展示了两个订阅者:一个较早订阅,接收到了两条消息;另一个较晚订阅,只接收到了其订阅之后的第二条消息。
确认机制 (QoS): 图中提到了 PUBACK (optional)。这取决于服务质量 (QoS) 等级。如果设置为 QoS 1,Broker 会回复确认,以确保消息至少送达一次。
QoS
记忆方法:
“越来越复杂”
QoS 0 只传一次 丢失不管
QoS 1 可传多次
QoS 2 只传一次 确保送达
- 在 TCP 之上的额外可靠性层
- SUBACK 和 CONNACK 不是可选的,也不属于 QoS 的范畴。
- QoS 0:至多一次(At most once)交付
- 丢失不重传
- QoS 1:至少一次(At least once)交付
- 使用 PUBACK 消息来确认 Broker 已收到一条 Publish 消息
(参见上一页中“可选的 PUBACK”) - 发布者在超时后重试
- 使用 PUBACK 消息来确认 Broker 已收到一条 Publish 消息
- QoS 2:恰好一次(Exactly once)交付
- QoS 1 + 不允许重复
- 控制消息流程更复杂
更多消息类型*(More Message Types)
- PUBREC、PUBREL、PUBCOMP: 仅用于 QoS 2
- UNSUBSCRIBE、UNSUBSCRIBEACK:终止订阅
- PINGREQ、PINGRESP:“你还活着吗?” → “是的,我还在”
- 每个会话都有一个 Keep Alive(保活)时间(在 CONNECT 消息中设置)
- 规定客户端两次发送消息的最大时间间隔
- 没有其他消息发送时,用 PINGREQ 重置 Keep Alive 计时器
消息发布触发条件
Publish Message Triggers
问:什么触发一次发布(publish)?
答: 由 Publisher 决定,与 Topic 相关。Subscriber 不能请求发布。
示例(可组合使用):
- 周期性触发(例如:每 X 秒 / 分钟一次)
- 突变触发(例如:当前读数相对于上一次读数变化 ±10%)
- 阈值触发(例如:读数超出正常范围)
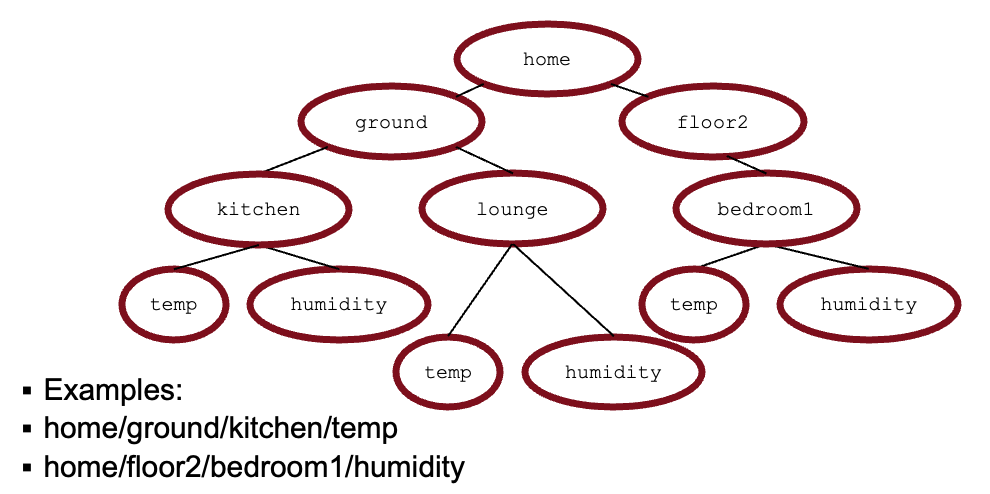
Topics
每一条 publish 消息只对应一个 Topic
一个客户端可以订阅多个 Topic
Topic 是字符串(有点像文件地址,但开头和末尾不加斜杠)
示例:
home/ground/kitchen/temphome/floor2/bedroom1/humidity
单层通配符
Single-level Wildcard
单层通配符: +(加号)
只匹配一个主题层级
位于 Topic 的开头,或紧贴在分隔符 / 之后
合法用法:
this/+this/+/that+
非法用法:home/gr+/bathroom/temp
示例:home/+/bathroom/temp
可以匹配:
home/ground/bathroom/temphome/floor1/bathroom/temp
不能匹配:
home/ground/kitchen/temphome/ground/bathroom/humidity
多层通配符
Multi-level Wildcard
多层通配符: #(井号)
可匹配一个或多个主题层级
可单独使用,或 放在 Topic 末尾且必须紧跟在分隔符 / 之后
合法用法:
#this/#
非法用法:
this/#/thathome/gr#/bathroom/temp
示例:
home/ground/#
可以匹配:
home/ground/bathroom/temphome/ground/kitchen/humidity
不能匹配:
home/floor1/bathroom/temp
两种通配符可以组合使用
home/+/bathroom/#(来自任意楼层、但仅限浴室的所有读数)
[Eg. MQTT]
来源:历年真题
本题答案为官方答案
Q1: A Smart City application uses sensors to monitor outdoor environmental parameters (temperature, noise level, CO2 level, air humidity) around Bristol. The application uses sensors that report environmental readings using the Message Queue Telemetry Transport (MQTT) protocol. The application uses a 4-level MQTT topic hierarchy:
- The top level of the hierarchy is always “smart-bristol”.
- The second level of the hierarchy represents the post code of the area where a device has been installed.
- The third level of the hierarchy can either be “data” or “monitoring”. The former is used for actual environmental readings and the latter is used so that sensors can report diagnostic data.
- The 4th level of the hierarchy represents the type of data sent. When the third level is “data”, the 4th level can have the following values: i) “temp”, ii) “noise”, iii) “co2”, iv) “humidity”.
For example, assume a sensor installed at post code BS81UB. To send noise level data, the device will use topic “smart-bristol/BS81UB/data/noise”. To send the results of a diagnostic self-test, the device will use topic “smart-bristol/BS81UB/data/diagnostic”
(a) Using MQTT wildcards, write down a topic that can allow a process to receive all types of reading from devices installed at post code BS8 1TH.
smart-bristol/BS81TH/# |
(b) Using MQTT wildcards, write down a topic that can allow a device to receive noise level readings only, from all devices at any location.
smart-bristol/+/data/noise |
(c) Classify MQTT as publish/subscribe, client/server or both.
both |
(d) How many Quality of Service levels does MQTT support? For each of those service levels, briefly explain how many times a message gets delivered.
Three. |
CoAP
The Constrained Application Protocol,资源受限应用协议
CoAP 使用 UDP ※
HTTP:
- 冗长(基于文本的头部)
- 数字 60000 可以用 2 个字节的无符号整数表示(范围
[0, 65535] - 但在 HTTP 中需要 5 个字节,因为是按字符逐个编码的
- 数字 60000 可以用 2 个字节的无符号整数表示(范围
- TCP(有状态,更复杂)
CoAP 为什么使用UDP
- Stateless 无状态
- little RAM
- simple to implement
- compact header
Messages


CoAP 可以方便地与 HTTP 进行代理(proxy)转换(互通)
GET: 从服务器读取资源
POST: 更新或创建资源(通常如此)
PUT: 更新或创建资源
DELETE: 删除服务器上的资源
- PUT 是“幂等的(idempotent)”
- 两个完全相同的 PUT 请求会产生相同的结果
- POST 不是幂等的
- 两个完全相同的 POST 请求可能会产生不同的结果
CoAP Uses URLs
coap://192.168.0.1:5683/sen/temp?v=1
coap://[fdfd::1]:5683/sen/temp?v=1
响应码
Response Codes
会考某类型的第一位数字是什么 (2/4/5)
2.xx: Success |
紧凑消息
Compact Messages
CoAP 消息是紧凑的
“请求方法(Request method)和响应码(Response code)不会以明文形式出现在消息中”
消息头中的 CODE 字段:8 位(8 bits)
- 用于同时表示请求方法(Request)和响应码(Response)
一些示例:
1:GET2:POST65:2.01 Created69:2.05 Content
Resources
Resource Discovery 资源发现
CoAP 服务器可以告知它所提供的资源(资源发现机制)
对 .well-known/core 资源发送 GET 请求
示例:
coap://[fdfd::1]/.well-known/core |
服务器的响应会描述所有可用的资源
资源可以是分层结构的
可靠性
CoAP 基于 UDP:在应用层自己实现 Reliability
消息类型(由头部中的 “T” 字段决定,占 2 位):
0:可确认(Confirmable,CON)1:不可确认(Non-Confirmable,NON)2:确认(Acknowledgement,ACK)3:重置(Reset,RST)
捎带式响应
Piggybacked Response
ACK 被包含在响应消息中一起发送

丢包重传
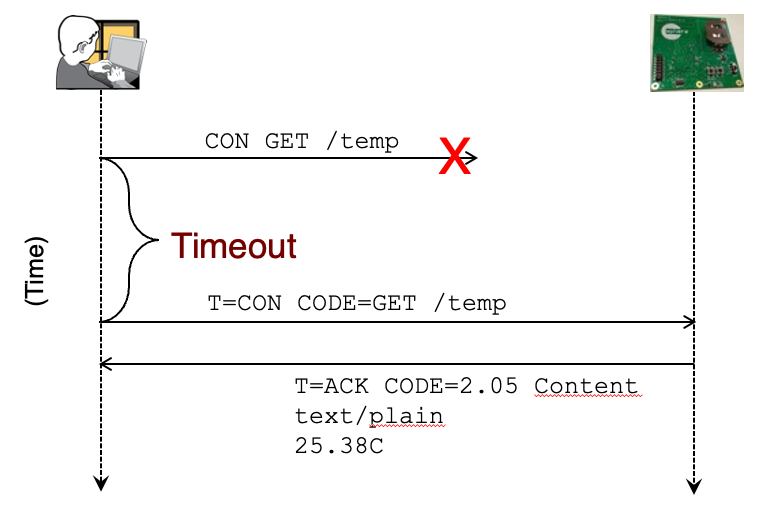
Separate Response 分离式响应
当 处理请求需要时间 时,为避免超时重传,先发送ACK。处理完成后再返回响应内容。
通过相同的MID来对请求(Request)进行确认(ACK)
通过相同的Token来对请求(Request)进行响应(Response)

请求 / 响应匹配(Request / Response Matching)
问:如果客户端发送多个请求,客户端如何知道哪个响应对应哪个请求?
答:通过 Token。请求和响应中使用相同的 Token。
[Eg. CoAP]
来源:历年真题
本题答案除了 (f) 外,为官方答案
(a) Name the transport layer protocol that is normally used with the Constrained Application Protocol (CoAP). (2’)
UDP |
(b) One of the original design requirements for CoAP was to make it suitable for constrained networks and devices. Comment on whether the choice of underlying transport layer protocol (your answer to (a)) helps CoAP meet this design goal. (6’)
UDP: stateless / consume little RAM / simple to implement |
(c) What is the first digit of CoAP status codes that signify a client-side error? (3’)
4 |
(d) Briefly explain the concept of CoAP’s “Piggybacked responses”. (4’)
The response to a confirmable (CON) request is sent inside a CoAP packet of type "ACK", thus also acknowledging the request. |
(e) Which header field does CoAP use to match requests with acknowledgements? (2’)
Message ID (MID) |
request ↔ ACK:用 Message ID / MID
request ↔ response:用 Token
(f) Which header field does CoAP use to match responses to requests? Using an example, explain why this is necessary in a scenario that involves a “separate response”. Do not use a diagram for your answer. (8’)
Token. |
互联网路由
AS
Autonomous System (AS) 自治系统
- Aggregation of routers into regions 将路由器聚合为不同的区域
- One routing protocol within an AS (Intra-AS routing protocol) AS 内部用 Intra-AS 协议
- Routers in different AS can run different intra-AS routing protocol 不同 AS 可运行不同 Intra-AS 协议
Gateway routers 网关路由器
- Run intra-AS routing protocol with all other routers in AS. 它与 AS 内的路由器运行 intra-AS 协议
- inter-AS protocol with other gateway routers 与其他 AS 的网关路由器运行 Inter-AS 协议
网关路由器同时参与两种协议:
| 功能 | 使用协议 | |
|---|---|---|
| 和本 AS 内部通信 | Intra-AS (RIP, OSPF, Dijkstra) \ | 内部网关协议(IGP) |
| 和其他 AS 通信 | Inter-AS (BGP) \ | 外部网关协议(EGP) |
ASN
AS 由 32 位整数(ASN)标识 [之前为 16 位]
一、编号范围
- 0–65535:最初的 16 位编号范围
- 65536–4294967295:32 位编号范围(由 RFC4893 扩展)
二、使用情况
- 0 和 65535:保留
- 1–64495:公网使用
- 64496–64511:文档示例使用(RFC5398)
- 64512–65534:私有使用
- 23456:在 16 位系统中表示 32 位 ASN 的特殊编号
- 65536–65551:文档示例使用(RFC5398)
- 65552–4294967295:公网使用
BGP
Border Gateway Protocol 边界网关协议
RFC 1267
TCP
是 Path Vector 协议,类似 Distance vector 距离向量协议
会记录并通告到达目的地的完整路径
如果存在多条路径,路由器可以选择“最佳路径”
无环(Loop-Free),不会出现 RIP 的环路问题
先交换完整路由表,之后只发送更新信息
路径
【注意】:课件和题目中的路径顺序似乎是相反的。做题时按照题目中的描述来,看起点AS在路径的最前面还是最后面。
- 每个边界网关都会向其相邻的 Peer 对等体通告到达目标的完整路径
- 即:到达目的地经过的 AS 序列(从它自己开始)
例如,网关 X 向邻居通告它到达目标 Z 的路径:
路径 (X, Z) = X, Y1, Y2, Y3, … , Z
意思是:从 X 到 Z,需要依次经过这些 AS。
BGP 的一般工作过程
- 通过内部 BGP 和外部 BGP 路由器,发现多条路径
- 选择最佳路径,写入路由信息库(RIB,Routing Information Base)
- 将最佳路径通告给外部 BGP 邻居
转发表
Forwarding Table
BGP “输入(in)” 过程
从 peers 接收路径信息
选择最佳路径放入 BGP 表中
BGP “输出(out)” 过程
- 向 peers 通告(advertise)最佳路径
最佳路径的存储与安装
最佳路径存储在路由表 Routing Table(RIB,路由信息库)中
如果满足以下条件,RIB 中的最佳路径会被安装到转发表 forwarding table(FIB,转发信息库)中:
- 前缀和前缀长度唯一
- 具有最低的“协议距离”(Protocol Distance)
这里的 “前缀(prefix)” 指的是:一段 IP 地址范围(一个网络块)
因为 BGP 路由的是“网络块”
eBGP 与 iBGP
Intra-AS 协议:在 AS 之内使用。约等于 Interior Gateway Protocol (IGP)。例如:RIP OSPF Dijkstra
Inter-AS 协议:在 AS 之间使用。约等于 Exterior Gateway Protocol (EGP)。例如:BGP
iBGP:在 AS 之内传播 eBGP 学到的外部路由(网络前缀)
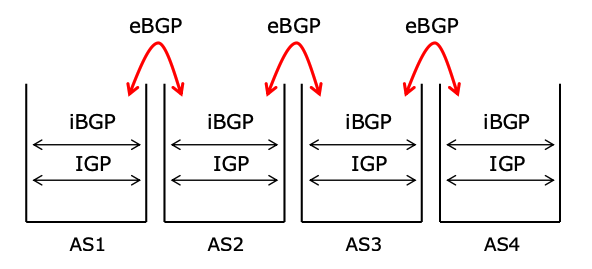
- BGP 可以在内部使用(iBGP),或外部使用(eBGP)
eBGP
- 发生在 不同 AS 中的 BGP 路由器之间
- 直接相连
- 禁止在 eBGP peers 之间运行 IGP(内部网关协议)
BGP 的路由传播受商业关系影响:
网络通常只愿意为“客户”转发流量,而不会免费为其他提供商做中转。
iBGP
- 在 ISP 骨干网络中传递互联网前缀
传递 ISP 客户的前缀
BGP 对等体位于 同一个 AS 内部
- 不要求直接物理连接
- 由 IGP(内部网关协议)保证 BGP 路由器间的连通
iBGP 路由器必须形成全互连(Full Mesh)
- 它们可以发布自身直连的网络
- 会传播从 AS 外部学到的前缀
- 但 不会传播从其他 iBGP 路由器学到的前缀
从一个 iBGP 邻居学到的路由,不能再转发给另一个 iBGP 邻居
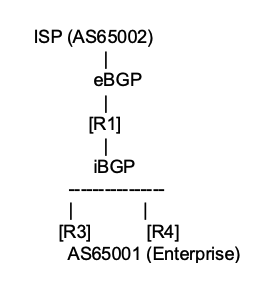
iBGP 路由器须与 AS 内的所有其他 iBGP 路由器建立对等关系(Peering)(全互连,Full Mesh),两两建立 BGP 会话
BGP 报文
messages
BGP 的报文类型:
- OPEN:建立到对等体的 TCP 连接,并对 sender 进行认证
- UPDATE:通告新的路径(或撤销旧路径)
- KEEPALIVE:在没有 UPDATE 报文时保活;确认(ACK)OPEN 请求
- NOTIFICATION:报告之前报文中的错误;用于关闭连接
工作流程
Q: What does a BGP router do?
Receives and filters route advertisements from directly attached neighbour(s).
接收并过滤来自直接连接邻居的路由通告。
注意:以下的示例似乎存在错误
示例拓扑
- R3 属于 AS 65003
- R1 属于 AS 65001
- R2 属于 AS 65002
网络结构:
AS 65003
|
[R3]
|
AS 65001 — [R1] —— [R2] — AS 65002
路由传播过程
1️⃣ R1 起源(originates):
- 前缀:10.1.0.0/16
- AS-PATH:65001
说明:这个网络最初属于 AS 65001。
2️⃣ R2 接收并更新:
- 前缀:10.1.0.0/16
- AS-PATH:65002 65001
说明:R2 在向外通告时,把自己的 AS 号 65002 加在前面(与之前的描述相反)。
3️⃣ R3 接收:
- 前缀:10.1.0.0/16
- AS-PATH:65003 65002 65001
说明:R3 再把自己的 AS 号加在最前面。
总结流程
- 配置对等体(Configure Peer)
- 建立 TCP 会话(端口 179)
- 交换 OPEN 报文
- 交换 UPDATE 报文(路由 + 属性)
- 运行最佳路径算法
- 安装最佳路由
- 向其他对等体通告
- KEEPALIVE 维持连接
[Eg. Inter-AS routing]
来源:EENGM4211 - 2023 Q4
Q4: Consider the following Figure.
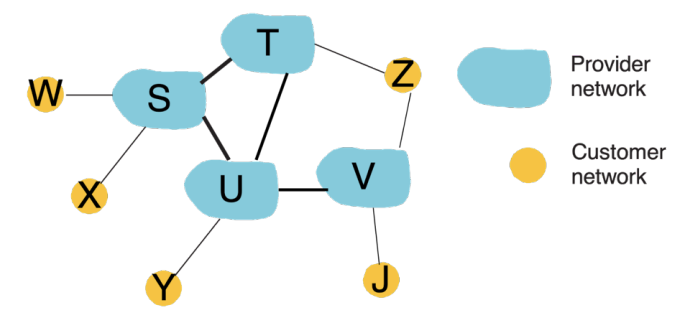
In the above network environment, consider Inter-AS routing. In principle, S will advertise to T that it can be used to reach network W and hence advertises route WS to T. Z is connected to two provider networks T and V. Answer the following questions.
[a]. If the traffic from X is meant to reach Z, which route will be followed AND for that route to be followed, which advertisements will be considered? (4 Pts)
Answer:
- 将遵循的路由: X -> S -> T -> Z
- 虽然 X 可以通过
X-S-U-V-Z到达 Z,但 BGP 选跳数较少的路径
- 虽然 X 可以通过
- 需要考虑的路由通告(Advertisements)
- Z 向 T 通告自己可达
- T 向 S 通告路由 ZT
- S 向 X 通告路由 ZTS
此题,对于 advertisement,原始路由放在最左边
[b]. Consider the same situation as above for the traffic from Z to Y? (4 Pts)
Answer:
- 将遵循的路由:Z -> V -> U -> Y (或者 Z -> T -> U -> Y,具体取决于路径开销)
- 需要考虑的路由通告
- Y 向 U 通告自己可达
- U 向 V 通告路由 YU
- V 向 Z 通告路由 YUV
[c]. What would be the possible advertisement exchange between U and T? (give reasons for your choice). (2 Pts)
Answer:
U 可以向 T 通告 YU,因为 Y 是 U 的客户
T 可以向 U 通告 ZT,因为 Z 是 T 的客户
在 Inter-AS / BGP 中:
只把客户路由通告给 provider / peer
不会把从 provider 或 peer 学到的路由再通告给另一个 provider / peer。
无线网路由
Infra 基础设施模式
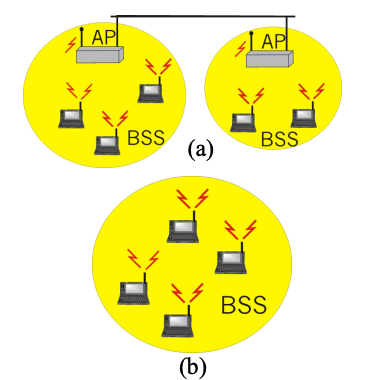
基础设施模式(Infrastructure,图a)
- 节点通过基站(AP,接入点)进行通信
- 网络管理通过固定基础设施支持(每个 AP 覆盖一个 BSS基本服务集)
- 需要仔细规划
- 通常连接到其他网络
Ad-hoc 自组织模式
自组织模式(Ad-hoc,图b)
- 没有基站;终端节点彼此直接通信
节点既要充当路由器,又要作为终端设备
由无线主机构成(可移动)
不需要现有基础设施
不需要提前规划
可能是多跳通信
隐藏站问题
Hidden Terminal Problem
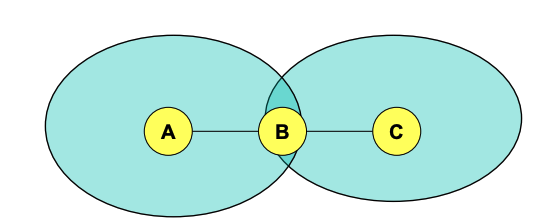
节点 A 和 C 彼此“听不到”对方
- 即 A 和 C 互相隐藏
- 它们不知道对方正在发送数据
- 因此可能同时向 B 发送数据
结果:
- 两个信号在 B 处发生冲突(碰撞)
- B 无法正确接收数据
暴露节点问题
Exposed Node Problem
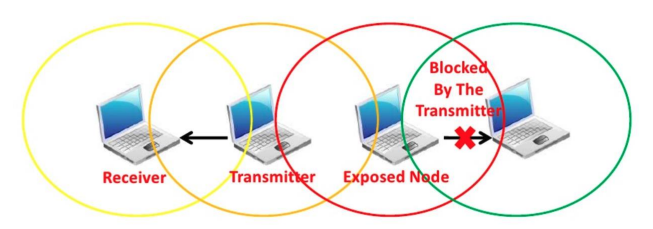
- 发送端正在向接收端发送数据
- 暴露节点(Exposed Node)“听到”附近有传输在进行
- 因此误以为信道被占用,不敢发送
但实际上暴露节点向自己的目标发送数据不会造成干扰
Ad-hoc 媒体控制协议
Ad-hoc Media Access Protocols
- 传输介质由所有节点共享
- 可以随时发送数据 → 会产生竞争(contention)
- 需要使用 介质访问控制(MAC)协议
RTS/CTS 机制示意
通信流程:
1️⃣ RTS(Request To Send):发送请求传输
2️⃣ CTS(Clear To Send):允许发送,并告知传输持续时间
3️⃣ Data:发送数据
为什么 Ad-hoc 的路由与有线网络不同?
- 所有节点可同时为主机(host)和路由器(router)
- 可能采用对称或非对称算法
- 链路故障的特性与有线网络不同
- topology change 拓扑变化速率(通常由链路失效引起)可能非常剧烈
- 例如当节点相对彼此高速移动时
- Link characteristics 链路特性并不总是二元的(开/关)
- 链路可能仍然可用,但带宽较低
- 这意味着在优化时需要考虑更多变量
- 资源受限 —— 尤其是 power
Ad-hoc 路由算法
Ad-hoc Routing Algorithms
距离向量(Distance Vector):类似于传统 IP 路由算法
链路状态(Link State):类似于传统 IP 路由算法
源路由(Source Routing)
数据包的发送方指定该数据包在网络中的完整路径
在非源路由协议(如距离向量)中,路由器根据目的地址来决定路径
链路反转(Link Reversal):见 Link Reversal
泛洪(Flooding):如下
泛洪 Flooding
- 发送方将数据包广播给所有邻居
- 每个接收到数据包的节点都会将其转发给自己的所有邻居
- 使用序列号来检测并丢弃重复的数据包
- 当数据包到达目的节点后,就不再继续转发
优点
- simple 简单
- reliability 可靠:数据可以通过多条路径送达
缺点
- high overhead 高开销
- No reliability guarantees 没有可靠性保证
Link Reversal
网络中一条链路故障时,通过不断调整链路方向,使整个网络形成一个无环结构,
所有流量最终都会沿着 有向边 流向目标节点。
即:“如果节点到目的地没路了,就反转链路方向,让路由方向局部重组,直到重新找到通向目的地的路径。”
- 算法为链路赋予方向(即使链路本身是双向的)
- 目标是维护一个有向无环图(DAG),且目的节点是唯一的“汇点(sink)”
DAG 的性质
- 图中只有一个节点只有入边,就是目的节点(汇点 sink)
- 其他节点要么同时具有入边和出边,要么只有出边
- DAG 中的每一条路径最终都会指向汇点
工作流程
当一个节点没有出边时,把它连接的所有边反转
- 当这个节点反转后,它的邻居可能也失去了出边
- 邻居也会触发反转
即:级联反转(cascade reversal)
反转会不断传播,直到:
- 网络重新形成一个 DAG
- 所有路径最终都能到达 D
- D 再次成为唯一 sink
系统重新稳定。
示例
- 网络正常运行
- G发现 G - D 链路故障
- G 没有出路,于是反转它的所有链路
- E、F 没有出路,各自反转所有链路(注意此时G的链路也被顺带反转)
- G、B 没有出路,各自反转所有链路
- F 没有出路,反转它的所有链路(完毕)
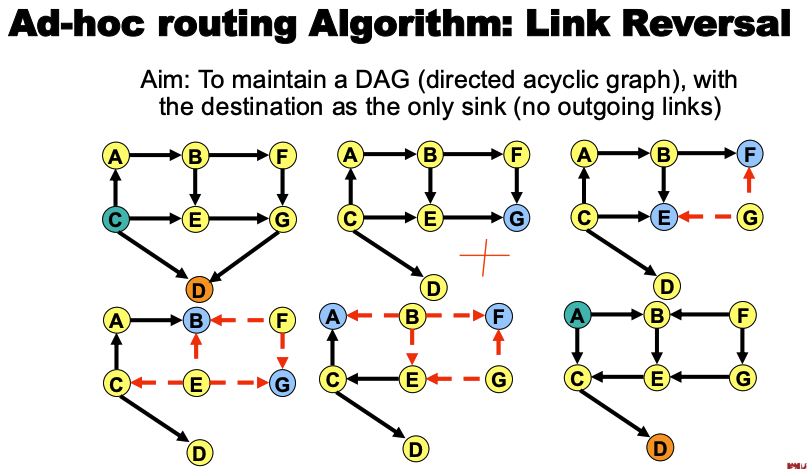
优缺点
优点
- 只进行与链路失效相关的局部更新,减少控制报文开销
- 具有一定程度的冗余性 redundancy
- 每个节点可能有多条通往目的节点的路径
缺点
- 需要一种机制来检测链路失效 —— 在无线网络中较为困难
- 链路反转过程可能无法收敛 converge(持续振荡)
[Eg. 距离-向量路由]
来源:EENGM4211 - 2023 Q1
此题可能不在考察范围内
Q1: Consider the following network topology. There are five routers (A, B, C, D, and E). The link distances are represented by numeric values on the edges. Consider a distance-vector routing protocol and B’s routing table is shown in the table.
Now, we assume that the first iteration of information exchange is completed and all the nodes in the network have exchanged their routing information with the neighbors.
In the second iteration, what will be the status of the routing tables (values of the routing table) for nodes E and C?
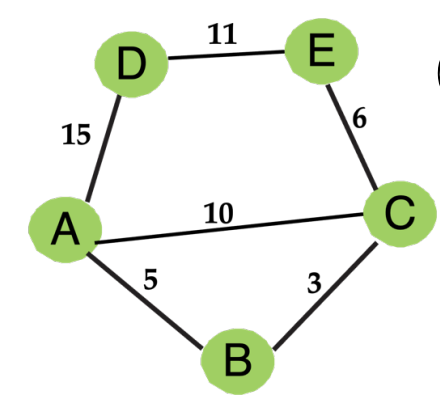
(10 pts)
B’s routing table in the first iteration:
| Destination | Via | Distance |
|---|---|---|
| A | A | 5 |
| C | C | 3 |
| D | - | ∞ |
| E | - | ∞ |
Answer:
C:
| Destination | Via | Distance |
|---|---|---|
| A | B | 8 |
| B | B | 3 |
| D | E | 17 |
| E | E | 6 |
E:
| Destination | Via | Distance |
|---|---|---|
| A | C | 16 |
| B | C | 9 |
| C | C | 6 |
| D | D | 11 |
[Eg. 距离-向量路由]
来源:EENGM4211 - 2023 Q2
答案由 AI 生成,不保证正确
此题可能不在考察范围内
Q2: Which of the following statement(s) is/are correct about Distance Vector Routing Algorithm? (8 Pts)
a. Distance vector routing algorithm is usually used only in Local Area Networks.
❌ 错:DV(如 RIP)可以用于更大范围网络(WAN 也能用)
b. The change in hop count during normal network operation should be propagated to all routers and the routers process these packets.
✅ 正确:变化(如 hop count)需要传播给所有路由器
c. One of the advantages of distance vector algorithms is that the size of the routing table is fairly small and thus making them the better choice for routing.
❌ 错:“更好选择”这个结论错误
d. Larger networks will consume more bandwidth because of route discovery propagation among the neighbors.
✅ 正确
e. Distance vector is one of the exterior gateway protocols.
❌ 错:DV 是 IGP(内部网关协议)。BGP 是 EGP。
f. Distance vector protocol can cause congestion in the WAN because all the routers need to have information from the neighbors and that information is usually the routing tables themselves.
✅ 正确
[Eg. 距离向量 链路状态]
来源:EENGM4211 - 2023 Q3
答案由 AI 生成,不保证正确
此题可能不在考察范围内
距离向量(RIP):局部,慢收敛
链路状态(OSPF, 每个节点都以自己为root运行dijkstra):全局,快收敛
Q3: From the following statements, select only incorrect statement(s) about distance vector and link-state routing algorithms.
(8 Pts)
a. The bandwidth required in the link-state routing protocol is more than distance-vector protocol and the link-state requires a global view of the network.
✅ 正确:Link-state 需要更多带宽 + 需要全局视图
b. Link state converges slower than distance-vector algorithm because of the larger table size of the link-state algorithm.
❌ 错误:Link state 收敛快
c. Open Shortest Path First (OSPF) is the best example of distance-vector algorithm and is widely used in current networks.
❌ 错误:OSPF 是 Link-State
d. Since link-state routing algorithms converge slower, they are susceptible to more loops in the network.
❌ 错误:Link state 收敛快
e. The change in a route state is propagated faster in the network in case of link-state algorithm whereas the distance-vector is only better in case of a positive change in the network (i.e., the cost of link becomes better).
✅ 正确:Link-state 传播变化更快;DV对“变好”更敏感
f. If a link changes in the network from ‘better’ to ‘worse’ (or cheaper to expensive), the distance-vector algorithm reacts to this change immediately and the new alternative route (if any) is propagated across the network very fast.
❌ 错误:DV 对“变坏”反应很慢
Ad-hoc 路由协议分类
一、主动式协议(Proactive protocols)
- 预先确定路由 / 独立于流量需求确定路由
- 类似有线网络路由
- 例子:链路状态、距离向量
- 维护到所有目的节点的路由表,并周期性更新
- 开销大,延迟低
二、反应式协议(Reactive protocols)
- 仅在需要时建立和维护路由(on-demand 按需路由)
- 依赖路由发现和路由维护机制
- 开销低,延迟高
三、混合式协议(Hybrid protocols)
- 为什么需要?因为单纯的主动式或反应式协议都不能完全满足需求
[Eg. Proactive vs Reactive]
来源:EENGM4211 - 2023 Q14
Q14: [判断题]Ad-hoc On-demand Distance Vector (AODV) routing protocol is a proactive protocol because it builds the routes to the nodes in the network whenever they are needed.
Answer: False. AODV 是 reactive(按需)协议,不是 proactive
Ad-hoc 路由协议: Cluster-based
节点角色不对称
- 所有节点既是路由器又是主机,但有些节点承担额外的管理职责
- 网络被划分为簇 clusters
- 每个簇选出一个节点(领导者 / 支配节点 leader/dominator)
不同方案的区别在于:
如何定义簇
如何进行簇首(领导者)选举
簇首承担哪些功能
CEDAR
CEDAR = 核心提取分布式自组织路由(Core-Extraction Distributed Ad Hoc Routing)
分层结构方案(Hierarchical scheme)
一部分节点被选为“核心节点”(core,也称为领导者 / 支配节点)
选择核心节点的原则:
- 每个普通节点都至少与一个 Core 节点相邻
- every other node is adjacent to at least one core node
核心节点通过周期性控制消息与非核心节点维护路由信息
同时也维护与其他核心节点之间的路由表
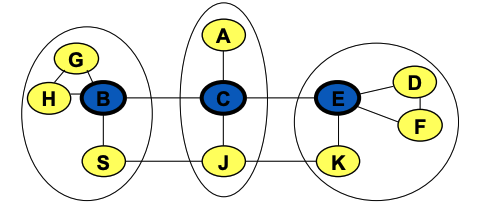
路由过程: 普通节点 → 本地核心节点 → 核心层传播 → 目标核心节点 → 目标节点
链路状态传播(Link State Propagation)
- 链路状态的传播取决于:链路稳定性、链路带宽
- 链路状态在Core 节点之间维护
- 核心节点知道:本地链路状态、到相邻核心节点的路径(不超过 3 跳)
路由发现(Route Discovery)
- 源节点通知它的核心节点(dominator)
- 该核心节点找到通往目标节点所属核心节点的路径
- 位于源和目的核心节点之间的其他核心节点 建立源与目的之间的路由
优点
- 路由信息的管理由相对较少的节点承担,更好的性能
- 将链路状态传播与链路质量(包括稳定性)关联
缺点
- 核心节点需要更多资源
- 需要设计角色选举算法
[Eg. cluster-based]
来源:EENGM4211 - 2023 Q11
a. In the cluster-based routing protocols in wireless networks, what are the parameters that should be considered while selecting/nominating the cluster head?
Answer: 网络中的每个普通节点都至少与一个核心节点相邻。every other node is adjacent to at least one core node
b. How would you differentiate a good selection and a bad selection of a cluster head in the network?
Answer:
Good cluster-head: well-connected, stable, good coverage
bad cluster head: unstable, poor coverage, more overhead
混合式协议:ZRP
ZRP = 区域路由协议(Zone Routing Protocol)
近的节点提前维护路由,远的节点按需查找路由,
基本原理:
- 对于某个节点 X,在跳数距离 d(半径 radius)以内的所有节点,都属于节点 X 的“路由区域(routing zone)”
- 与 X 的距离正好为 d 的节点称为“边界节点(peripheral nodes)”
下图中 D F E 为半径为 2 时的 Peripheral nodes
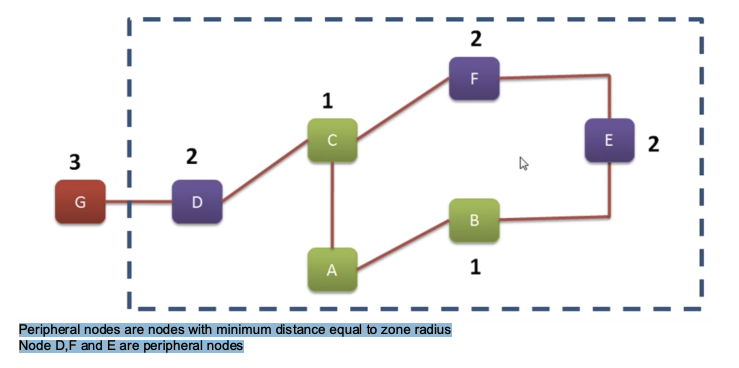
路由策略:
- 区域内(Intra-zone)路由:主动式
- 区域间(Inter-zone)路由:反应式
对于超出本地区域(local zone)的路由,采用反应式(reactive)方式进行路由发现。
边界节点逐级向外扩展查询,
一旦某个区域覆盖目标,就沿反向路径返回完整路径信息。
源节点向其区域的边界节点(border nodes)发送路由请求(RREQ)
包含:源地址,目的地址,唯一序列号
每个边界节点会在自己的本地区域中查找目标节点:
如果目标不在本地区域内,
该边界节点将自己的地址加入路由请求报文,并将其转发给自己的边界节点。如果目标属于该边界节点的本地区域,
则通过反向路径向源节点发送路由应答(RREP)。- 源节点利用路由应答报文中保存的路径向目标发送数据。
实时服务和 QoS
Realtime Services and QoS
多媒体网络应用
Multimedia Networking Application
分类:
- 流式音频视频
- 流式直播
- 实时交互音频视频
- 延迟敏感 delay sensitive
- 容忍丢包 loss tolerant
抖动(jitter)是同一数据包流中数据包延迟的可变性
交互式实时多媒体
Interactive, Real-Time Multimedia
应用: IP telephony, video conference
End - End delay requirements:
audio: < 150 msec good, < 400 msec OK
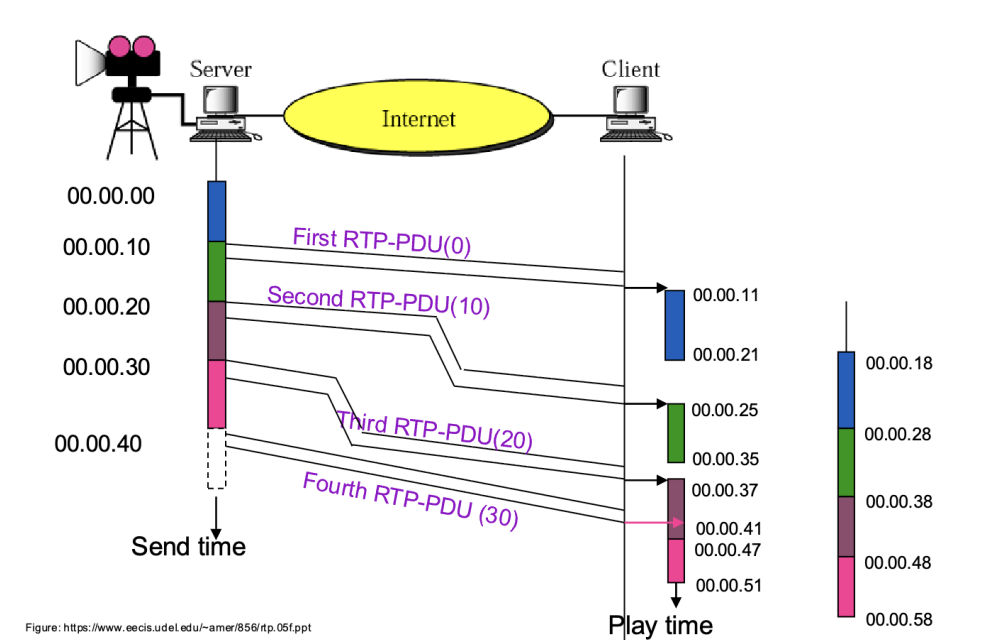
实时交付
Real Time Delivery
同步性
如何实现 Synchronicity
尝试share或schedule
- TDM 方案,类似于电话系统
- 浪费带宽
- 太复杂
给 everything 加上 Timestamps
- 接收方重建关系
- 需要大量内存
包和会话
Packets and Sessions
Packets 需要知道:
- format, encoding 格式 编码
- sequence number 序列号
- timestamp 时间戳
- source 源
Session 需要知道
- Quality of delivery 传输质量
- Who is sending? 谁在发送
- Who is participating 谁在参与
- Which sessions are associated(for sync) 哪些会话是相关的
RTP 实时传输协议
Real-Time Transport Protocol
功能
Timing information for playout 时间信息
Reordering information 重排序信息
Loss detection 丢包检测 for quality estimation, recovery
Synchronisation 同步
QoS feedback
Source identification 源标识
Cannot ensure real-time delivery 不能保证实时交付
头部格式
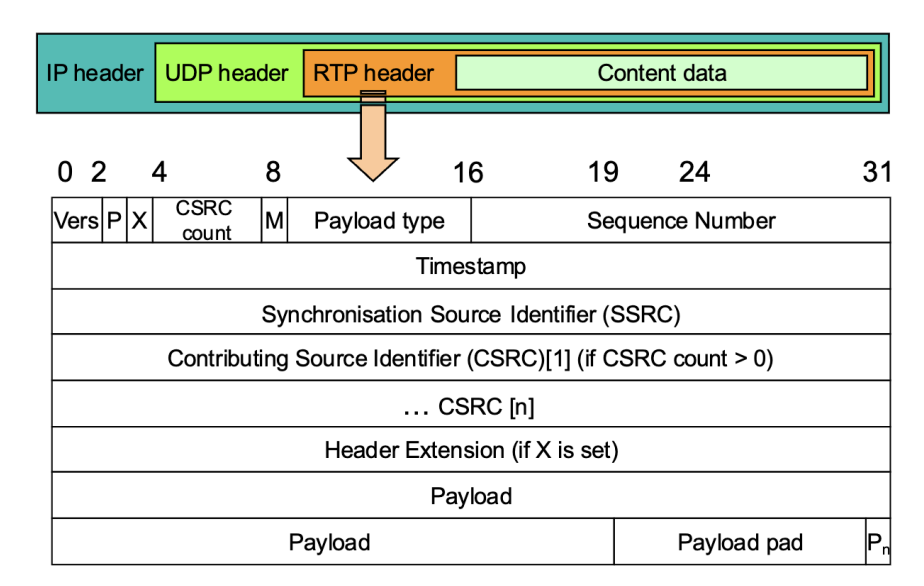
Version 始终为 2
P:最后一个字段包含填充(padding)
– 如果下层协议使用固定帧大小
– 最后一个字节表示填充块的大小
X:表示存在报头扩展(Header extension)
CSRC count:混合流中的贡献源(contributing sources)数量
M:由应用程序使用的标记,用于标识重要事件,例如流中的帧边界(frame boundaries)
Payload type(负载类型)
- G.721 (2)、GSM 语音 (3)、JPEG (26)
Sequence Number(序列号)
- 每发送一个 RTP 分组加 1,初始值为随机,用于检测丢包
- 用于关联各个数据包之间的顺序关系
Timestamp(时间戳)
- 时间戳将数据包与真实时间关联
- 时间戳的取值来自特定媒体的时钟
- 时间戳 = 分组时间间隔 × 采样率
- 例如:8kHz 采样、20ms 音频 → 时间戳 = 160
- 被分片的同一帧具有相同的时间戳
- 用于控制播放速率
Timestamp 与 Sequence Number 的区别(可能会考)※
- 例如视频:视频的一帧分成多个数据包发送
- 所有数据包有相同的时间戳,但序列号不同
同步源 Synchronisation source – SSRC
用于标识在发送端生成时间戳和序列号的实体(“这个 RTP 流是谁产生的”)
由发送端随机选择
标识符是唯一的
标识一个流:所有具有相同 SSRC 的数据包属于同一个流
可能存在的问题:源标识符冲突
贡献源 Contributing source – CSRC
- 用于接收端识别一个流中的所有源(“有哪些源参与组成了这个 RTP 流”)
RTCP
RTP 负责传数据
RTCP 负责传控制信息
RTCP:RTP Control Protocol
- 监控
– 路由质量
– 参与者数量/状态(发言者指示)
– 源的标识和类型 - 向应用程序提供反馈
– QoS 反馈 —— 发送方根据反馈调整发送速率 - 可扩展
– 随机化控制流量:随着参与者数量增加,控制消息的发送速率降低
RTCP Message
- 以 RTP 消息形式编码,使用预定义的 Payload Type 字段
- 发送方报告 Sender reports(SR)
– RTP 时间戳 + 序列号对应的实际时间
– 已发送的数据包数量和字节数 - 接收方报告 Receiver reports(RR)
– 丢失数据包的比例和总数
– 最高序列号
– 抖动(到达时间的方差)
– 上一次序列号的时间以及自上次序列号以来的延迟 - 谁使用这些报告?
– 应用程序:发送方可根据反馈修改传输方式
– 第三方监测器 用于定位问题 - BYE
– 由离开会话的源发送。
流的同步
Synchronisation of Streams
- 每个 RTCP 发送方报告(Sender Report)数据包包含(针对关联 RTP 流中最近生成的数据包):
– RTP 数据包的时间戳
– 数据包创建时的墙钟时间(wall-clock time) - 接收方可以利用这种关联来同步音频和视频的播放。
- RTCP 可以在一个 RTP 会话中同步不同的媒体流。
- 例如视频会议应用中,每个发送方会生成一个视频的 RTP 流和一个音频的 RTP 流。
- RTP 数据包中的时间戳与视频和音频的采样时钟相关联。
- 它们不与墙钟时间直接绑定。
QoS
从终端用户的角度:
QoS 对网络有效性、与服务/应用相关的指标进行量化,并与标准进行对比,这些指标包括:
- 时延(Delay)
- 抖动(Jitter)
- 丢包率(Packet Loss Rate)
- 响应时间(Response time)
- 吞吐量(Throughput)
- 服务可用性(Service Availability)
从服务提供商的角度:
为特定流量类别提供服务,使 QoS 能以保证/差异化的方式提供给终端用户。
→ 能够为选定的流量提供更好的服务
相关问题
Why can’t it be done in the best effort Internet?
Because:
Routes change all the time.
Traffic cannot be predicted or planned.
Routers/switches and links are congestion points that cannot be controlled or managed.
定义
- 流(FLOW): 流是指在源/目的主机对之间发送的一系列数据包,这些数据包沿着相同的网络路径传输。
- 已分配带宽(Allocated bandwidth):(在输出链路上)某个流所使用的链路容量比例。
- 根据资源分配来管理数据包队列
– 吞吐量、丢包、时延 - 路由器之间的信号
– 流规范(Flow specification)
– 流量规范(Traffic specification)
– 服务请求(Service requests)
Principle
原则 1:使用标记和服务协议
Use a marking and servicing protocol
示例:1 Mbps 的 IP 电话和一个 FTP 连接共享 1.5 Mbps 链路。
- FTP 发送方不知道可容忍的最大速率 → FTP 数据的突发流量可能使路由器拥塞并导致音频丢失。
- 想要让音频优先于 FTP → 路由器如何判断一个数据包属于哪个应用?
原则 1:需要进行数据包标记(Packet Marking),以便路由器区分不同类别;并制定新的路由策略,按照类别对数据包进行处理。
原则 2:监管(Policing):让流量守规矩
Policing: Make flows behave
- 如果应用行为不当(例如音频发送速率高于声明速率)
– 流量监管:强制源端遵守带宽分配 - 在网络边缘进行标记和监管
原则 2:为一个流提供对其他流的保护(隔离 isolation)
原则 3:最大化效率
Maximise efficiency
为流分配独享带宽:
- 如果各个流没有使用完它们的分配带宽,会导致带宽利用效率低下。
原则 3:在提供隔离的同时,应尽可能高效地利用资源。
原则 4:不要过度分配
Don’t over-allocate
事实: 无法支持超过链路容量的流量需求!
原则 4: 呼叫准入(Call Admission):一个流会声明其需求。如果网络无法满足这些要求,可能会阻止该呼叫(例如返回忙音)。
QoS 基本功能模块
组成部分:
1️⃣ 呼叫准入 / 资源分配(Call Admission / Resource Allocation)
- SLA(服务级别协议)
- 用户向网络声明所需带宽
- 网络为用户进行带宽配置
2️⃣ 流分类(Flow Classification)
- 网络识别进入的分组(流),并为其分配预定义的服务等级
3️⃣ 流量监管与整形(Policing and Shaping)
- 网络监控流量,确保其符合声明的流量特性和已分配资源
4️⃣ 拥塞避免(Congestion Avoidance Mechanisms)
- 监控缓冲区使用率并调节流速,以缓解链路拥塞
5️⃣ 调度(Scheduling Mechanisms)
- 通过排队机制提供不同等级的服务
呼叫准入(接入控制)
在新的数据流(flow)进入之前,网络先检查自己是否还有足够资源(带宽、缓冲区、时延能力等)满足它的 QoS 要求。
如果可以满足,就允许进入;否则拒绝。
Call admission
▪ 控制平面(Control Plane)
向网络发送连接类型和 QoS 需求信号
网络负责主动带宽管理
- 建立连接路径
- 预留足够资源以满足 QoS 要求
- 随机预留(Stochastic reservation)
- 虚拟管道(Virtual pipes)
如果资源不足以满足需求,则拒绝该呼叫
▪ 示例:ATM,IntServ(RSVP),MPLS
流分类
Flow Classification
需要一种方法来识别数据包/分组,以便提供差异化处理。
分类标准示例:
- VC 号(Virtual Circuit number)
- MPLS 标签(MPLS Label)
- 服务类型(Type of Service)
- 协议(Protocol)
- 地址(Address)
- 源 IP 地址(Source IP Address)
- 目的 IP 地址(Destination IP Address)
- 端口号(Port Number)
- 源端口(Source port)
- 目的端口(Destination port)
- 入接口(Incoming interface)
QoS 实现技术
Techniques for QoS
- Classifier(分类器): 根据数据包头部的部分字段选择数据包。
- Marker(标记器): 根据流量类别对数据包头进行标记或重新标记。
- Meter(计量器): 检查流量是否符合流量规范,并将结果传递给标记器和整形器/丢弃器。
- Shaper(整形器): 通过在缓冲区中延迟数据包,使其符合流量规范。
- Dropper(丢弃器): 丢弃不符合流量规范的流量。
- Congestion Avoidance(拥塞避免): 检查缓冲区水平,并随机丢弃数据包。
- Scheduler(调度器): 允许对数据包进行差异化排队和服务。
监管与整形
Policing and Shaping
- Policing 的效果
监管后,超出速率的流量被限制或丢弃,流量速率被截断。 Shaping 的效果
整形后,流量被平滑化,通过延迟数据包使发送速率更加均匀。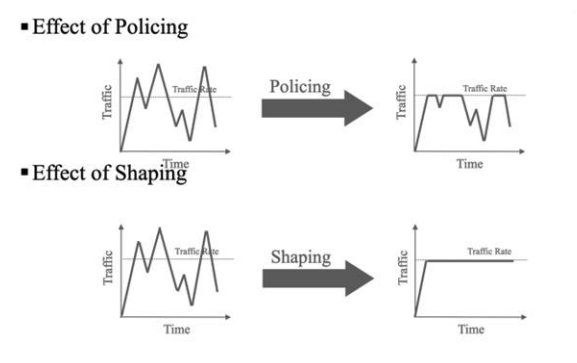
调度
Scheduling
简单优先级排队
Simple priority queuing
- K 个队列:
- $(1 \le k \le K)$
- 队列 k+1 的优先级高于队列 k
- 高优先级队列优先被服务
✓ 简单
✓ 开销低
- 相对优先级:没有确定性的性能界限
✗ 公平性和保护:
- 不满足 max-min 公平:低优先级队列可能发生饥饿(starvation)
加权轮询 WRR
Weighted round-robin (WRR)
不同队列按照不同权重分配带宽和发送机会。
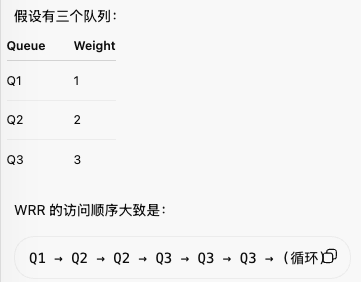
- 对广义处理器共享(GPS)的最简单近似实现
- 按照分配的权重比例,以轮询方式访问各个队列
- 不同的平均packet大小:每个队列的权重除以其平均分组大小
- 平均分组大小不可预测:可能导致不公平
- 长时间尺度上服务是公平的:每个流/队列必须被访问多次
缺额轮询 DRR
Deficit round-robin (DRR)
(1) Quantum(配额)
每个队列在一轮调度中允许发送的 数据量(字节数)。
(2) Deficit Counter(欠额计数器)
每个队列维护一个 deficit counter (dc),用于记录 之前剩余额度。
初始 dc = 0
DRR 的工作流程
假设有多个队列,每轮调度时执行以下步骤:
Step 1 额度递增: dc += quantum
Step 2 检查队首数据包:
如果:packet_size ≤ dc
则:发送该 packet,更新 deficit counter dc -= packet_size
否则:不发送,未使用的额度(credit)会累积到下一轮
- quantum(配额) 通常设为最大期望分组大小,使 每轮 每个 非空队列 至少发送一个分组
最适用于:
- 小分组大小
少量流
如果为队列分配了权重,则每个队列的 quantum 会乘以其对应的权重。
WRR(不是DRR) 的问题:
如果 packet size 不一样,就不公平。
例如:
| Queue | Packet Size |
|---|---|
| Q1 | 1500 B |
| Q2 | 64 B |
WRR 每次发 一个 packet:
结果:
Q1 实际带宽 >> Q2 |
因为 Q1 每次发送的数据量更大。
DRR 的解决方法:按照字节数而不是包数量调度。
加权公平排队 WFQ
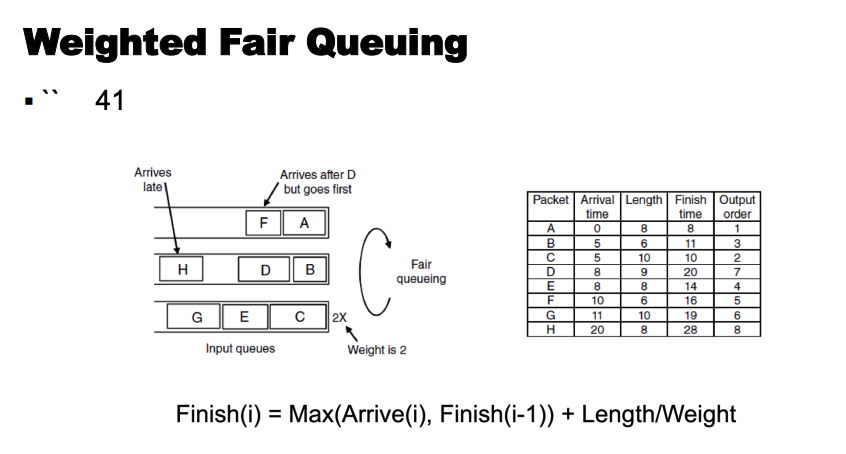
Weighted Fair Queuing (WFQ)
- 原理:
- 用“连续逐比特传输”的模型来为队列中的包计算完成时间(finish-number)
- 以轮询(round-robin)方式服务包
- 完成时间(Finish-number):
- 指在逐比特调度模型下,该分组本应完成服务的时间
- 每个分组都会被打上一个完成时间标签
- 在所有队列中,完成时间最小的分组优先被服务
- 轮次号(Round-number):
- 表示逐比特轮询服务器执行的轮次
- 完成时间由轮次号计算得到
- 如果队列为空:
- 完成时间 = 分组比特数 + 当前轮次号
- 如果队列非空:
- 完成时间 = 当前该队列中最大的完成时间 + 分组比特数
$F(i,k,t) = \max{F(i,k-1,t), R(t)} + P(i,k,t)$
- $F(i,k,t)$:流 $i$ 中在时间 $t$ 到达的第 $k$ 个分组的完成时间(finish-number)
- $P(i,k,t)$:流 $i$ 中在时间 $t$ 到达的第 $k$ 个分组的大小
- $R(t)$:时间 $t$ 的轮次号(round-number)
$F\varphi(i,k,t) = \max{F\varphi(i,k-1,t), R(t)} + \dfrac{P(i,k,t)}{\varphi(i)}$
- $\varphi(i)$:分配给流 $i$ 的权重
- $R(t)$ 的变化速率取决于活跃流的数量(以及它们的权重)
- 随着 $R(t)$ 的变化,分组将以不同速率被服务
流完成(队列为空):
- 轮次中少一个流,因此 $R$ 增加得更快
- 因此更多流完成, $R$ 增加得更快
- 迭代删除问题(Iterated deletion problem)
- 传输雪崩(Transmit avalanche)
- WFQ 需要在每个分组到达或离开时重新计算 $R$:
- 开销大
- WFQ 是唯一一种同时提出分组丢弃策略的调度器
- 缓冲区丢弃策略:
- 当分组到达且队列已满时
- 按完成时间(finish-number)从小到大的相反顺序(即按完成时间递减顺序)丢弃已在队列中的分组
- 可用于:
- 尽力而为(best-effort)排队
- 提供保证的数据速率和确定性的端到端时延
- WFQ 在“现实世界”中被使用
- 也有其他替代方案:
- 自时钟公平排队(SCFQ)
- 最坏情况加权公平排队(WF2Q)
此页正确性待定
基于类别的排队
Class-Based Queuing
- 分层链路共享(Hierarchical link sharing):
- 链路容量被共享
- 基于类别进行分配
- 基于策略进行类别选择
- 类别层次结构(Class hierarchy):
- 为每个节点分配容量/优先级
- 节点可以从父节点“借用”任何剩余容量
- 可以实现细粒度的流控制
- 注意: 这是一种排队机制,需要配合调度器使用
队列管理
- 拥塞(Congestion):
- 不守规矩的源
- 源同步现象
- 路由不稳定
- 网络故障导致重新路由
- 拥塞可能影响多个流(聚合流量情况下)
- 丢包(Drop packets):
- 丢弃“新到达”的分组直到队列清空?
- 接收新分组,丢弃队列中已有的分组?
丢包策略
Packet dropping policies
- 尾部丢弃(Drop-from-tail):
- 易于实现
- 队列中延迟较久的分组可能会“过期”
- 头部丢弃(Drop-from-head):
- 优先清除旧分组
- 适用于实时业务
- 对 TCP 更友好(可更早检测拥塞)
- 通常开销更大
- 随机丢弃(Random drop):
- 若所有源都正常行为则较公平
- 对不守规矩的源惩罚更重
- 清空队列(Flush queue):
- 丢弃队列中所有分组
- 简单
- 流应进行退避(back-off)
- “惩罚”不守规矩的流
- 效率低(会导致重传突发)
- 不适用实时业务
- 智能丢弃(Intelligent drop):
- 基于四层(传输层)信息
- 可能需要大量状态信息
- 更公平
随机早期检测 RED
- 随机早期检测(Random Early Detection):
- 在真正拥塞发生之前检测到拥塞
- 丢弃分组 → 作为提前的拥塞信号
- 源端降低发送速率
- 防止真正的拥塞发生
- 丢弃哪些分组?
- 监控各个流
- 在状态信息和处理开销的成本 与 网络整体性能之间进行权衡
类 TCP 的实时流自适应
TCP-like adaptation for real-time flows
- 类似 RED 的机制需要自适应的源端
- 如何指示拥塞?
- 丢包 —— 对 TCP 是可以的;对实时业务不合适(会损害实时流)
- 自适应机制:
- 在 IP 层使用显式拥塞通知(ECN)
- 分层音频/视频编码
- TCP 是单播;实时业务可以是多播
端系统对丢包的反应
End system reaction to packet drops
- 非实时 —— TCP:
- 丢包 → 拥塞 → 降低发送速率
- 慢启动 → 拥塞避免
- 网络运行良好
- 实时 —— UDP:
- 丢包 → 接收端填补(fill-in)
- 需要应用层拥塞控制
- 数据速率自适应可能不适合音频/视频
- 实时流可能不进行自适应 → 损害自适应流
- 队列管理可以保护自适应流:
- 需要智能队列管理
QoS 协议案例
QoS and the Internet: Protocol case studies
IP QoS
- 性能保障(Performance Guarantees)—— 交付目标
- 吞吐量(Throughput)、时延/抖动(Delay/Jitter)、丢包率(Packet Loss)
- 服务等级(Service Levels)
- 尽力而为(Best Effort)
- 对所有流量公平
- 无任何保证
- 定性(Qualitative)
- 低时延,优于 Best Effort
- 类似奥运分级的服务类别——金/银/铜
- 相对保证
- 定量(Quantified)
- 单向时延 < 100ms,丢包率 < 1 × 10⁻⁶
- 明确量化的保证
- 尽力而为(Best Effort)
RSVP:资源预留协议
Resource ReSerVation Protocol
- 资源预留可以实现:
- 端到端的保证服务
- 带宽需求(单播)
- 带宽需求指示(多播)
- 为什么需要这样的协议?
- 支持服务质量(QoS)
- 实时应用需要跨网络的有保障数据流
- 基于网络的流量过滤
什么是资源预留(Reservation)?
在一条路径(或多播树)上的路由器中进行配置,使其能够区分不同数据包并进行转发
功能:
根据过滤规范(filter specifications)对到达的数据包进行分类
- 根据流规范(flow specifications)调度数据包的发送
- 通过接纳控制(admission control)限制流的数量
- 应用策略以优先处理接纳请求
RSVP 的问题
- 可扩展性(Scalability)
- 需要为每个微流(microflow)维护状态,并进行软状态刷新(soft state refreshes)
- ➤ 对骨干网来说是问题,但对校园/企业网络影响较小
- 在共享介质网络中效果不佳
- 因此需要 SBM(子网带宽管理器,Subnetwork Bandwidth Manager)
- ……但在点对点链路网络中运行良好
IP QoS 方法
IntServ:通过 RSVP 为每个 flow 进行端到端资源预留,以提供明确的 QoS 保证。
Performs end-to-end resource reservation for each flow via RSVP to provide explicit QoS guarantees.
DiffServ:把流量分类并标记为不同服务等级,让路由器按类别提供差异化转发服务。
Classifies and marks traffic into different service levels, allowing routers to provide differentiated forwarding services by category.
IntServ
综合服务(Integrated Services, IntServ)
IntServ 的核心思想是:每条流(flow)在发送前都要先申请资源,比如带宽、延迟、丢包率要求。网络中的每个路由器都要为该流保存状态,并决定是否能满足需求。
- 端到端资源预留
- 受传统电信网络思想影响
- 基本单位是“流”(flow)
DiffServ
区分服务(Differentiated Services, DiffServ)
DiffServ 不再关心每一条流,而是把流量分成几个等级,例如:
- 高优先级:语音、视频
- 中优先级:普通网页
- 低优先级:邮件、下载
进入网络时,边缘路由器会给数据包打上 DSCP 标记。之后核心路由器只看这个标记,决定给予什么样的转发优先级。
- 架构与 IP 架构相匹配
- 无显式资源预留:每个节点自行提供机制以实现所需的 QoS 行为
- 基本单位是“聚合”(aggregate,即一组流)
- 认识到互联网由多个独立管理的域组成
- 显式建模域(AS)边界
- 策略和控制在域边界处进行
IntServ
架构组成
IntServ Architecture Components
- QoS 需求(QoS Requirements)
- 以流量规范(TSpec)和服务规范(RSpec)表示
- 二者合称为 FlowSpecs
- 资源预留协议(RSVP)
- 用于在 IntServ 传输路径中的各节点之间交换 QoS 需求
- IntServ 不是唯一使用 RSVP 的 QoS 体系;RSVP 也可用于其他 QoS 控制架构
- 资源共享要求(Resource-sharing requirements)
- 资源分配基于每流(per-flow)
- 多个流共享同一链路 —— 必须保证公平性
- ➤ 使用加权公平队列(WFQ)
- 丢包控制机制(Allowances for packet dropping)
- 提供对丢包策略的控制
- 例如:将某些数据包标记为可抢占(pre-emptable)
服务类型
Integrated Services
- IntServ 支持两种服务类型:
- 保证服务(Guaranteed Service,RFC2212)
- 有界时延(delay bounded)且无丢包
- 适合实时应用
- 受控负载(Controlled Load,RFC2211)
- 服务效果等同于“轻载”的尽力而为网络
- 面向对实时性较为宽容的应用
- 在一定程度上保护各流之间互不干扰
- 不需要 RSpec 规范
- 保证服务(Guaranteed Service,RFC2212)
DiffServ
架构
Differentiated Services Architecture
- DiffServ 网络支持少量的服务类别。
- 各服务类别具有相对优先级。
- 进入 DiffServ 域的流量会被分类到某一服务类别。
- 服务类别通过 DiffServ Code Points(DSCP) 区分 —— 位于 IPv4 头部中的 6 位字段。
- 即 TOS(Type of Service)字段中最高有效的 6 位。
- 服务类别通过 DiffServ Code Points(DSCP) 区分 —— 位于 IPv4 头部中的 6 位字段。
- 每个服务类别在每个路由器上都会获得特定的转发处理方式:
- 根据与该 DSCP 关联的 每跳行为(Per-Hop Behaviour, PHB) 来决定。
服务类别与 DSCP 对照表
| 服务类别 | DSCP 名称 | DSCP 值 | 应用示例 |
|---|---|---|---|
| 网络控制 | CS6 | 110000 | 网络路由 |
| 电话 | EF | 101110 | IP 电话承载 |
| 信令 | CS5 | 101000 | IP 电话信令 |
| 多媒体会议 | AF41, AF42 | 100010, 100100 | H.323/V2 视频 |
| 会议(自适应) | AF43 | 100110 | 视频会议(自适应) |
| 实时交互 | CS4 | 100000 | 视频会议、互动游戏 |
| 多媒体流媒体 | AF31, AF32, AF33 | 011010, 011100, 011110 | 点播音视频 |
| 广播视频 | CS3 | 011000 | 广播电视、直播 |
| 低时延 | AF21, AF22 | 010010, 010100 | 客户端/服务器事务 |
| 数据 | AF23 | 010110 | Web 订单 |
| OAM | CS2 | 010000 | 运维管理(OAM&P) |
| 高吞吐数据 | AF11, AF12 | 001010, 001100 | 存储与转发类应用 |
| 数据 | AF13 | 001110 | 存储与转发类应用 |
| 标准 | DF(CS0) | 000000 | 未区分的普通应用 |
| 低优先级数据 | CS1 | 001000 | 无带宽保证的流量 |
术语
Terminology
DiffServ 基于流量分类(traffic classification)原则,将每个数据包划分流量类别。
流量调节器(Traffic Conditioner):
- 分类(Classification)
- 计量(Meter)
- 标记(Mark,DSCP)
- 监管 / 整形(Police / Shaping)
逐跳行为(Per Hop Behaviour, PHB):
- 资源分配(Resource Allocation)
- 分组丢弃策略(Packet Drop Policy)
域行为(Per Domain Behaviour):
- 端到端性能(E2E Performance)
- 作为 SLS(Service Level Specification,服务级别规范)的基础
原理
Rationale
DiffServ 的前提:
- 复杂功能(如分类和policing)由边缘路由器(edge routers)执行。
- 核心路由器(core router)不需要进行分类和监管,因此核心部分保持简单。
- 核心路由器仅根据数据包的标记应用 PHB(逐跳行为)处理。
PHB 处理通过核心路由器结合调度策略(scheduling policy)和队列管理策略(queue management policy)来实现。 - 一组实施统一、由管理方定义的 DiffServ 策略的路由器称为一个 DiffServ 域(DiffServ domain)。
流量调节器
Traffic Conditioner
流量调节器通常位于 DiffServ 域的边缘(edges of DiffServ domains)。
组成部分:
- Classifier(分类器):检查数据包头部
- Meter(计量器):检查流量是否符合速率要求(rate conformance)
- Mark(标记器):设置 DSCP 值
- Shaper / Dropper(整形器 / 丢弃器):将不符合规范的流量调整为符合规范的流量(或进行丢弃)
逐跳行为 PHB
Per Hop Behaviour, PHB
- 节点对数据包的对外可观察的转发行为
PHB 由三个因素决定:
- 提供负载(offered load)→ 取决于流量调节(Traffic Conditioning)
- 资源分配(resource allocation)→ 取决于输出队列上的调度器(scheduler)
- 分组丢弃策略(packet discard policy)→ 取决于拥塞避免机制(congestion avoidance mechanisms)
已标准化的三种 PHB:
- Expedited Forwarding(EF)
- Assured Forwarding(AF)
- Class Selector(用于与 IP Precedence 向后兼容)
加速转发(Expedited Forwarding, EF)
EF 提供:低丢包、低时延、低抖动、保证带宽的端到端(E2E)服务
➢ 类似“虚拟专线服务”(Virtual Leased Line Service)EF 要求:最大到达速率 < 最小离开速率
➢ 到达速率由 Traffic Conditioner(流量调节器) 控制
➢ 离开速率由 PHB 调度器 控制
• 严格优先级(strict priority)
• 加权公平排队(WFQ)
• ……
确保转发 Assured Forwarding(AF)
- 通过控制丢包概率来提供转发保障
➢ 可以使用 RED(随机早期检测)
➢ 已定义 四个类别(Classes)
➢ 每个类别最多有 三种丢弃概率
➢ 每个类别具有一个排序约束 - 可用于构建“奥运型(Olympic)”服务
➢ 每种颜色对应一个类别
➢ 通过流量调节(Traffic Conditioning)确保 Gold 的提供负载小于 Silver,从而为 Gold 设计更低的平均时延
[Eg. IntServ or DiffServ]
来源:EENGM4211 2023 Q9
答案由 AI 生成
Q9: Which one of IntServ or DiffServ is suitable for Real-time applications? Justify your answer. (7 Pts)
Answer: IntServ, because it can reserve resources end-to-end and provide guaranteed service with bounded delay and no loss, which real-time applications require.
数据中心网络
流量特性 ※
Describe network traffic characteristics that influence the design of the data centre network
- 应用 Application: 运行在 DC 中的应用取决于DC的类别 Applications in the data centers depend on the data center category
- 流量局部性 Traffic flow locality:描述流量是 机架内 还是 机架间。It descibes traffic is intra-rack or inter-rack
- 流量大小和持续时间 Traffic flow size & duration: 大多数流量很小,且持续时间小于几百毫秒。 Most traffic flow sizes are small and last under a few hundreds of milliseconds
- 并发流 Concurrent traffic flow: 并发流的数量对网络拓扑有影响
- 包大小 Packet size: 包大小为双峰分布 packet size exhibit a bimodal pattern
- 链路利用率 Link utilization: 机架内和汇聚层的链路利用率低,核心层的链路利用率高。 Link utilization in rack and aggregate level is low, while it on the core level is high
3-Tier 架构
Typical 3-Tier Architecture
DCN 的典型架构
注意:此图需要会画
- 底层:Servers放置在机架中,通过 机架顶部交换机(Top-of-Rack,ToR) 连接,使用 1Gbps 或 10Gbps 链路。
- 中层:ToR 交换机 通过 10Gbps 链路 以树形拓扑连接到一个或多个 行末交换机(End-of-Row,EoR) 或 汇聚交换机(aggregate switches)。
- 上层:Core switches 用于连接各个 汇聚交换机。
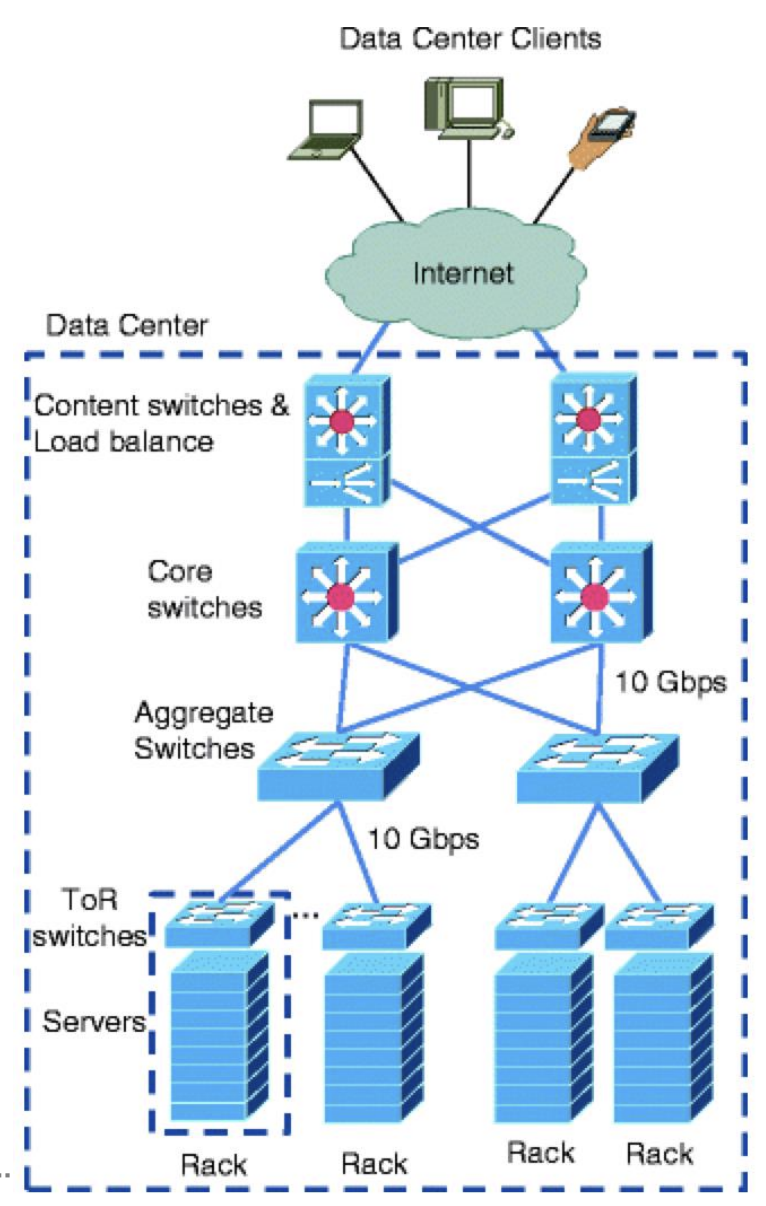
优缺点 ※
优点: 易扩展 scalable,容错 Falut tolerant
缺点: 高延迟 latency,高功耗 power,过订阅 overscribe,跨子网迁移很痛苦 Moving across Subnets is painful
ToR EoR ※
机架顶部交换机 Top of Rack Switches, ToR
ToR:每个机柜顶部放一个交换机,每个 rack 单独接入网络
EoR:一整排机柜共用一个交换机,交换机放在机柜排末端
简单理解:
ToR = “每个机柜自己带一个交换机”
EoR = “一整排机柜共享一个交换机”
行末交换机 End of Row, EoR
交换机放在一整排机架末端
多个机架的服务器通过长网线连接到行末的 EoR 交换机
| Architecture | TOR | EOR/MOR |
|---|---|---|
| Advantages | • 布线简单,电缆维护方便,并具有高可扩展性 • 基于机柜的模块化管理,故障影响范围较小 | • 管理简单,可靠性高• 接口利用率高 |
| Disadvantages | • 端口浪费•管理复杂 | • 布线复杂,维护困难• 故障影响范围较大 |
过订阅 ※
Oversubscription
Network oversubscription refers to a point of bandwidth consolidation where the ingress bandwidth is greater than the egress bandwidth.
网络过订阅是指一种带宽汇聚情况,其中入口带宽大于出口带宽。
Oversubscription ratio is defined by the ratio of ports facing downwards vs. ports facing upwards (with equal bandwidth ports).
过订阅由朝下端口与朝上端口的比率定义(在端口带宽相等的情况下)。
通常过订阅比 > 1
当过订阅比太大时,造成的问题:Switch up-links get heavily loaded due to the poor bisection bandwidth. 交换机上行负载太大,由于差的二分带宽
典型的过订阅比
• ToR 上行链路过订阅比 4:1 到 20:1
• EoR 上行链路过订阅比 4:1
Eg. 过订阅
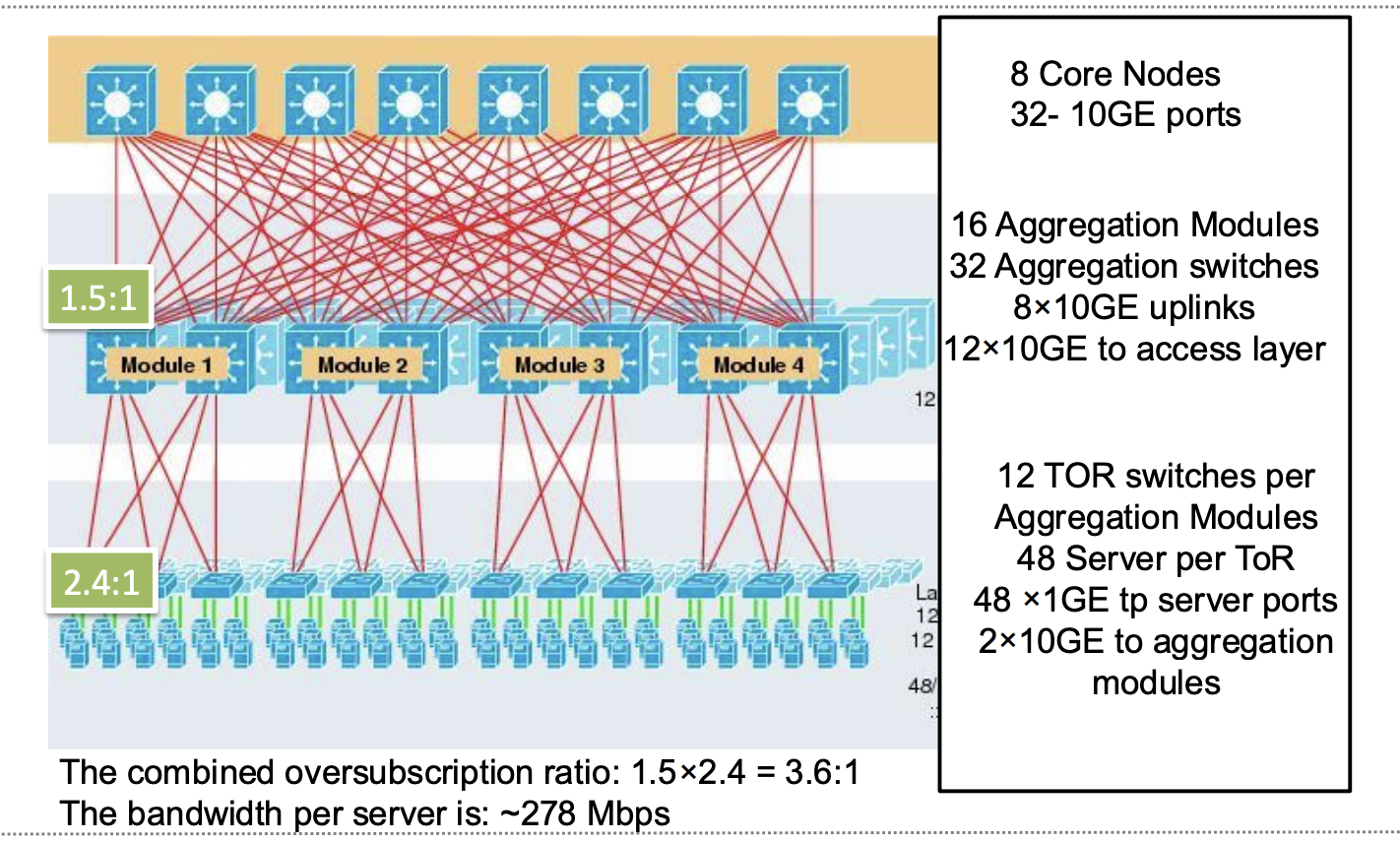
- Core layer(核心层):8 个核心交换节点,每个有 32 个 10GE 端口
- Aggregation layer(汇聚层):16 个汇聚模块 / 32 个汇聚交换机
- Access layer(接入层):ToR 交换机连接服务器
图中每个ToR交换机有48 x 1GE下行(到服务器)带宽,但上行(到汇聚module)带宽为2 x 10GE
过订阅比=48/20=2.4
每个Aggregation交换机有12 x 10GE下行(到ToR层),8 x 10GE上行(到Core层)
过订阅比=120/80=1.5
总过订阅比=2.4*1.5=3.6
因此 每个服务器G口平均带宽 1000/3.6=277.8 Mbps
数据转发
• Layer 3 方法
• 根据主机直接连接的交换机,以层次化方式为主机分配 IP 地址。
• 使用标准的域内路由协议,例如 OSPF。
• 管理开销较大
• Layer 2 方法:
• 基于扁平 MAC 地址进行转发
• 管理开销较小
• 可扩展性差且性能低
• 二层与三层之间的折中方案:
• VLAN:一种在二层网络中定义广播域的技术
• 适用于较小规模的拓扑
• 资源分区问题
[Eg. 3-Tier/过订阅/叶脊]
来源:M0008 2022 Q1
Figure 1 shows the typical 3-Tier data center architecture.
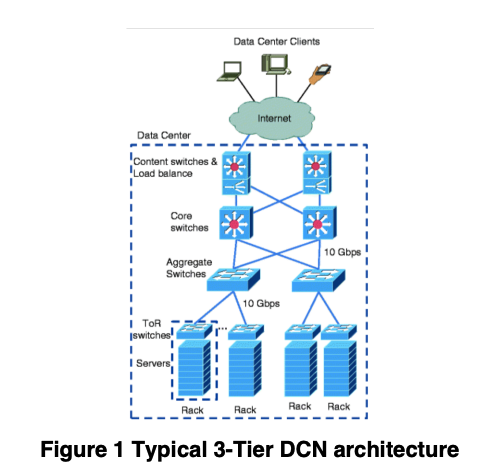
(a) Discuss the advantages and disadvantages of this architecture. (6 marks)
Advantages: scalable, Fault tolerant
Dis-advantages:
- oversubscribe
- Moving across Subnets is painful
- High power consumption
- High latency

(b) Define the oversubscription ratio in DCNs. (2 marks)
过订阅比 一般情况下大于等于1
Oversubscription ratio is defined by the ratio of ports facing downwards vs. ports facing upwards (with equal bandwidth ports).
[
\text{Oversubscription ratio}=\frac{\text{Downlink bandwidth}}{\text{Uplink bandwidth}}
]
(c) Figure 2 shows an example of DCN based on 3-tier DCN architecture. The core switches are 10 Gigabit Ethernet switches. Each access switch has 4 × 10GbE links that are connected to the two core switches. In each access node, 336 servers connect to one access switch with GbE links. Calculate the oversubscription ratio in the access switch. (6 marks)
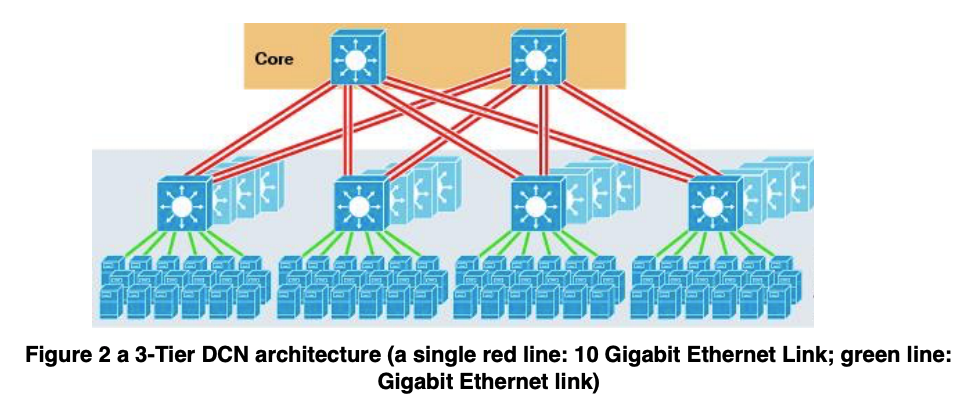
Answer:
Downlink bandwidth = 336 Gbps
Uplink bandwidth = 40 Gbps
Oversubscription = 336 / 40 = 8.4
(d) Describe network traffic characteristics that influence the design of the data centre network. (6 marks)
- 应用(Applications):数据中心中运行的应用取决于数据中心的类型(校园/私有/云计算)
- 流量局部性(Traffic flow locality):描述流量是在同一机架内(intra-rack),还是不同机架之间(inter-rack)
- 流量大小与持续时间(Traffic flow size and duration):流量流(traffic flow)是指两个或多个服务器之间的活跃连接。
- 并发流(Concurrent traffic flows)
- 包大小(Packet size)
- 链路利用率(Link utilization)
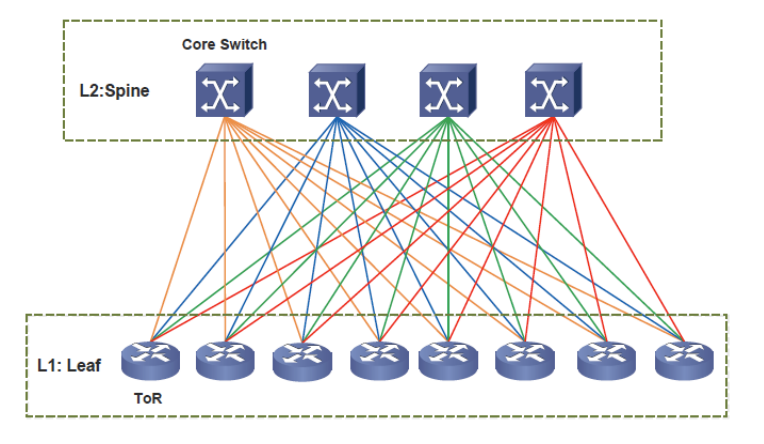
(e) Draw a spine-leaf data center architecture and discuss how the spine-leaf architecture supports the east-to-west traffic inside DCNs. (6 marks)
Answer:
Spine-leaf supports east-west traffic because every leaf connects to every spine. Server-to-server traffic goes leaf → spine → leaf, so it has multiple paths, higher bandwidth, predictable latency.
图(注意每一个 Leaf 都连接到所有 Spine,像神经网络全连接层)
[Eg. EoR/ToR/过订阅]
来源:M0008 2019 Q1
Q1: Understanding architecture of data centre networks (DCNs)
(a) End of Row (EoR) switch and Top of Rack (ToR) switch are two common access switching architectures inside data centers. List at least two advantages and disadvantages of both architectures.
参考 End of Row的末尾的表格。
两种优缺点正好相反
ToR 机架顶部:
优点:simple cabling & maintenance, small-scale fault impact
布线和维护简单,故障影响小
缺点:Port waste, complex management
浪费端口,管理复杂
EoR 行末:
优点:simple management, high interface use
缺点:complex cabling & maintenance, large-scale fault impact
(b) Define the oversubscription ratio in DCNs. Discuss the main reasons to introduce(介绍 引入) over-subscription in DCN and the corresponding issues due to a large over-subscription ratio.
Oversubscription ratio is defined by the ratio of ports facing downwards vs. ports facing upwards (with equal bandwidth ports).
reasons to intro 过订阅:
- To allow multiple servers share the same switches to improve the utilization efficiency of the switches, and therefore the total cost can be reduced. 允许多个服务器共享交换机来提升交换机利用率,来减少总成本
issues:
- Switch up-links get heavily loaded due to the poor bisection bandwidth. 交换机上行负载太大,由于差的二分带宽
[Eg. 3-Tier]
来源:EENGM0008 2018 Q1
答案为官方答案
Q1: Figure 1 show a design of a 3-tier DCN architecture. The core switches use 10 Gigabit Ethernet and scale to 32 Access nodes. Each access nodes connects 336 servers with Gigabit Ethernet links. (10 marks)
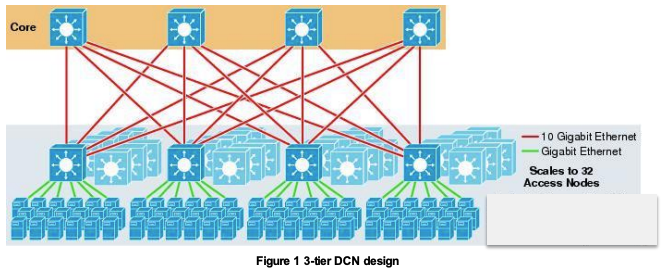
(a) Discuss the advantages and disadvantages of this architecture. (3 Marks)
Advantages: scalable, Fault tolerant 可拓展,容错
Dis-advantages:
- oversubscribe 过订阅
- Moving across Subnets is painful 在子网中迁移很painful
- High power consumption 高功耗
- High latency 高延迟
(b) Define the oversubscription ratio in DCNs. Calculate the oversubscription ratio for the access switch in Figure 1. (2 Marks)
注意看图,access switch 上行有 4 个 10G 口,下行为 336 个 G 口
Oversubscription ratio is defined by the ratio of ports facing downwards vs. ports facing upwards (with equal bandwidth ports).
Oversubscription ratio = 336:40 = 8.4:1
(c) Discuss the main reason to introduce over-subscription in DCN and the corresponding issues due to a large over-subscription ratio. (3 marks)
Oversubscription is introduced to allow multiple servers share the same switches to improve the utilization efficiency of the switches, and therefore the total cost can be reduced.
Issues: Switch up-links get heavily loaded due to the poor bisection bandwidth
由于二分带宽不足,上行链路负载严重增加
(d) Calculate the maximum available bandwidth and the average available bandwidth for each server. (2 Marks)
Maximum bandwidth=1Gbps
Average bandwidth =40/336 Gbps = 120Mbps(答案如此,实际上是(0.119Gbps))
[Eg. 3-Tier]
来源 EENGM0008 2016 Q1 (a) (b)
本题答案为官方答案
(a) With the aid of a diagram explain the typical architecture of the current Data Centre Network. List the advantages and disadvantages.
图:注意到Aggregate - ToR是1对多,Content switches & Load balance - Core - Aggregate 是全连接
此外 合理怀疑Content switches不用画
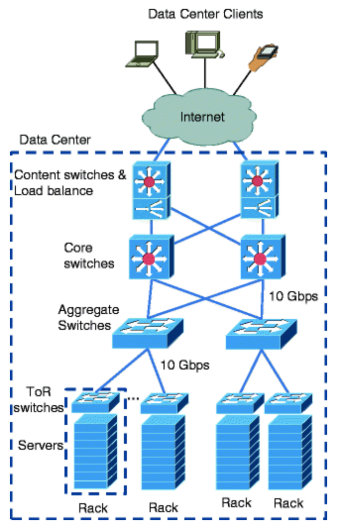
优点:scalable、Fault tolerant
缺点:High power consumption、High latency
答案中写的是 Fat-Tree,但课件中未提及这张图是 Fat-Tree


(b) Describe four network traffic characteristics that influence the design of the data centre network.
此题答案很长。而且部分内容没有在课件中出现过。


简略版:
- 应用 Application: 运行在 DC 中的应用取决于DC的类别 Applications in the data centers depend on the data center category
- 流量局部性 Traffic flow locality:它描述流量是 机架内 还是 机架间。It descibes traffic is intra-rack or inter-rack
- 流量大小和持续时间 Traffic flow size & duration: 大多数流量很小,且持续时间小于几百毫秒。 Most traffic flow sizes are small and last under a few hundreds of milliseconds
- 并发流 Concurrent traffic flow: 并发流的数量对网络拓扑有影响
- 包大小 Packet size: 包大小为双峰分布 packet size exhibit a bimodal pattern
- 链路利用率 Link utilization: 机架内和汇聚层的链路利用率低,核心层的链路利用率高。 Link utilization in rack and aggregate level is low, while it on the core level is high
叶-脊架构
Leaf and Spine Architecture
Fat-tree
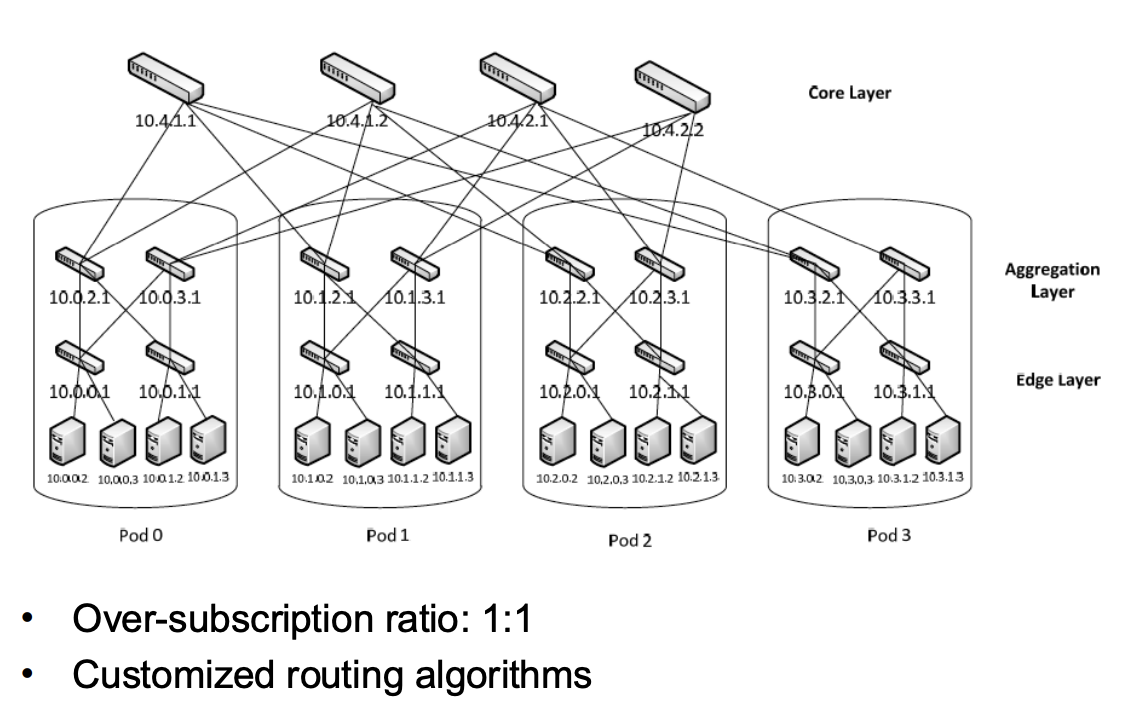
这页图在说明 Fat-tree 数据中心网络架构 的特点:
- 结构组成
- Edge layer(边缘层):直接连接服务器
- Aggregation layer(汇聚层):连接多个边缘交换机
- Core layer(核心层):连接所有 Pod
- Pod 概念
- 数据中心被划分为多个 Pod(Pod0、Pod1、Pod2、Pod3)
- 每个 Pod 内包含:
- Edge 交换机
- Aggregation 交换机
- 一组服务器
- 全互联结构
- Pod 内:Edge ↔ Aggregation 全连接
- Pod 外:Aggregation ↔ Core 全连接
- 因此形成很多 等价路径(multipath)
- 关键特点
- 过订阅比:1:1
- 上行带宽 = 下行带宽
- 不会像三层架构那样出现严重瓶颈
- 需要定制路由算法
- 用于在多条路径之间进行负载均衡
- 过订阅比:1:1
- 核心思想
- 使用大量廉价交换机构建 高带宽、可扩展的数据中心网络
- 通过 多路径 + 无过订阅 提升性能。
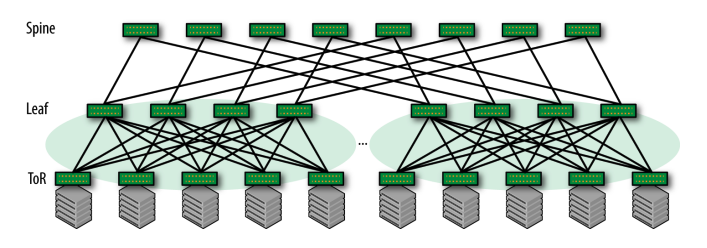
叶脊网络
Leaf-spine network
这页在说明 Leaf–Spine 数据中心网络架构 的基本结构和一个重要性质。
- 网络结构
图中只有 两层交换机:
- Leaf(叶交换机)
- 位于底层
- 直接连接服务器
- Spine(脊交换机)
- 位于上层
- 负责连接所有 Leaf
关键特点:
- 每一个 Leaf 都连接到所有 Spine
- Leaf 之间 不直接连接
因此形成 大量等价路径(multi-path)。
- Non-blocking architecture(无阻塞架构)
如果交换机有 n 个端口,Leaf-Spine 网络最多可以连接:$\frac{n^2}{2}$ 台服务器。
- Leaf → Spine 有 多条路径
- 服务器之间通信时不会固定走一条路径
- 可以通过 ECMP / load balancing 分散流量
所以:理论上任何服务器对之间都可以同时通信而不会堵塞。
Leaf-spine 网络
优点
• 简化网络布线
• 基于 Clos 的网络结构,具有相同的时延
• Spine 交换机和 Leaf 交换机都可以轻松扩展
• 流量经过相同数量的设备,时延可预测
• 每一层可以使用相同类型的交换机
缺点
• 水平扩展能力取决于高端口数量的 Spine 交换机设计
3-Tier 叶-脊网络
PPT中没有文字说明
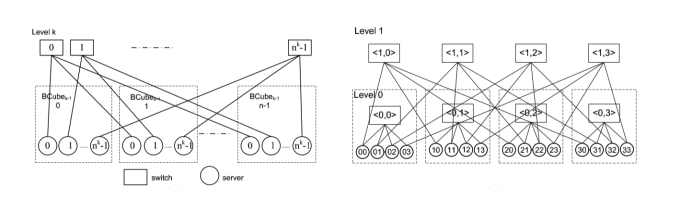
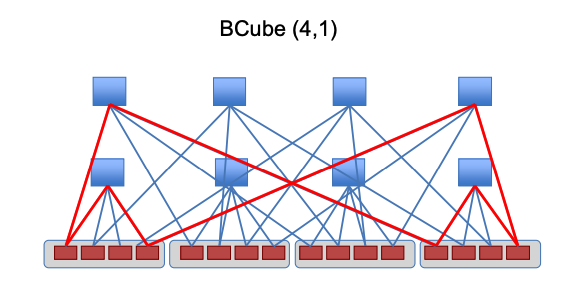
Server-Centric 架构
BCube
• 主要目标:用于基于集装箱的模块化数据中心的网络架构
• BCube 构造:层级结构
• BCubeₖ 由 BCubeₖ₋₁ 递归构造而成
• 服务器中心型:
• 服务器执行路由和转发
• 考虑多种通信模式
• 一对一、一对多、一对所有、全互连
• 单路径和多路径路由
BCube 拓扑构建
• 递归结构:
BCubeₖ 由 n 个 BCubeₖ₋₁ 和 nᵏ 个 n 端口交换机 递归构建而成。
有点抽象 具体见PPT
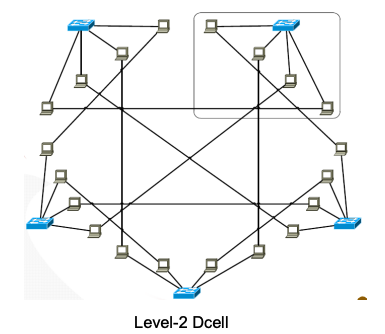
DCell
• 一种极其可扩展的架构。一个 3 层的 DCell(如果 DCell₀ 中有 6 台服务器)可以容纳 大约 326 万台服务器。
• 一种混合路由与数据处理协议。
互联网络
如何构造网络
步骤 1:拓扑(Topology)
- 交叉开关(Crossbar)
- 环形(Ring)
- 二维和三维网格或环面(2-D / 3-D mesh 或 torus)
- 超立方体(Hypercube)
- 树形(Tree)
- 蝶形(Butterfly)
- 完美洗牌网络(Perfect shuffle)等
步骤 2:路由算法(Routing algorithm)
- 例子:在 2D 环面网络(2D torus) 中
- 先沿 东西方向(east-west) 路由,再沿 南北方向(north-south) 路由
- 这样可以 避免死锁(deadlock)
步骤 3:交换策略(Switching strategy)
- 电路交换(Circuit switching):整个消息传输期间都会预留完整路径
- 分组交换(Packet switching):将消息拆分成多个独立路由的数据包
步骤 4:流量控制(Flow control)
- 将数据暂时存储在 缓冲区(buffers)
- 将数据 重新路由到其他节点
- 告诉 源节点暂时停止发送
- 丢弃数据 等
术语
Terminology
- 节点(Node)
- 连接到路由器/交换机的网络端点
- 网络接口(Network interface)
- 将端点(例如 CPU 核心)连接到网络
- 将计算与通信解耦
- 链路(Links)
- 用于传输信号的一束导线
- 交换机 / 路由器(Switch / router)
- 将固定数量的输入通道连接到固定数量的输出通道
信道 / 路径 / 路由(Channel / path / route)
- 路由器或交换机之间的一条逻辑连接
- 所有源节点和目的节点之间的平均跳数(hop count)
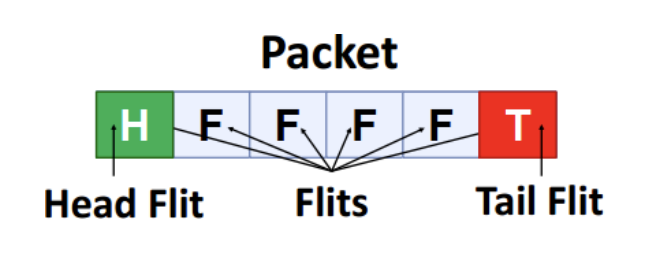
消息(Message)
- 网络客户端(例如 CPU 核心、内存)的传输单位
- 数据包(Packet)
- 网络中的传输单位
- Flit(流控单元)
- Flow control digit(流控制数字)
- 网络内部流量控制的单位
(图示:一个 Packet 由多个 Flit 组成,包括 Head Flit(头部 flit)、中间 Flits 和 Tail Flit(尾部 flit)。)
Step 1: 拓扑
直接网络与间接网络
Direct & Indirect Networks
- 直接网络(Direct):每个交换机同时也是一个网络端点(end points)
- 例:Mesh(网格)、Torus(环面)、Hypercube(超立方体)
- 间接网络(Indirect):并非所有交换机都是网络端点
- 例:Butterfly(蝴蝶网络)、Fat Tree(胖树)、Clos 网络
拓扑
Topology
- 定义:决定网络中信道(channels)和节点(nodes)的排列方式
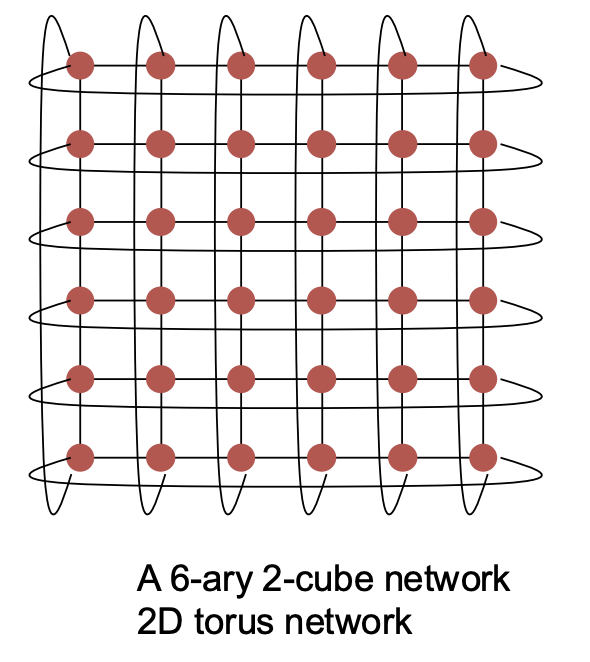
图示:一个 6-ary 2-cube 网络(二维环形网络 / 2D torus network)
关键指标
直径(Diameter):网络中任意两个节点之间最短路径中的最长一条。
所有节点里最难到达的一对节点,它们的最短路径
平均路由距离(Average routing distance):所有有效路由路径中的平均跳数(hop 数)。
- 二分带宽(Bisection bandwidth)
二分带宽 ※
Bisection bandwidth
做题可用:对分带宽是将网络切成节点数量相等的两半时,被切断的链路数量(的最小值)
- 网络的二分带宽是指:当将整个网络或终端节点几乎平均分成两部分时,这两个部分之间可用的带宽。
- 二分带宽 $B_b$ :在所有可能的网络二分方式中,最小的带宽值。
- 信道二分数(channel bisection) $B_c$ :在所有可能的网络二分方式中,最小的信道数量。
- 在网络成本模型(network cost model)中,网络的二分带宽表示实现该网络所需的全局布线数量。
- 二分带宽对所有processor都需相互通信的算法非常重要。
- 为什么它重要:如果网络流量是完全随机的,那么一条消息跨越两个网络半区的概率是 1/2。
- 如果所有节点都发送消息,那么二分带宽需要达到 $N/2$。

[Eg. 性能指标]
来源:EENGM0008 2016 Q2(a)
(a) Network topologies influence the performance of a Data Centre.
(i) Describe four key performance properties that are used to evaluate a network topology.
- Diameter: the maximum (over all pairs of nodes) of the shortest path between a given pair of nodes. 给定任意两点之间最短路径的最大值(对所有节点对而言)
- Latency: delay between send and receive times 发送和接收时间之间的delay
- Bandwidth of a link = w * 1/t
- Bisection bandwidth: bandwidth across smallest cut that divides network into two equal halves 将网络分成两等份的最小割上的带宽
- Degree: maximum degree of any node in the network 网络中any节点的最大度
- Cost: number of total links in the network 网络中的总links数

Backplane 背板
- 二分带宽(Bisection bandwidth)给出了整个系统中实际可用的带宽,反映瓶颈带宽(bottleneck bandwidth)。
- 在设计时需要考虑物理限制(physical limitations)。
Mesh 与 Torus
(k-ary n-cube)
Mesh: 网格拓扑
Torus: 环形网络
k-ary n-cube 是一种描述 mesh / torus 网络拓扑的方法。
- k 表示每个维度上有多少个节点
- n 表示网络有多少维
6-ary 2-cube:表示二维网络,每个维度有 6 个节点,所以总共有 36 个节点
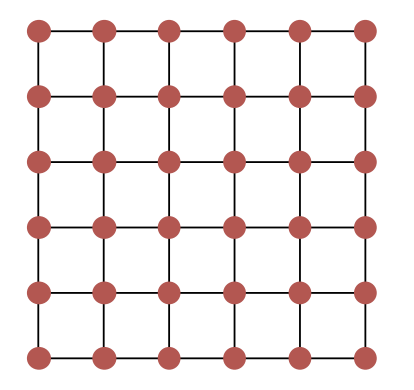
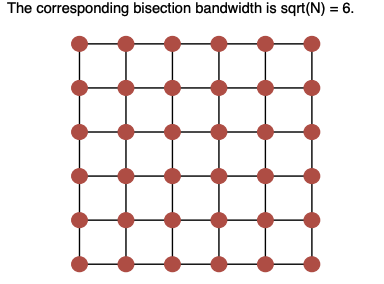
二维 Mesh(k-ary 2-cube)
直径可以用定义来算, (6-ary, 2-cube)直径显然=10
二分带宽,直接从中间切一刀,被切断的link数=6
- 节点数:$N = k^2$
- 其中 $k$ = 每个维度上的节点数
- 直径(Diameter):$2 \times (\sqrt{N} - 1)$
- 二分带宽(Bisection bandwidth):$\sqrt{N}$
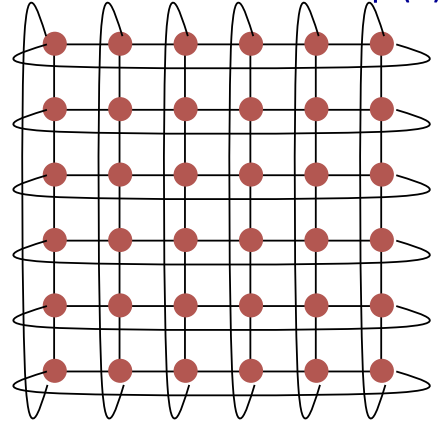
2D Torus(k-ary 2-cube torus)
直径可以用定义来算, (6-ary, 2-cube) torus,考虑左上和右下两点,由于左上连接到右上,所以左上到右下只需要走6个单位的距离,直径=6
二分带宽,直接从中间切一刀,被切断的link数=12
节点数:$N = k^2$
其中 $k$ = 每个维度上的节点数
直径(Diameter):$\sqrt{N}$
二分带宽(Bisection bandwidth):$2 \times \sqrt{N}$
3D Torus
(k-ary d-cube,d=3)
在 3D torus 中,每个计算节点都连接到 6 个邻居节点。
位于 torus “边缘”的节点仍然连接到 6 个邻居,只是通过较长的环绕连接(wrap-around links)实现。
节点数量:$N = k^3 = 4^3 = 64$
3D Torus 的直径(Diameter):$\lfloor k/2 \rfloor \times 3 = 6$
二分带宽(Bisection bandwidth):$2 \times N^{(d-1)/d}$$= 2 \times 64^{2/3} = 32$

提高维度的影响
总节点数 N = k^n
优点:维度n++ => 节点邻居 neighbours of node ++
=> 路径多样性 path diversity ++ => 直径 diameter — => 延迟 latency —
且 => 对分带宽 bisection bandwith ++
缺点:Increase router ports增加端口 , high cost 高成本, complex wiring 复杂布线
[Eg. 6-ary 2-cube Mesh/Torus]
来源:M0008 2022 Q2
Figure 3 shows a 6-ary 2-cube 2D mesh network with N=36 node.
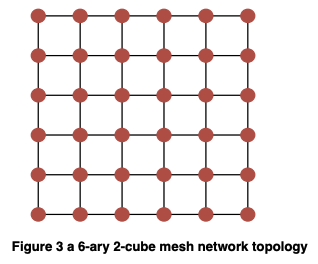
(a) Calculate the corresponding channel bisection bandwidth. (4 marks)
公式法:bisection bandwidth = sqrt(节点数) = sqrt(6*6) = 6
瞪眼法:中间切一刀,被切断的链路最小值显然为6
(b) Provide a deterministic routing algorithm for this topology and discuss the advantages and disadvantages of the provided routing algorithm. (6 marks)
参考
deterministic routing algorithm: Dimension Order Routing 维序路由
优点:simple, short path, avoid deadlock 简单 路径短 避免死锁
缺点:poor load balancing 负载均衡差
(c) Draw a 6-ary 2-cube Torus network and calculate its bisection bandwidth. (4 marks)
图:把一条链路的两端节点也连起来
bisection bandwidth:
公式法:两倍 sqrt(节点数) = 2 * 6 = 12
瞪眼法:中间切一刀,被切断的链路最小值显然为12
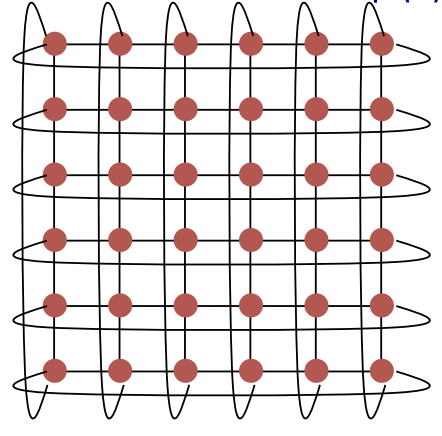
(d) Suggest a possible routing algorithm for Torus network. (2 marks)
仍然可以使用 Dimension Order Routing
先走东西方向,再走南北方向 以避免死锁
all east-west then all north-south (avoids deadlock)
[Eg. 6-ary 2-cube Torus]
来源:M0008 2019 Q2
(a) Draw network topology of a 6 -ary 2 -cube 2D Torus network with N=36 nodes.
答案同上一题 c
(b) Calculate the corresponding channel bisection bandwidth.
答案同上一题 c:12
(c) Provide a deterministic routing algorithm for this topology.
答案同上一题 d:Dimension Order Routing. route first in the east-west direction, then north-south
(d) List the advantages and disadvantages of the providing routing algorithm in Q2(c).
Pros & Cons:
- Simple to implement
- Simplify the problem of deadlock avoidance by preventing any cycles of channel dependency between dimensions 通过防止维度之间出现任何通道依赖循环来简化死锁避免问题
- Poor load balancing
(e) Discuss the general principle in designing a k-ary n-cube torus network by considering the impact of dimension “n” on network performance.
k-ary n-cube = n 个维度,每个维度有 k 个节点
总节点数 N = k^n
优点(好的impact):维度n++ => 节点邻居 neighbours of node ++
=> 路径多样性 path diversity ++ => 直径 diameter — => 延迟 latency —
且 => 对分带宽 bisection bandwith ++
缺点:Increase router ports增加端口 , high cost 高成本, complex wiring 复杂布线
[Eg. 6-ary 2-cube Torus]
来源:EENGM0008 2018 Q1
答案为官方答案
Q2: Figure 2 shows a 6-ary 2-cube 2D Torus network with N=36 node
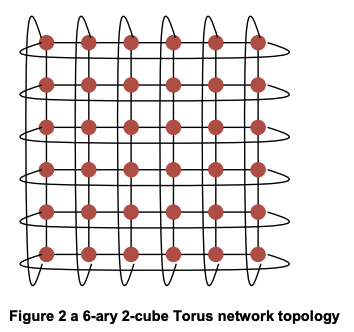
(a) Calculate the corresponding channel bisection bandwidth. (2 marks)
channel bisection bandwidth = 2*sqrt(N) = 12.
(b) Provide a deterministic routing algorithm for this topology and discuss the advantages and disadvantages of the routing algorithm. (6 marks)
Dimension-order routing algorithm
维序路由
first choose preferred directions, then calculate the routing distances for each direction. It will give the same path for a pair of Source and Destination node.
先选择首选方向,然后计算每个方向的路由距离。对于一对源节点和目标节点,它会给出相同的路径。
Pros & Cons:
- Simple to implement
- Simplify the problem of deadlock avoidance by preventing any cycles of channel dependency between dimensions 通过防止维度之间出现任何通道依赖循环来简化死锁避免问题
- Poor load balancing
(c) Draw a 6-ary 2-cube mesh network and calculate its bisection bandwidth. (4 marks)
The corresponding bisection bandwidth is sqrt(N) = 6.
[Eg. mesh vs 4-ary 2-cube]
来源:EENGM0008 2016 Q2(a)
(ii) With the aid of a diagram explain the two dimensional mesh topology and the 4-ary 2-cube topology for 16 nodes. Provide the [formulas] to measure the number of nodes, the diameter and bisection bandwidth of both architectures. Explain any differences or similarities.
Both two dimensional mesh and 4-ary 2-ary topologies for 16 nodes look identical as per drawing below. 他们看起来完全相同(对于16个节点)
Two dimensional mesh:
- Nodes = N = n^2
- Diameter = 2 [sqrt(N)-1]
- Bisection bandwidth = sqrt(N)
K-ary d-cube:
下面的公式没有在课件中出现过
- a d-dimension array with k elements in each dimension, there are links between elements that differ in one dimension by 1 (mod k)
- Nodes = N = k^d
- Diameter = d(k-1)
- Bisection bandwidth = k^(d-1)
The formulas used to measure the number of nodes, the diameter and bisection bandwidth while are different for such number of nodes deliver the same results.
用于测量节点数、直径和对半带宽的公式虽然不同,但对于相同数量的节点会得到相同的结果。
Step 2: 路由
I/O 端口功能
Input port
- 线路终止(line termination)
物理层:比特级接收(bit-level reception) - 数据链路处理(data link processing)
(协议处理、解封装)
数据链路层:例如 Ethernet - 查找、转发、排队(lookup, forwarding, queueing)
- 交换结构(switch fabric)
Output port
- 缓冲管理(Buffer management)
- 数据链路处理(data link processing)
(协议处理、封装) - 线路终止(line termination)
去中心化交换(Decentralized switching):
- 根据数据报的目的地址,通过转发表(forwarding table)查找输出端口
- 目标:在线路速率(line speed)下完成输入端口处理
- 排队(queueing):如果数据报到达速度快于进入交换结构的转发速率
缓冲需求(Buffering):
当数据报从交换结构到达输出端口的速度快于传输速率时,需要缓冲
- 需要队列管理策略(queue management policy)
- 还需要数据包调度策略(packet scheduling policy)
路由 Introduction
- 收敛(Convergence):路由器识别并使用备用路径所需要的时间
- 取决于定时器(timer)参数和算法
- 难以精确预测
- 负载均衡(Load balancing):将网络流量分配到多个服务器的过程
- 快速故障切换(Rapid failover)
- 实现最大吞吐量(Achieve maximum throughput)
- 抑制定时(Holddown):设置最小收敛时间
- 防止路由环路(Prevents routing loops)
Routing Loop: A Routing Disagreement
路由环路:路由信息不一致导致的循环转发。
路由协议目标
- 最优路径(Optimal path selection):路径长度尽可能短
- 减少跳数(hops)和整体时延(latency)
- 在无状态路由(oblivious routing)中,负载均衡与平均路径长度之间存在权衡
- 无环路由(Loop-free routing)
- 路由需要与网络的流量控制(flow control)协同,以避免死锁(deadlocks)和/或活锁(livelocks)
- 适应变化(Adapts to changes easily and quickly)
- 能够在网络发生故障(faults)时仍然正常工作
- 不发生饥饿(Starvation)
- 在某些数据包被优先处理的情况下,一些低优先级数据包可能永远无法到达目标
- 可以通过使用公平的路由算法,或为低优先级数据包保留部分带宽来避免
[Eg. 路由协议]
来源:EENGM0008 2018 Q4
本题答案为官方答案
(a) Discuss the goals of a routing protocol. (3 marks)
- Balance load across the network channels even in the presence of non-uniform traffic patterns 均衡负载
- Keep path lengths as short as possible (reducing the number of hops and the overall latency of a message) 保持最短路径
- Capability to work in the presence of faults in the network 网络故障时继续工作
- Routing interacts with the flow control of the network to avoid deadlocks and/or livelocks. 避免死锁、活锁。
(b) List four general routing algorithms. (4 marks)
本题超出课件范围
- Greedy
- Uniform random
- Weighted random
- Adaptive
(c) Is adaptive routing algorithm better than other routing algorithms? (3 marks)
The adaptive routing algorithm doesn’t always performance better than other routing algorithms. The disadvantage is the poor worstcase performance. 缺点是最坏情况的性能差。
- Local nature of most practical adaptive routing information
- Balance local load but poor in global load balance 平衡本地负载好,全局负载平衡差
- Delay responding to a change in traffic changes 对流量变化的响应存在延迟
Oblivious / Adaptive
- 无状态/无感知算法(Oblivious algorithms)
- 在选择路径时不考虑网络当前状态的信息。
- 确定性算法属于无状态算法
- 确定性算法(Deterministic algorithms) 总选择 相同的路径
- 自适应算法(Adaptive algorithms)
- 在做路由决策时考虑网络的状态 ,例如:
- 节点(node)、链路(link)、队列长度(length of queues)、历史信道负载信息(historical channel load information)
- 缺点:
- 只能看到局部网络状态 local natwork information
- Balance local load but poor in global load balance 平衡本地负载好,全局负载平衡差
- Delay responding to a change in traffic changes 对流量变化的响应存在延迟
- 在做路由决策时考虑网络的状态 ,例如:
[Eg. 路由算法权衡]
来源:EENGM0008 2019 Q4
答案由 AI 生成,不保证准确
Q4: Tradeoffs between routing algorithms.
(a) Compare minimal adaptive routing and minimal oblivious routing in terms of performance and suitable topologies. (4 marks)
Minimal adaptive routing:chooses the path according to the current network state, such as congestion, queue length, node/link state, or channel load.
suitable topologies:Mesh, Torus
Minimal oblivious routing:does not consider the current network state.
suitable topologies:hierarchical topologies, such as fat-tree.(课件原话)
(b) Assuming adaptive routers use flit-based or packet-based flow control, explain how the adaptive routing sense the state of network. (4 marks)
sense the network state, include:
- node or link state
- queue length in routers
- historical channel load
- congestion information
packet-based flow control: router choose a path for each packet
flit-based flow control: resources are allocated flit by flit.
(c) Is adaptive routing algorithm better than other routing algorithms? Add your justifications for your answer.
此小题答案为官方答案
The adaptive routing algorithm doesn’t always performance better than other routing algorithms. The disadvantage is the poor worstcase performance. 缺点是最坏情况的性能差。
- Local nature of most practical adaptive routing information
- Balance local load but poor in global load balance 平衡本地负载好,全局负载平衡差
- Delay responding to a change in traffic changes 对流量变化的响应存在延迟
路由算法分类:路由决策
- 源路由(Source routing):路径在源节点确定,每个数据包计算一次路径。
- 路由信息在源节点查找,并将路由信息加入到数据包头部(会增加数据包大小)
- 路由器从数据包头中的路由字段提取路由信息
- 不需要数据包中的目的地址、中间路由表或计算路径的功能
- 逐跳路由(Per-hop routing):在到达目的地的每一跳(hop)中,都进行路由计算确定下一跳。
- 例如:使用 XY 坐标 或 标识目的节点/路由器的编号
- 每个路由器通过查找路由表中的目的地址或执行硬件函数来做出路由决策
路由算法分类:跳数
- 最小路由(Minimal Routing):选择跳数最少的路径。可能存在多条最小路径。
- 非最小路由(Nonminimal Routing):非最小路由增加路径多样性,提高网络吞吐量。
确定性路由算法
Deterministic
- 从源节点(Src)到目的节点(Dest)的所有消息经过相同的路径。
- 常见示例:维序路由(Dimension Order Routing, DOR)
- 消息按网络维度逐维度进行传输
- XY 路由
- 缺点:
- 消除多样性
- 负载均衡较差
- 优点:
- 简单、成本低
- 不会产生死锁(deadlock)和活锁(livelock)
维序路由 ※
Dimension-order routing
原理
- first choose preferred directions, then calculate the routing distances for each direction. It will give the same path for a pair of Source and Destination node.
先选择首选方向,然后计算每个方向的路由距离。对于一对源节点和目标节点,它会给出相同的路径。
- 优缺点 ※
- 实现简单 simple to implement
- 通过防止不同维度之间出现信道依赖循环,简化死锁避免问题
- Simplify the problem of deadlock avoidance by preventing any cycles of channel dependency between dimensions
- 负载均衡差 poor load balancing
一个 6-ary 2-cube(k-ary n-cube)网络(二维 torus 网络)
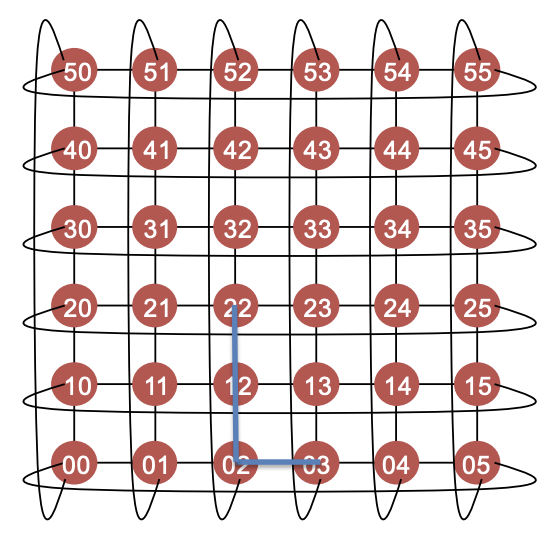
无感知路由
Oblivious Routing
- 为了从 s 路由到 d,随机选择一个中间节点 d′
- 从 s → d′,再从 d′ → d
- 对任何流量模式进行随机化
- 所有流量模式看起来都像均匀随机
- 平衡网络负载
- 局部性(locality)与负载均衡之间的权衡
- 随机流量负载的两倍
- 网络容量的一半
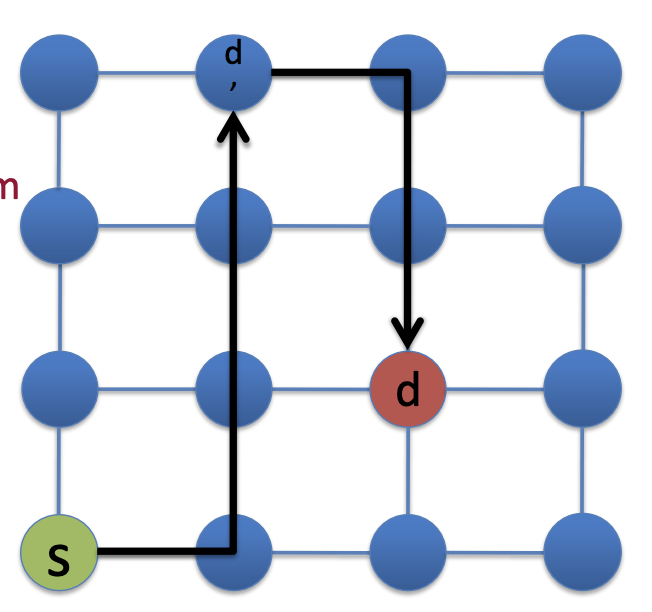
最小无感知
Oblivious Routing:Minimal Oblivious
- Valiant 算法:
负载均衡以 显著增加跳数(hop count) 为代价- 破坏局部性(locality)
- 最小无感知(Minimal Oblivious):
在实现一定程度负载均衡的同时,使用最短路径- d′ 必须位于最小象限(minimum quadrant)内
- d′ 有 6 种选择
- 只有 3 条不同的路径
- 在分层拓扑(hierarchical topologies)中效果非常好,例如 Fat Tree(胖树)。
Step 3-4: 交换 & 流控
Switching Mechanism + Flow Control
流量控制的功能
- 资源分配(Resource allocation):
- 消息的路由需要分配多种资源:信道(或链路)、缓冲区、控制状态
- 高效地分配网络资源:
- 接近理想带宽
- 低且可预测的延迟
- 竞争解决(Contention resolving)
[Eg. 流控的功能]
来源:EENGM0008 2018 Q5(a)
此题答案为官方答案
(a) Discuss the main functions for flow control mechanisms in networks? (4 marks)
- Resource allocation 资源分配
- The routing of a message requires allocation of various resources: the channel (or link), buffers, control state 消息的路由需要分配多种资源:信道(或链路)、缓冲区、控制状态
- Contention resolving 竞争解决
不同交换策略的流控
- 基于交换粒度的不同流控技术
- 电路交换(Circuit-switching):
- 在消息粒度上运行
- 分组交换(Packet-switching):
- 资源分配以整个数据包为单位
- 基于 Flit 的方式(Flit-based):资源分配以每个 flit 为单位逐个进行
- 电路交换(Circuit-switching):
分组交换
Packet switching
- 路由、仲裁、交换以数据包(packet)为单位
- 网络链路带宽的共享也是以数据包为单位
- 带缓冲的流量控制(Buffered flow control)
- 数据包从源节点发送,并独立地到达接收端
- 可能沿着不同的路径并具有不同的延迟
- QoS保证更难实现
- 启动时间为零,随后由于数据包路径上的路由器竞争会产生可变延迟
- 数据包从源节点发送,并独立地到达接收端
Packets / Flit
Packet switching: Packets / Flits
- message 会被拆分成多个packets(每个packets都包含头部信息,使接收方能重构原始消息)
- packets 可被拆分为多个 flit —— flit 不包含额外的头部信息
- 数据包可沿不同路径到达目的地,flit 总按顺序并沿同一路径传输
- 这种架构既允许使用较大的数据包大小(降低头部开销),又允许在每个 flit 的粒度上进行细粒度的资源分配
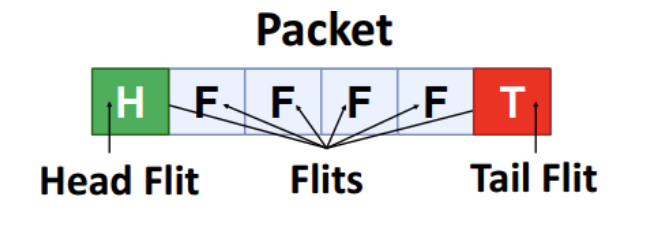
存储转发流量控制
SF, Store and Forward
why does Internet choose SF flow control?
Internet 选择 Store-and-Forward flow control,因为它:
- 支持 完整数据包错误检测
- 实现简单、兼容异构网络
- 提供 buffering 和拥塞控制能力
- 便于 队列调度和 QoS
- 对 Internet 这种大规模网络更可靠和稳定
- 只有当接收路由器拥有足够缓冲区来存储1个数据包时,数据包才会从一个路由器发送到下一个路由器
- 路由器中的缓冲区大小至少要等于一个数据包的大小
- 缺点:需要大量缓冲区
直通式流量控制
Cut-Through
- 一旦下一跳路由器中有足够空间容纳1个数据包,就立即转发该数据包的第一个 flit
- 相比存储转发(SF)交换,降低路由器延迟
与存储转发(SF)交换有相同的缓冲区需求
在当前交换机尚未存储完整个数据包之前,数据包的一部分就可以被转发(“直通”)到下一个交换机
下面这张图要会画
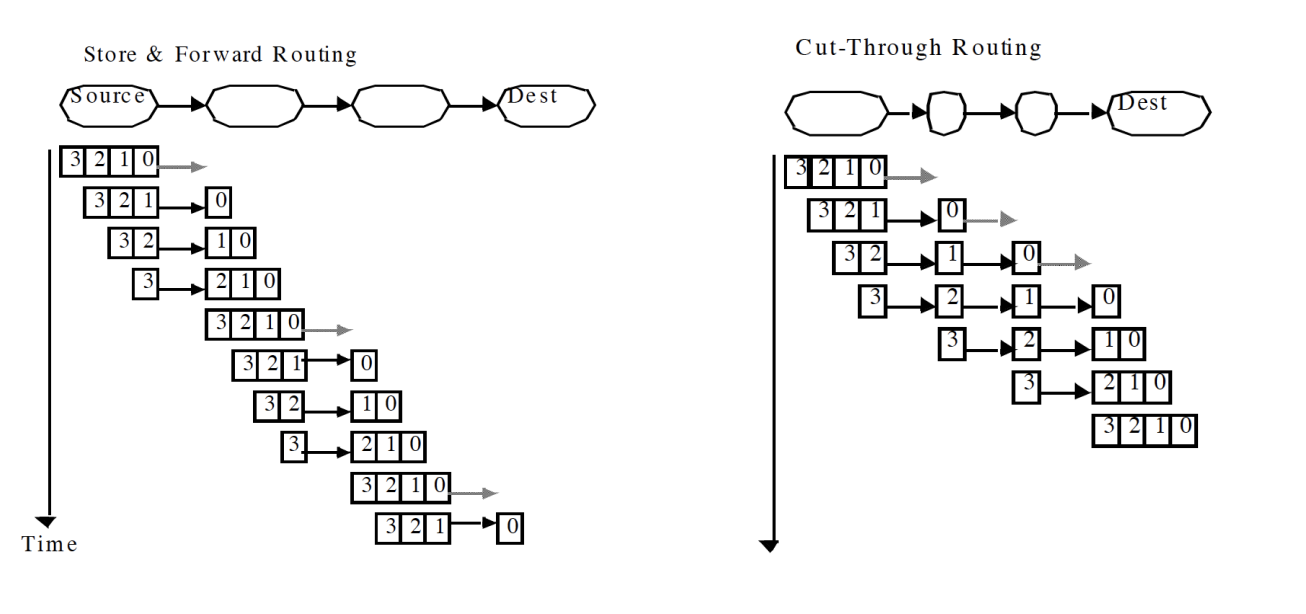
优缺点
优点
- 通过使用缓冲区将信道分配解耦,实现高信道利用率
- 低延迟
缺点
- 缓冲区存储利用效率低
- 由于按数据包分配信道,竞争延迟(contention latency)会增加
[Eg. 直通式]
来源:EENGM0008 2016 Q2 (b)
(i) Describe cut-through packet flow control with the aid of a diagram.
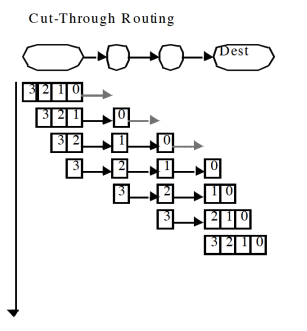
- Each message is broken into fixed units called Flits 消息被分解为Flits
- Flits contain no routing information
- They follow the same path established by a header
消息被划分为Flits,它不包含路由信息,遵循由头建立的相同路径
(ii) Measure the latency of a message that consists 10 words when transmitted over 5 links. Assume the following:
- the startup time $T_s$ is 100 ns.
- the transfer time of the message in a link is 10 ns.
- word transfer time $T_w$ is 200 ns.
注意 是 5 links 不是 5 nodes
公式:(T = T_s + H T_l + L T_w)
即 T = 启动时间 + link数 链路(传播)延迟 + word数 word传输延迟
Where:
- (T_s = 100ns) startup time
- (H = 5) links
- (T_l = 10ns) link transfer time
- (L = 10) words
- (T_w = 200ns) word transfer time
(\boxed{T = 2150ns})

包缓冲流控的延迟
Latency of Packet-buffer flow control
设:无竞争情况下,5 个 flit 的数据包经过 4 跳路径
存储转发
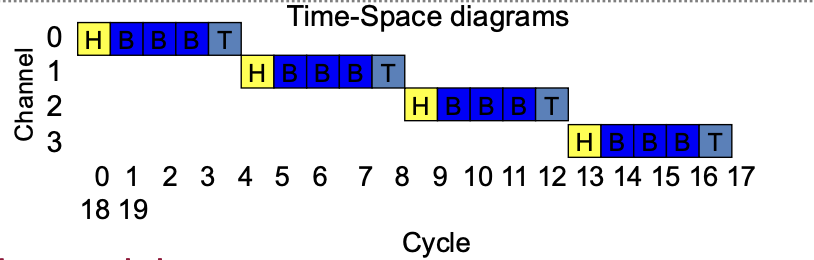
- 在每一跳都会经历一次串行化延迟(serialization latency)
直通式
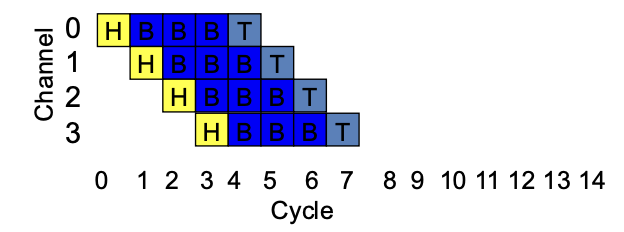
- 只经历一次串行化延迟
实际示例
- 10 GbE 存储转发交换机: 5–35 微秒
- 10 GbE 直通交换机: 300–500 纳秒
[Eg. 包缓冲流控对比]
来源:EENGM0008 2018 Q5(b)
此题答案为官方答案
(b) Describe store-and-forward and cut-through packet-buffered flow control with the aid of a diagram. Compare the two flow control mechanisms. (6 marks)
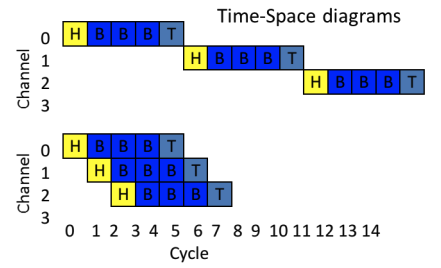
store-and-forward (SF) flow control: at each step of the route the entire packet is forwarded over one channel before proceeding to the next channel. The SF flow control will cause a high latency as serialization latency is experienced at each hop.
简单版:The whole packet must be received and stored at a router before being forwarded to the next router. cause a high latency because of serialization latency
整个包必须在路由器接收并存储后才能转发。因为串行化延迟而导致高延迟。
Cut-through flow control: it overcomes the latency penalty of SF flow control by forwarding a packet as soon as the header is received and resources are acquired, without waiting for the entire packet to be received.
简单版:reduce serialization latency by forwarding a packet when the header is received, without waiting the entire packet
降低序列化延迟:当接收到包头时就转发包,而无需等待整个包
性能指标
带宽与吞吐量
带宽(Bandwidth):
- 一条链路的带宽 = w × 1/t
- w 是信道数量(例如:导线、波长)
- t 是每比特所需时间(例如:100 ps/bit)
- 带宽单位为 b/s,
- 由于数据包开销(packet overhead),有效带宽通常低于物理链路带宽
吞吐量(Throughput):
- 在单位时间内发送和接收的数据量
数据包结构:
- 路由与控制头(Routing and control header)
- 数据负载(Data payload)
- 错误码(Error code)
- 尾部(Trailer)
吞吐量与最大信道负载
Throughput and Maximum Channel Load
- 网络的吞吐量(throughput)是网络每个输入端口每秒能够接受的数据速率(bit/s)。
- 它是整个网络的性质
- 它取决于路由和流量控制
- 最大信道负载(maximum channel load):某条信道 c 所需带宽与输入端口带宽之比定义为 γc。
- 理想吞吐量(ideal throughput):指使瓶颈信道刚好达到饱和时,输入端口所能提供的带宽。
其中:
- b:单条链路带宽
- Bc:网络的双分信道数(channel bisection)
- N:节点总数
- γmax 越大,说明最拥塞的链路负载越重,因此整体可达到的吞吐量越低。
延迟
- 延迟(Latency):发送时间与接收时间之间的时间差
- 不同网络架构间延迟差异很大
- 厂商通常报告的是硬件延迟(wire time,线路时间)
- 应用程序开发者更关心软件延迟
Observations:
- 硬件延迟与软件延迟通常相差 1–2 个数量级
- 最大硬件延迟会随着网络直径(diameter)变化,但软件延迟的变化通常可以忽略
- 对于包含大量小消息的程序,延迟非常重要
零负载延迟(无竞争)
Zero-load latency (no contention)
零负载延迟:网络中没有任何拥塞、排队、竞争时,一个数据包从源节点到目的节点所需的最短时间。
- $Tr = H{min} t_r$:路由器延迟
- $H_{min}$:平均最小跳数
- $t_r$:单个路由器的延迟
- 传播时间(Time of flight):
- $D_{min}$:平均距离
- $v$:传播速度
其中:
- $H(x,y)$:节点 $x$ 与节点 $y$ 之间的跳数
- $N$:网络中的节点数量
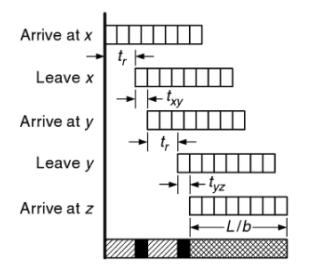
当网络负载接近饱和时,延迟会急剧增加。
互连网络 - 无阻塞网络
Interconnection networks - Non-blocking networks
直接网络与间接网络
Direct & Indirect Networks
- Direct(直接网络):每个交换机同时也是网络的终端节点
- 例如:mesh(网格)、torus(环形网格)、hypercube(超立方体)
- Indirect(间接网络):并非所有交换机都是终端节点
- 例如:Butterfly(蝴蝶网络)、Fat Tree(胖树)、Clos 网络
Router(路由器 / 交换机):
- Radix = 2 表示(2 个输入,2 个输出)
- 简写:Radix-ary
- 图中路由器是 2-ary(二端口路由器)
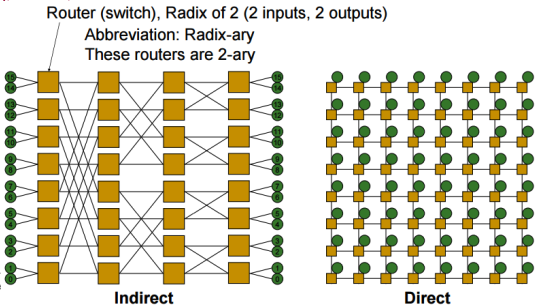
直接网络 vs 间接网络
Direct networks(直接网络)
- 所有节点都有 处理器或内存
- 由于 二分带宽(bisection bandwidth)有限,难以扩展到大规模
- 每个交换机需要 非常多端口
Indirect networks(间接网络)
- 存在 仅用于路由的中间节点(intermediate routing-only nodes)
- 每个交换节点所需 引脚(pins)数量较少
- 更高的网络吞吐量(network throughput)
- 计算与交换解耦(decoupling computing and switching)
内存交换 总线交换
总线
Bus
优点:
- 简单
- 对于节点数量较少的系统具有成本优势
- 易于实现一致性机制(监听 snooping)(Easy to implement coherence)
缺点:
- 无法扩展到大量节点
- 内存争用严重(High contention Memory)
交叉交换
Crossbar
Crossbar 是一种交换矩阵,用来让任意输入端口直接连接到任意输出端口,实现高速、非阻塞的数据交换。
本文中 交叉交换 = 交叉开关 = 交叉交换机 = crossbar switch
- 每个节点都与所有其他节点连接(无阻塞,non-blocking)
- 适用于节点数量较少的系统
优点:
- 低延迟(Low latency)
- 高吞吐量(High throughput)
缺点:
- 成本高(Expensive)
- 不易扩展,成本复杂度为 (O(N^2))(Not scalable)
N×M 交叉交换机
N×M Crossbar switch
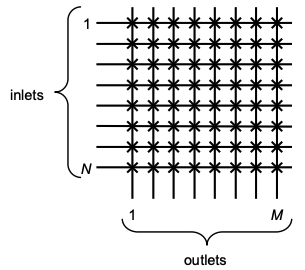
- 输入端口(inlets):1 到 N
- 输出端口(outlets):1 到 M
两种符号表示(Two symbolic representations)
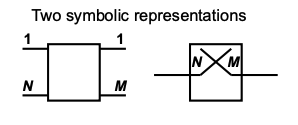
交叉点(crosspoints)的实现(Implementation of crosspoints)
图中的 “×” 表示一个交叉点开关的抽象表示。
最初是机电式,现在是电子式
- N > M:集中(concentration)
输入源的数量大于输出源,就会发生阻塞(blocking)。 - N < M:扩展(expansion)
- N = M:无阻塞方阵(non-blocking square array)
路径长度
- 最短路径:1
- 最长路径:$N + M - 1$
二分带宽(Bisection bandwidth)
- = $N$ 或 $M$
- 对于 $R \times R$ 的 crossbar 交换机:为 $R$。
扩展输出数量
Scaling number of outputs
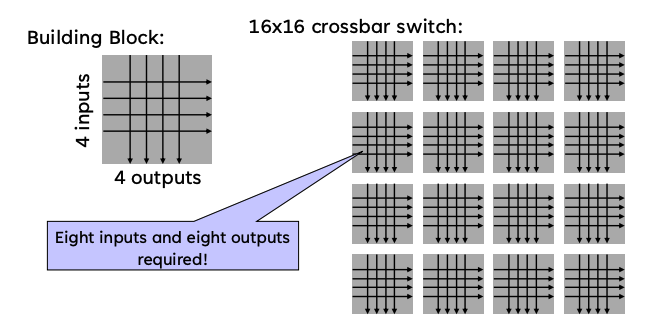
交叉交换机的限制
- 每个芯片需要 $N \times N$ 个交叉点(crosspoints)。
- 如何用多个芯片构建一个 crossbar 并不是显而易见的。
- 每个芯片的 I/O 能力有限。
补充说明:
- 当前技术水平:
每个芯片大约有 300 个引脚(pins),每个引脚速率约 3.125 Gb/s,
因此 每个芯片总带宽约为 1 Tb/s。 - 在实际系统中,由于 协议开销(overhead)和 speedup 等原因,
通常只有约 1/3 到 1/2 的容量可以真正使用。 - 因此,现代 crossbar 芯片的主要限制来自 I/O 容量。
无阻塞网络
Non-blocking network
如果一个电路交换网络(circuit-switching network)能够处理所有输入与输出之间的任意排列(permutation)的连接请求,则称其为无阻塞(non-blocking)。
如果题目没有特别说明,默认为严格无阻塞
- 严格无阻塞(Strictly non-blocking)
如果一个网络能够逐步建立任意排列(一次建立一条连接),并且不需要对已经建立的任何连接进行重路由或重排,则称该网络为严格无阻塞。 - 可重排无阻塞(Rearrangeable non-blocking)
一个网络可以为任意排列建立连接,但在逐步构建过程中,可能需要对之前建立的一些连接进行重新安排(rearrange)。
Clos 网络(m, n, r)※
Clos 网络由多个交换机构成,实现大量节点之间的连接,而不需要一个巨大的 crossbar。
Clos 网络的核心思想是:
- 不直接让每个输入都和每个输出完全连接
- 而是通过“输入层 → 中间层 → 输出层”三级交换
一个对称的三级 Clos 网络由三元组 $(n, m, r)$ 定义:
- $n$:第一级每个交换机的输入端口数。
- $m$:中间级交换机的数量。
- $r$:第一级/第三级交换机的数量。
- 总端口数(输入端口数/输出端口数) $N = n \times r$。
下面这张图要会画,记清楚 m, n, r 标在哪里
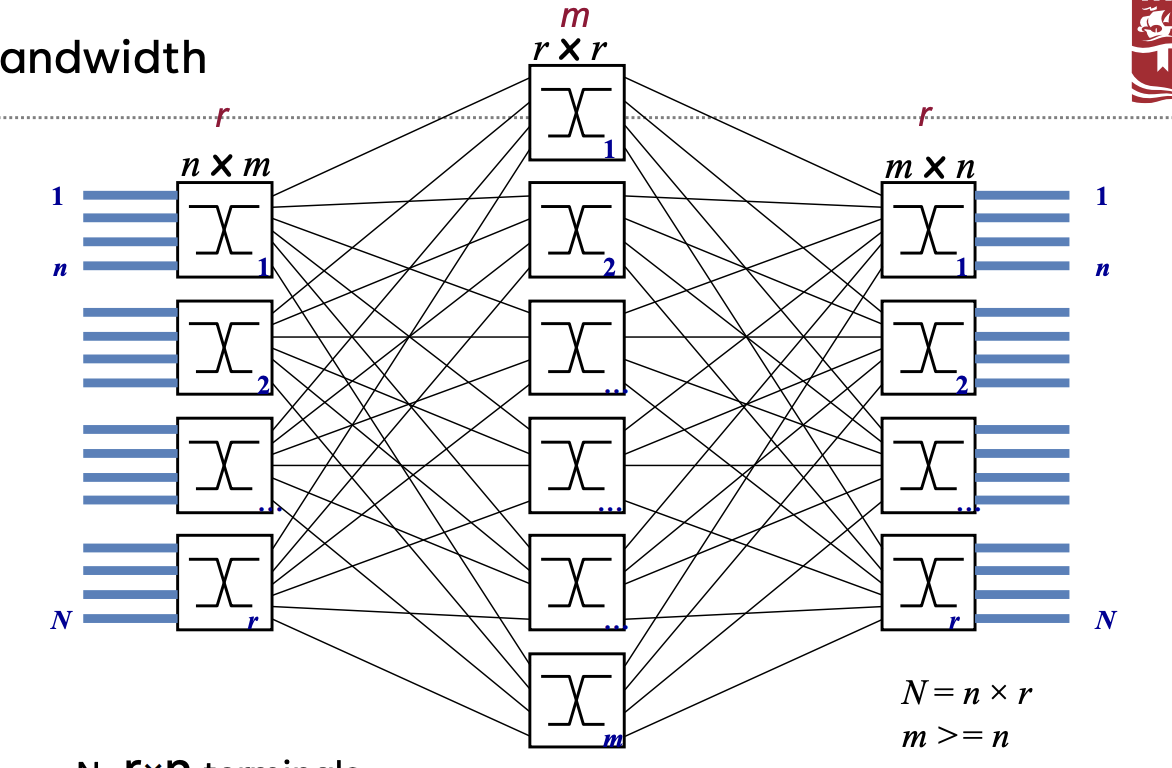
二分带宽 ※
Bisection bandwidth
公式需要记住
水平切割(Horizontal cut):
垂直切割(Vertical cut):
(且:$m \ge n$)
交叉点数量 ※
Number of Crosspoint
公式需要记住
交叉点数量:
最小化交叉点: 若 N 已知,则取 n = sqrt(N/2)
严格无阻塞 Clos ※
Strictly non-blocking Clos Network
不等式需要记住
Clos 定理
如果
则新的连接总是可以在不重新安排(rearrangement)已有连接的情况下被建立。
n:每个输入交换机的输入端口数(每个 input switch 接多少“终端”)
m:中间层交换机的数量(中间层提供的“可选路径数量”)
可重排无阻塞 Clos ※
Rearrangeable non-blocking Clos Network
不等式需要记住
Clos 定理
一个满足
的 Clos 网络是可重排的(rearrangeable)。
Eg. 交叉点数量
三阶段的 $500 \times 500$ 交换机,其中 $m = 25$,$n = 25$。计算交叉点(crosspoints)的数量。
Solution:
交叉点的总数为:
这相当于单级交换机($500 \times 500 = 250000$)所需交叉点数量的 14%。
Eg. 严格无阻塞 Clos
设计一个三阶段的 $500 \times 500$ 交换结构(switch fabric),用于严格无阻塞(strictly non-blocking)的 Clos 网络,其中 $n = 25$。
根据 Clos 定理:
- 对于 strictly non-blocking Clos network
- 必须满足
已知:
- $N=500$
- $n=25$
则:
再由 strictly non-blocking 条件:
所以该三阶段 Clos 网络应设计为:
- 第一阶段: $r=20$ 个 $25\times49$ 输入交换机
- 第二阶段: $m=49$ 个 $20\times20$ 中间交换机
- 第三阶段: $r=20$ 个 $49\times25$ 输出交换机
即整体结构为:
总交叉点数(crosspoints)按公式:
代入:
[Eg. Clos 网络]
来源: EENGM0008 2019 Q3
A Clos network is a three-stage network in which each stage is composed of a number of crossbar switches. A symmetric(对称) Clos is characterized by a ripple (m,n,r).
(a) Sketch a rearrangeable Clos network using only 3✕3 crossbar switches. The designed Clos network should have exactly 27 ports and multiple-stage Clos are allowed.
Multiple-stage Clos 指的是:Clos 网络不只用“一层三阶段”结构,而是把其中某些大的 crossbar switch 再用更小的 Clos 网络替代,形成更多级的 Clos 结构。
总端口数 N = 27 = n * r
由于只能使用 3*3 交换机,于是 第一级交换机的输入端口数 n = 3
于是 r = 27/3 = 9
为满足 rearrangeable,须 $m \ge n$,取 m = n = 3
于是 clos网络为 (3, 3, 9)
由于中间层 需要 m 个 r x r 交换机(3个9x9交换机),而题目只让用 3 x 3 交换机
所以需要将中间层分解为 3 个 子 clos 网络
对于 子 clos,输入端口 = 9 = 3 * 3,则 N’ = 9, n’ = r’ = 3,m’ 同理取 3
子 clos结构(都采用 3*3交换机):3个第一层,3个中间层,3个第三层
最终结构:
9 input switches, each 3x3 |
(b) Define the bisection bandwidth and the channel bisection that were used to measure the performance of a network architecture and explain its relevance. Calculate the horizontal and the vertical channel bisection of a (m,n,r) Clos network.
本小题答案为官方答案
第一句话中应该把 bandwidth 给删掉
A bisection bandwidth of a network is a cut that partitions the network nearly in half and partitions the nodes nearly in half. 网络的二分是一个割,它几乎对半划分了网络,且几乎对半划分了节点
The bisection bandwidth of a network, 𝐵_b, is the minimum bandwidth over all bisections of the network. 网络的二分带宽是在所有网络二分中最小的带宽
The channel bisection of a network, 𝐵_c, is the minimum channel count over all bisections of the network. 网络的信道二分是所有网络二分中最小的信道数
In network cost model, the bisection bandwidth of a network indicates the amount of global wiring required to implement it. 在网络成本模型中 二分带宽指出了实现网络所需的全部布线量
Horizontal cut: 𝐵_b = 𝑚𝑟;
Vertical cut: 𝐵_c = 2𝑛𝑟 = 2N;

(c) Design a three-stage, 200 × 200 switch (N = 200) with m = 5 and r = 20. You need to choose the size and quantities of input switches, middle switches and output switches. Compute the total number of crosspoints.
n = N / r = 10
=> (Clos(5,10,20))
Input switch: 10 x 5, 20个
Middle switch: 20 x 20, 5个
Output switch: 5 x 10, 20个
Crosspoints: 2mnr + mr^2 = 4000
(d) Redesign the previous three-stage, 200 × 200 switch, using the Clos criteria for a non-blocking switch supporting unicast traffic with a minimum number of crosspoints. Compute the number of crosspoints.
默认严格无阻塞,要求 m >= 2n - 1
为了使交叉点数量最小,取 n = sqrt(N/2) = 10
于是 r = N / n = 20
取 m = 2n - 1 = 19
=> (Clos(19,10,20))
crosspoints = 2mnr + mr^2 = 15200
[Eg. Clos 网络]
来源 EENGM0008 2018 Q3
本题答案为官方答案
Q3: A Clos network is a three-stage network in which each stage is composed of a number of crossbar switches. A symmetric Clos is characterized by a ripple (m,n,r).
(a) Draw a (4, 5, 3) Clos network. (3 marks)
(b) Define the bisection bandwidth and channel bisection used to measure the performance of a network architecture and explain its relevance. Calculate the horizontal and the vertical channel bisection of a (m,n,r) Clos network. (5 marks)
A bisection bandwidth of a network is a cut that partitions the entire network nearly in half and partitions the terminal nodes nearly in half.
The bisection bandwidth of a network, 𝐵_b, is the minimum bandwidth over all bisections of the network.
The channel bisection of a network, 𝐵_c, is the minimum channel count over all bisections of the network.
In network cost model, the bisection bandwidth of a network indicates the amount of global wiring required to implement it.
Horizontal cut: 𝐵_b = 𝑚𝑟;
Vertical cut: 𝐵_c = 2𝑛𝑟;
(c) Design a three-stage, 300 × 300 switch (N = 300) with m = 6 and r = 20. Compute the number of crosspoints. (4 marks)
n = N / r = 15
Number = 2nmr + mr^2 = 6000

(d) Redesign the previous three-stage, 300 × 300 switch, using the Clos criteria for a non-blocking switch supporting unicast traffic with a minimum number of crosspoints. Compute the number of crosspoints. (4 marks)
为获得最小交叉点数,取 n = sqrt(N/2) = sqrt(150) =12.247 ≈ 12
为满足 严格非阻塞,要求 m >= 2n - 1, 取 m = 23
r = N/n = 25
交叉点数量:2mnr + mr^2 = 28175
官方答案中最后算式的数字错了
应该是 2×(23×(12 × 25)) + 23×(25 × 25) = 28175

(e) Describe the switching architecture of one of the switches used in CLOS network (2 marks).
Each switch in a Clos network is a crossbar switch. A crossbar can provide non-blocking switching, but it needs many crosspoints, so it is costly and hard to scale. Clos uses multiple stages of smaller crossbars to build a large-scale switch with lower cost.
Clos 网络中的交换机是 crossbar switch。Crossbar 提供无阻塞交换,但需大量交叉点,成本高、难扩展。Clos 用多级小型 crossbar 来构建大规模switch,with 低成本。

阻塞概率
公式
公式要记住
Evaluation of Blocking Probability
这是一个三阶段交换网络的信道图(channel graph):
一条路径由两个链路串联组成,用于连接Input Switch和Output Switch,中间是Centre Stage Switches
设 $b$ 是 Centre Stage Switches 的数量: 当 所有 $b$ 条路径都忙 时,发生阻塞
发生阻塞的概率($p$ 是内部链路占用率):
Clos(100, 100, 10)
- 交叉点数量(Number of crosspoints)
- 在该例中:
- 设 $a$ 是每个输入或输出链路的平均占用率(traffic load)
那么内部链路占用率:
随着流量负载增加,阻塞概率会上升
如果:
就称该交换机为:“几乎无阻塞(virtually non-blocking)”
集中以减少交叉点
Reducing crosspoints using concentrators (small load)
- 小的链路占用率使阻塞概率可忽略——在第一阶段集中流量来降低交换复杂度。
- 交叉点数量:
- 内部链路占用率p (a是外部链路(输入端口)占用率):
- 阻塞概率:
[Eg. 集中以减少阻塞]
来源:EENGM0008 2016 Q1 (c)
本题答案为官方答案
(c) A digital cross-connect is used to switch and multiplex data between servers in Data Centers.
(i) Explain, with the aid of a diagram, a three-stage 1000x1000 digital cross-connect with 10:1 concentration. Calculate the number of cross-points.
图:类似于clos(10,100,10)。注意1、3阶段交换机画法
Small line occupancy leads to negligible blocking probability – switching complexity can be reduced by concentrating traffic at first stage 较低的线路占用导致阻塞概率可忽略——通过在第一阶段集中流量可以降低交换复杂性
Number of crosspoints = 2mnr + mr^2 = 2x10x100x10 + 10x10x10 = 21,000
(ii) Assuming an internal link occupancy of 0.5 calculate the blocking probability of the switch. What would be the blocking probability if we increase the number of centre stage switches to 100?
题目中已经给出了内部占用率,不需要根据 p = 集中倍数 * 外部占用率 来计算内部占用率了
公式:(p 是内部链路占用率 internal link occupancy, b 是 中心级交换机的数量)
Prob(blocking) = (1 - (1-p)^2)^b = (1 - (1-0.5)^2)^10 = 0.0563
当 centre stage switches 为 100 时
Prob(blocking) = (1 - (1-p)^2)^b = (1 - (1-0.5)^2)^100 = 3.207×10⁻¹³
DCN 中的网络协议
Network protocols in DCN
之后的内容以介绍为主,没有例题
无损网络
Lossless Networks
- 数据存储系统通常承载关键业务,因此要求更高的弹性和安全性。
- 特殊应用包括:
iSCSI(Internet Small Computer System Interface)本地流量- LAN 备份
- 虚拟机迁移
- 集群
- HPC(高性能计算)
光纤通道 FC
光纤通道, Fibre Channel
- DCN 中的数据存储系统要求网络提供更高的弹性和安全性,因为业务操作可能非常关键。
- 存储流量无法容忍重传造成的延迟;出于安全原因,许多 IT 管理员也希望把存储保留在隔离网络中。
- 以太网在特定条件下允许丢包,并期望数据在更高层(如 TCP)被重传。
- FC 需要使用主机总线适配器(HBA)。HBA 类似于网卡(NIC),驻留在服务器上;同时存储阵列也需要具备 FC 接口。
- 一个或多个 FC 交换机用于把多台服务器与多个存储阵列互连。
FC 协议
- FC 是一种串行协议。
- 它在 SAN 中使用的交换结构拓扑上取得成功,可通过光缆提供 1G、2G、4G、8G 和 16G bit/s 的速率。
- 帧格式:
- FC 头部支持 24 位地址,可覆盖超过 1600 万个端口。
- 载荷可从 0 字节到超过 2KB,并由 CRC(Cyclic Redundancy Check,循环冗余校验)字段保护。
- 帧的交付顺序不保证,因此需要结合序列控制、序列 ID 字段以及交换 ID 使用。
FCoE
以太网上的光纤通道,Fibre Channel over Ethernet
- 许多数据中心除了以太网数据网络外,还包含专用的 FC SAN(存储区域网络)。
- 使用 FCoE 时,FC 帧同时被 FCoE 头部和以太网头部封装。
- FC 帧本身承载 SCSI 命令。
- 以太网头部包含
0x8906的 EtherType,用于标识该帧为 FCoE。 - 使用 4 位版本号,并配合帧开始(SOF)和帧结束(EOF)指示。
- 为封装较小的 FC 命令帧,会添加保留字节以维持以太网最小帧大小。
FCoE 网络
- 在服务器中,融合网络适配器(CNA)用于连接以太网网络。
- CNA 通过生成和接收 FCoE 帧,既能提供传统 NIC 的功能,也能提供 FCoE HBA 的功能。
- 需要使用一种特殊的以太网交换机,称为 Fibre Channel Initiator Protocol(FIP)Snooping Bridges(FSB)。
FIP Snooping 确保只有已登录 FC 网络的服务器才能访问该网络。
Fibre Channel Forwarders(FCF)是用于转发所有 FCoE 帧的交换设备。
- FCF 还可通过封装和解封装 FC 帧,充当通往传统 FC SAN 的桥接设备。
- 所有数据都需要经由 FCF 路由,并且所有 FSB 必须连接到某个 FCF,这会增加拥塞并限制 FCoE 目标的实用性。例如,连接到同一 FSB 的 FCoE 存储目标,其数据仍必须经 FCF 路由(图左)。
- FC-BB-6 标准引入了新型以太网交换机 Fibre Channel Data Forwarder(FDF)。FDF 可基于 FCF 提供的信息进行 FCoE 转发和分区(图右),不需要直接连接到 FCF。
数据中心桥接 DCB
Data Centre Bridging, DCB
- 扩展以太网在数据中心中的能力。
- 目标是提升和扩展数据中心中的以太网网络能力和管理能力。
- 它帮助在无损交换结构上确保交付,并把 I/O 融合到统一交换结构中。
- 将网络划分为并行平面。
- 8 条大体独立的通道。
- 可分别配置。
- 利用 3 位 VLAN CoS(也称用户优先级)。
- 为协议/服务隔离而设计。
- 每条通道或类别组可承载不同协议。
DCB 层次结构:概念视图
DCB 特性
- 基于优先级的流量控制(Priority-based Flow Control, PFC)。
使用 PFC PAUSE 时的缓冲需求计算涉及:
- PFC PAUSE 的处理与排队延迟。
- 介质上的传播延迟。
- 对 PFC PAUSE 帧的响应时间。
增强传输选择(Enhanced Transmission Selection, ETS)。
- ETS 根据带宽分配、低时延或尽力而为等目标提供优先级处理,从而实现按组划分的流量类别分配。
数据中心桥接交换协议(Data Center Bridging Exchange Protocol)。
- DCB 对等体发现。
- 配置不匹配检测。
- 对等体的 DCB 链路配置。
交换的信息包括:
- ETS 中的优先级组。
- 基于优先级的流量控制。
- 拥塞通知。
- 应用。
- 逻辑链路断开。
- 网络接口虚拟化。
拥塞通知。
- 拥塞通知是一种第 2 层流量管理系统。
- 它通过指示速率限制器对导致拥塞的流量进行整形,把拥塞压力推向网络边缘。
高性能计算
High Performance Computing
应用与计算系统
Application and computing systems
- 应用范围多样。
- 处理特征和数据集特征各不相同。
- 高性能计算持续增长。
- 处理器性能增长。
- 多核 CPU;芯片密度约每 18 个月翻倍。
- 通用网络能力增长。
- 网络速度与功能提升,同时成本降低。
- 不同类型的系统包括:
- 集群
- 网格
- 云
- 数据中心
网格计算环境
Grid Computing Environment
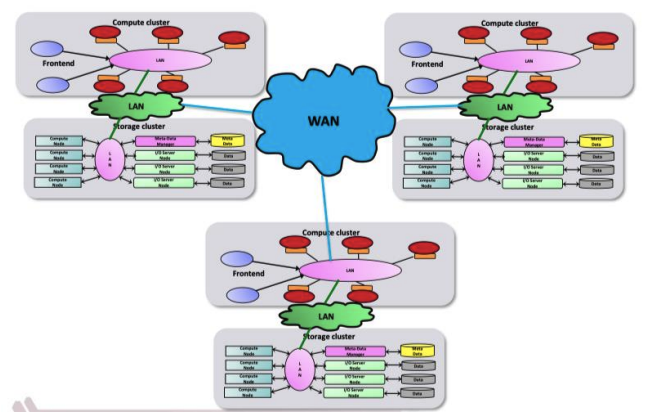
网络与 I/O 需求
- 系统区域网络(System Area Networks)。
- 为处理器间通信(IPC)提供优异性能:低时延、高带宽、低 CPU 使用率。
- 高性能 I/O。
- 除集群内部 SAN/LAN 连通性外,还需要 WAN 连通性。
- 面向交互式应用的多样化服务质量(QoS)。
- RAS:可靠性、可用性与可维护性(Reliability, Availability, and Serviceability)。
- 低成本。
计算架构的关键要素
- 计算平台中的系统平衡非常重要。
- CPU 吞吐量。
- 内存子系统性能。
- I/O 子系统性能。
- 这些操作都会贡献整体计算时间:
- 从其他节点获取数据(I/O)。
- 从内存取数据。
- 处理数据并生成结果。
计算系统的主要部件
- 硬件组件:
- 处理核心与内存子系统。
- I/O 总线或链路。
- 网络适配器/交换机。
- 软件组件:
- 通信协议栈。
- 主要瓶颈可能出现在:
- 处理。
- I/O 接口。
- 网络。
传统协议的处理瓶颈
传统协议指 TCP/IP、UDP/IP
- 面向所有网络的通用架构。
- 主机处理器几乎处理通信的所有方面:
- 数据缓冲。
- 数据完整性(校验和)。
- 路由相关功能(IP 路由)。
- 不同层之间需要信令:
- 分组到达或发送时触发硬件中断。
- 不同层之间通过软件信号,以不同优先级处理协议过程。
传统 I/O 和网络的瓶颈
- 传统上依赖基于总线的技术,例如 PCI、PCI-X。
- 每根线传输 1 bit。
- 通过提高时钟频率和总线宽度来提升性能。
- 扩展性不佳。
- 限制因素包括:
- 串扰。
- 线间偏斜。
- 信号完整性显著限制总线宽度。
传统网络的瓶颈
- 网络速度曾在约 1 Gbps 附近达到瓶颈。
- 所提供的功能有限。
- 通用网络被认为不足以支撑超大规模系统。
- 示例速率:
- Ethernet(1979-):10 Mbit/s。
- Fast Ethernet(1993-):100 Mbit/s。
- Gigabit Ethernet(1995-):1000 Mbit/s。
- ATM(1995-):155/622/1024 Mbit/s。
- Myrinet(1993-):1 Gbit/s。
- Fibre Channel(1994-):1 Gbit/s。
InfiniBand(IB)与高速以太网(HSE)
- 工业网络标准。
- InfiniBand 与高速以太网被引入市场,用于解决这些瓶颈。
- InfiniBand 旨在同时解决三类瓶颈:
- 协议处理。
- I/O 总线。
- 网络速度。
- 以太网主要直接处理网络速度瓶颈,并依赖互补技术缓解协议处理与 I/O 总线瓶颈。
用 IB 与 HSE 解决网速瓶颈
- 位串行差分信令。(Bit serial differential signalling)
- 使用相互独立的线对传输独立数据(lane)。
- 可扩展到任意数量的 lane。
- 易于提高时钟频率。
IB 硬件加速
- 支持在硬件中完整执行协议处理(硬件协议卸载引擎)。
- 某些 IB 型号具有多个硬件加速器,例如 Mellanox IB 适配器。
- 协议卸载引擎。
- 在硬件中完整实现 ISO/OSI 第 2 到第 4 层(链路层、网络层、传输层)。
- 通信层之间不需要软件信令。
- 所有层都在专用硬件单元上实现,而不是在共享主机 CPU 上实现。
- 还具备其他硬件支持特性。
- RDMA、组播、QoS、容错等。
- 融合增强以太网(Converged/Enhanced Ethernet, CEE 或 CE)。
- 将多个光以太网标准组合到一个总括体系中。
IB 存储解决方案
- InfiniBand 标准是以下技术的强有力替代方案:
- Fibre Channel(SAN)。
- Ethernet(NAS)。
- 性能更优:
- 20 Gb/s 主机/目标端口(2008 年向 40 Gb/s 迁移)。
- 60 Gb/s 交换机到交换机(2008 年向 120 Gb/s 迁移)。
- 数据中心统一交换结构:
- 存储、网络和集群通过一根线统一承载。
- 成本有效:
- 具有很强的价格/性能优势。
- 功耗更低:
- 每个 20 Gb/s 端口低于 5W。
- 其他特性:
- 高可靠性交换结构。
- 多路径。
- 自动故障切换。
与 I/O 技术的相互影响
- InfiniBand 最初旨在用类似网络的技术替代 I/O 总线技术。
- 今天,IB 与 HSE 都以网络适配器的形式接入现有技术。
- I/O 接口的近期趋势表明,I/O 速度正在与网络速度正面匹配。
PCI 接口
Peripheral Component Interconnect interface

示例:传输 64K 字节数据。
- 处理器:Intel 2.8 GHz Xeon CPU。
- 芯片组/内存:DDR 300 MHz,128 bit 宽。
- I/O:PCI-X 与 Gigabit Ethernet。
PCI Express vs 典型服务器架构
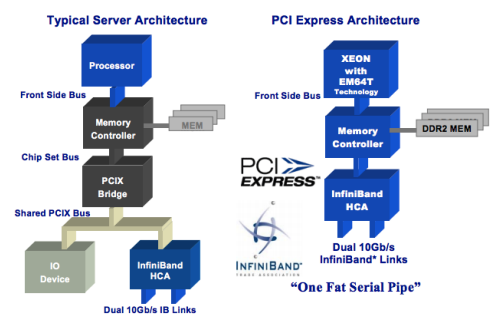
使用 InfiniBand 与 PCI Express 时,服务器与 CPU/内存子系统之间存在一条“粗”的串行管道直接连接。
这会减少芯片数量和系统复杂度,并提升带宽与时延表现;后续还将看到,它也能提升整体系统级平衡与性能。
InfiniBand 网络分区
- 可为以下对象定义不同分区:
- 不同客户。
- 不同应用。
- 安全目的。
- 服务质量。
- 交换机执行分区过滤。
- 将交换结构逻辑划分为相互隔离的域。
- 类似于:
- Fibre Channel Zoning。
802.1Q VLAN。
IB 数据完整性
- 逐跳:
VCRC:16 位 CRC。CRC16 0x100B。
- 端到端:
ICRC:32 位 CRC。CRC32 0x04C11DB7。- 与以太网使用相同 CRC。
- 应用层:
T10/DIF Logical Block Guard。- 每块 CRC。
- 16 位 CRC
0x8BB7。
I/O 融合
Consolidation
传统问题:
- I/O 较慢。
- 不同服务需求需要不同交换结构。
- 缺乏灵活性。
- 需要管理更多端口。
- 功耗更高。
- 占用更多空间。
- 总拥有成本(TCO)更高。
融合后的优势:
- 为容量供给提供高带宽管道。
- 专用 I/O 通道支持融合。
- 用于网络、存储和管理。
- 支持应用兼容性。
- QoS 可区分不同流量类型。
- 分区可提供逻辑交换结构与隔离。
- 网关共享远程 Fibre Channel 与以太网端口。
- 可基于多台服务器的平均负载进行设计。
- 可渐进扩展:增加以太网/FC/服务器刀片。
- 可独立扩展。
InfiniBand 简介
InfiniBand 架构模型
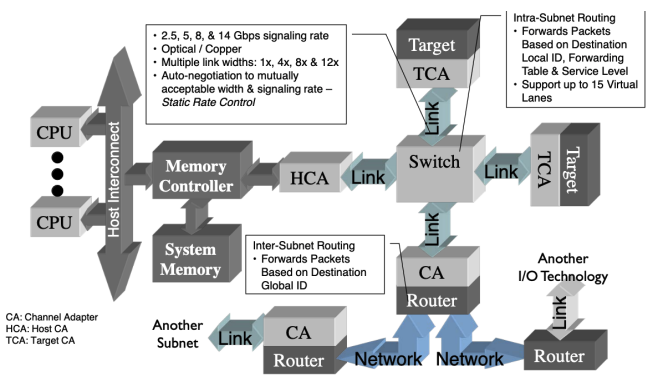
IB 组件
通道适配器(Channel Adapters)
- 主机通道适配器(Host Channel Adapter, HCA)。
- 终止 IB 链路并执行传输层功能的设备,同时支持 verbs 接口。
- 存在于服务器中。
- 目标通道适配器(Target Channel Adapter, TCA)。
- 存在于 I/O 设备上,例如 RAID(廉价/独立磁盘冗余阵列)或 JBOD(just a bunch of disks)子系统。
主机通道适配器(HCA)
- 相当于以太网中的 NIC。
- 具有 GUID(Global Unique ID)。
- 将 PCI 转换为 InfiniBand。
- 将传输操作从 CPU 卸载。
- 提供端到端 QoS 与拥塞控制。
- HCA 带宽选项:
SDR:Single Data Rate,2.5 Gb/s * 4 = 10 Gb/s。DDR:Double Data Rate,5 Gb/s * 4 = 20 Gb/s。QDR:Quadruple Data Rate,10 Gb/s * 4 = 40 Gb/s。FDR:Fourteen Data Rate,14 Gb/s * 4 = 56 Gb/s。EDR:Enhanced Data Rate,25 Gb/s * 4 = 100 Gb/s。
其他 IB 组件
- 交换机:在同一个 IB 子网内,把分组从一条链路转移到另一条链路的设备。
- 路由器:在不同 IBA 子网之间传输分组的设备。
- 桥/网关:InfiniBand 到 Ethernet。
- 链路与中继器。
IB 物理层
- IB 在物理层定义 3 类链路速率。
1X、4X、8X、12X,包括自动协商。- 速率
SDR/DDR/QDR,包括自动协商。 - 每条链路是四线串行差分连接。
- 每个方向两根线(两个互补信号用于消除电磁噪声),从而提供全双工连接。
8/10编码:用于维持直流平衡,并限制连续 0 和 1 的长度。
- 控制符号用于 lane 去偏斜、自动协商、训练、时钟容差和成帧。
IB 拓扑
- 模块化交换机基于 fat-tree 架构。
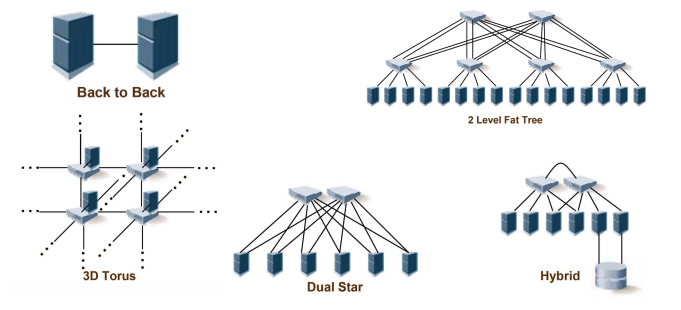
IB 交换结构构建块
- 每个 IB 交换模块的基本构建块是一个 36 端口 IB 交换芯片。
- 更高端口数的交换模块可以使用多个芯片创建。
- 图示:72 端口交换机由 6 个相同芯片构成。
- 4 个芯片作为线路侧(line)。
- 2 个芯片作为核心侧(core)。
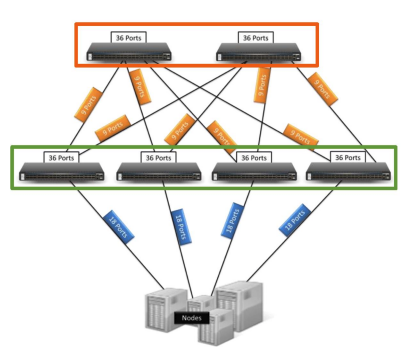
InfiniBand 与传统网络协议栈比较
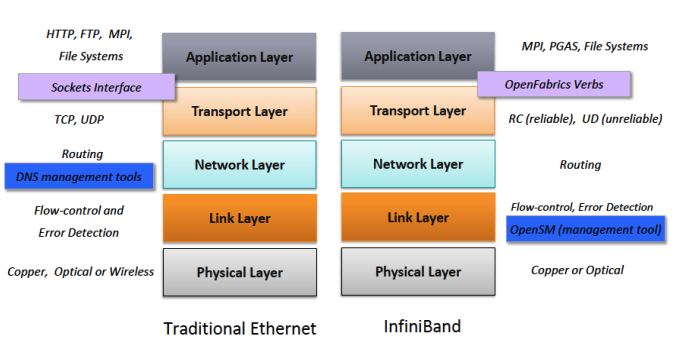
IB 链路层
链路层包含分组布局、点到点链路操作,以及本地子网内部的交换。
- 分组
- 链路层有两类分组:管理分组与数据分组。
- 管理分组用于链路配置和维护。设备信息(如虚拟通道支持)通过管理分组确定。
- 数据分组最多可携带 4 KB 的事务载荷。
- 交换
- 在子网内,分组转发与交换由链路层处理。
- 子网内所有设备都有一个由子网管理器分配的 16 位本地标识符(LID)。
- 子网内发送的所有分组都使用 LID 寻址。
- 链路层交换根据分组中本地路由头(LRH)的目的 LID,把分组转发到指定设备。
- LRH 存在于所有分组中。
- 独立虚拟通道。
- 流量控制(无损交换结构)。
- 服务器级别。
- 用于 QoS 的 VL 仲裁。
- 拥塞控制。
- 前向/后向显式拥塞通知(FECN/BECN)。
- 数据完整性。
- 不变 CRC。
- 可变 CRC。
- 寻址与交换。
- 本地标识符(LID)寻址。
- 单播 LID:48K 个地址。
- 组播 LID:最多 16K 个地址。
- 高效线性查找。
- 通过 LMC 支持多路径。
InfiniBand 通过虚拟通道(VL)支持 QoS。
- 这些 VL 是共享同一物理链路的独立逻辑通信链路。
- 每条链路最多支持 15 条标准 VL 和 1 条管理通道(VL15)。
- VL15 优先级最高,VL0 优先级最低。
- 管理分组仅使用 VL15。
基于信用的流量控制。
- 链路级流量控制用于管理两条点到点链路之间的数据流。
- 流量控制按 VL 分别处理,使不同虚拟交换结构可以在共享同一物理介质时维持通信。
- 链路的每个接收端都会向发送设备提供信用值,用以指明在不丢数据的情况下可接收多少数据。
- 每个设备之间的信用传递由专用链路分组管理,以更新接收端可接受的数据分组数量。
- 除非接收方通告了表示接收缓冲空间可用的信用值,否则不会传输数据。
数据完整性。
- 在链路层,每个分组有两种 CRC:可变 CRC(VCRC)与不变 CRC(ICRC),用于确保数据完整性。
- 16 位 VCRC 覆盖分组中的所有字段,并在每一跳重新计算。
- 32 位 ICRC 只覆盖那些逐跳不会变化的字段。
- VCRC 在两跳之间提供链路级数据完整性;ICRC 提供端到端数据完整性。
- 在以太网这类只定义单一 CRC 的协议中,设备内部可能引入错误,然后重新计算 CRC。
- 下一跳的检查可能会得到有效 CRC,即使数据已经损坏。
- InfiniBand 包含 ICRC,因此一旦引入 bit 错误,就总能检测到。
IB 第 2 层交换寻址:本地标识符(LID)
- 本地标识符:16 位第 2 层地址。
- 当端口变为活跃时,由子网管理器分配。
- 重启后不保持不变。
- 全局标识符(GID)寻址:
{64 bit GID prefix, 64 bit GUID}。GUID = Global Unique Identifier,64 位。GUID 0:由制造商分配。GUID 1 ... (N-1):由子网管理器分配。
IB 数据包
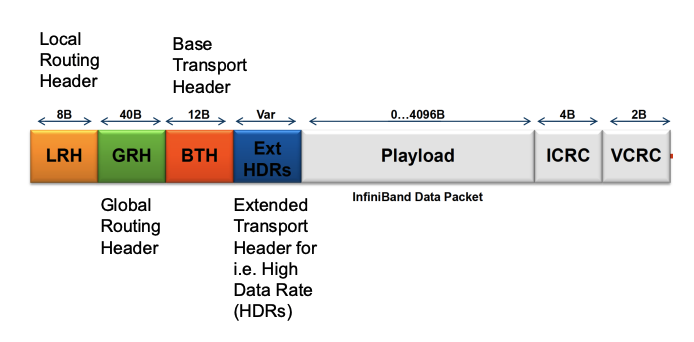
本页示意的主要头部包括:
- Local Routing Header:本地路由头。
- Base Transport Header:基础传输头。
- Global Routing Header:全局路由头。
- Extended Transport Header:扩展传输头,例如用于 High Data Rate(HDR)。
子网管理器
Subnet Manager
- Agent
- 运行在每个适配器、交换机、路由器上的进程或硬件单元。
- 提供查询和设置参数的能力。
- Manager
- 做出高层决策,并通过 agent 在网络交换结构上实施。
- 消息机制
- 用于 manager 与 agent 之间交互。
- 消息
IB 网络层
- 网络层负责把分组从一个子网路由到另一个子网。
- 在子网之间发送的分组包含全局路由头(GRH)。
- GRH 包含分组源和目的的 128 位 IPv6 地址。
- 分组通过路由器在子网之间转发,并基于每个设备的 64 位全局唯一标识符(GUID)。
- 路由器会使用每个子网内适当的本地地址修改 LRH。
- 因此,路径上的最后一个路由器会把 LRH 中的 LID 替换为目的端口的 LID。
全局唯一标识符(GUID):物理地址
- 任何 InfiniBand 节点都需要 GUID 与 LID(Local Identifier)地址。
- GUID(Global Unique Identifier)是 64 位地址,可以类比以太网 MAC 地址。
- 由 IB 厂商分配。
- 重启后保持不变。
- IB 交换机具有“多个”地址 GUID。
- Node:用于把 HCA 标识为一个实体。
- Port:用于把端口标识为端口。
- System:允许组合多个 GUID,以形成一个实体。
IB 传输层
- 传输层负责:
- 按序分组交付。
- 分区。
- 通道复用。
- 传输服务。
- 可靠连接与不可靠连接。
- 可靠数据报、不可靠数据报、原始数据报。
InfiniBand 架构为传输层提供了显著改进:所有功能都在硬件中实现。
队列对(Queue Pair, QP)是传输端点。
- 异步接口。
- 包含发送队列、接收队列、完成队列。
- 完整传输卸载。
- 分段、重组、定时器、重传等。
- 支持的操作:
- Send/Receive:消息语义。
- RDMA Read/Write:支持零拷贝操作。
- Atomics:远程 Compare & Swap、Fetch and Add。
- 内存管理:Bind、Fast Register、Invalidate。
- 内核旁路。
- 支持低时延和 CPU 卸载。
- 通过 QP、完成队列(CQ)、保护域(PD)和内存区域(MR)实现。
管理模型
- 子网管理器(Subnet Manager, SM)。
- 配置/管理交换结构拓扑。
- 可在端节点或交换机上实现。
- 当存在多个 SM 时使用主动/被动模型。
- 与节点/交换机中的 SM Agent 通信。
- 子网管理。
- 提供路径记录。
- QoS 管理。
- 通信管理。
IB 网络分区
- 可为以下对象定义不同分区:
- 不同客户。
- 不同应用。
- 安全目的。
- 服务质量。
- 分区被定义为一组允许相互通信的通道适配器(例如 HCA)、路由器端口和交换机端口。
- 一个端口可以同时属于多个分区。
- 每个分区都有一个 Partition Key(PKEY)标识符。
- 一个分区由 15 位分区 ID 表示,理论上允许最多 32K 个分区。
- 一个或多个 PKEY 由子网的分区管理器(PM)分配给端口。
- 示例:
PKEY ID 2, Service Level 3PKEY ID 3, Service Level 3PKEY ID 3, Service Level 1
IB 的主要应用
- 应用集群。
- 集群就是一组由负载均衡交换机连接、并行工作以服务特定应用的服务器。
- 存储区域网络。
- 简化存储与服务器之间的连接。
- 移除 Fibre Channel 网络后,服务器可直接连接到存储区域网络,而无需昂贵的 HBA。
- 远程 DMA(RDMA)支持同时的点到点通信和端到端流量控制。
- InfiniBand 可克服 Fibre Channel 的不足,并且不需要昂贵、复杂的 HBA。
- 层间通信。
- 处理器间通信。
- InfiniBand 定义的更高带宽连接(4X、12X)可为 IPC 集群提供骨干能力,而无需第二套 I/O 互连。
软件定义网络 SDN
传统网络的限制
- 传统网络将硬件(数据转发)与软件(控制)集成在一起。
- 数据平面或转发平面负责实际转发数据。
- 控制平面负责控制逻辑。
- 本页图中每个交换节点都同时包含 Control 和 Data。
软件定义网络
- 将数据平面与控制平面解耦。
- 使用集中式控制器。
- 拥有资源的集中视图。
- 网络可编程,能够敏捷响应任何调整需求。
- SDN 是一种网络范式,使用基于软件的控制器或应用程序编程接口(API)与底层硬件基础设施通信,并指挥网络流量。
SDN 架构
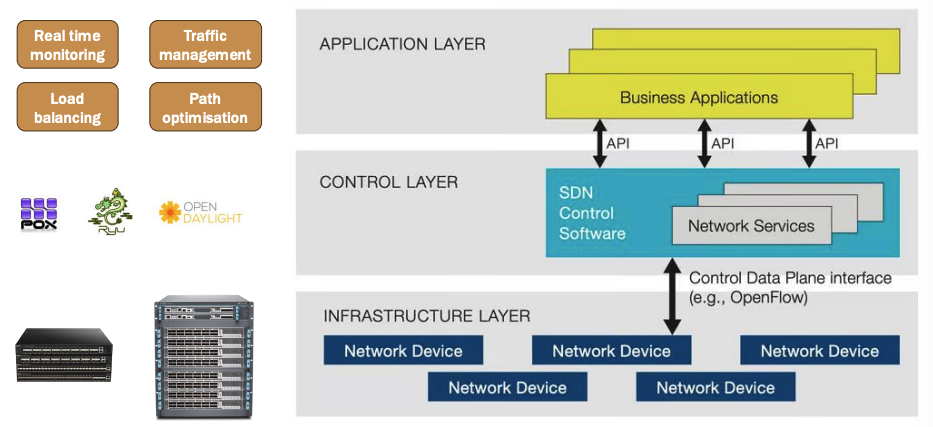
- 应用示例包括:实时监控、流量管理、负载均衡、路径优化。
OpenFlow
- OpenFlow 是 SDN 架构中定义在控制层与转发层之间的第一个标准通信接口。
- 它允许直接访问和操纵交换机、路由器等网络设备的转发平面。
- 它使 IT 能够应对当今应用的高带宽和动态特征,并让网络适应不断变化的业务需求。
流表
Flow Table
- 流表项(OpenFlow 1.0)包含:
- Header fields:头部字段,也就是规则。
- Actions:动作,也就是指令。
- Counters:计数器,也就是统计信息。
- 计数器记录由规则处理的分组数和字节数。
- 常见动作包括:
- 将分组转发到一个或多个端口。
- 封装并转发给控制器。
- 发送到正常处理流水线。
- 修改字段。
- 丢弃分组。
- 任何自定义扩展动作。
- OpenFlow 的演进:
- OpenFlow 1.0,2009 年 12 月,12 个匹配字段(Ethernet、TCP/IPv4)。
- OpenFlow 1.1,2011 年 2 月,15 个匹配字段(MPLS、表间元数据)。
- OpenFlow 1.2,2011 年 12 月,36 个匹配字段(ARP、ICMP、IPv6 等)。
- OpenFlow 1.3,2012 年 6 月,40 个匹配字段。
- OpenFlow 1.4,2013 年 10 月,41 个匹配字段。
- 匹配字段不断增加,以满足特定应用对匹配字段的需求。
流表项示例
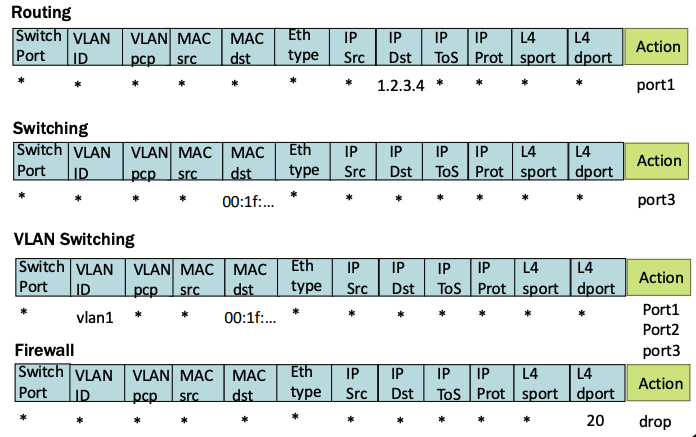
- 路由:根据目的 IP,例如
1.2.3.4,执行动作port1。 - 交换:根据目的 MAC,例如
00:1f:...,执行动作port3。 - VLAN 交换:根据 VLAN 和 MAC 等字段,将流量转发到
Port1、Port2或port3。 - 防火墙:根据匹配字段,例如目的端口
20,执行动作drop。
SDN 控制器
SDN CONTROLLER
- 常见控制器平台包括:
NOX:C++,第一个 OpenFlow 控制器。POX:Python,高层 SDN API,包含可查询的拓扑图并支持虚拟化。Beacon:Java,支持基于事件和基于线程的操作。Floodlight:Java,OpenFlow 控制器,由 Beacon 分叉而来。OpenDaylight:Java,源自最初的 Beacon 设计,支持 OpenFlow 和其他南向 API,并包含高可用性、集群等关键特性。
SDN 的优点
- 集中式网络控制。
- 智能流量工程。
- 改进网络服务质量。
- 网络分析。
- 网络可编程性,即开放的应用程序编程接口(API)。
- 节省成本。
- 增强安全性。
研究问题
- 控制器安全性与可靠性。
- 控制平面可扩展性:控制平面支持大规模网络。
- 控制器放置。
- 流表优化。
- 互操作性:SDN 与非 SDN。
- SDN 中的 AI。
网络功能虚拟化 NFV
NETWORK FUNCTIONS VIRTUALISATION, NFV
为什么需要 NFV?
- 专有硬件带来高 CAPEX 和 OPEX。
- 软件与硬件耦合。
- 厂商锁定:需要避免被厂商锁定。
- 单体式网络示例:4G LTE(Long Term Evolution)。
- EPC 的关键组件包括:
- Mobility Management Entity(MME)。
- Home Subscriber Server(HSS)。
- Serving Gateway(SGW)。
- Packet Data Network Gateway(PGW)。
- Policy and Charging Rules Function(PCRF)。
- 这些组件共同管理网络中的用户移动性、认证、数据路由和策略执行。
NFV 如何解决这些问题?
- NFV 使用虚拟机或容器替代网络设备硬件。
- 将专有硬件改为通用硬件。
- 将网络功能转变为软件。
- 构建在虚拟机或容器之上。
- 将网络功能与硬件分离。
- 示例功能包括
MME、HSS、SGW、PGW等。
NFV 在实践中如何实现?
- 软件化(Softwarisation)。
- 虚拟化(Virtualisation)。
- 编排(Orchestration)。
NFV 标准化:ETSI ISG NFV
- ETSI ISG NFV 是 NFV 的主要标准化组织
- NFV 概念验证(Proofs of Concept)。
- NFV Plugtests Programme:互操作性测试。
- NFV 教程。
ETSI ISG NFV 版本
- 以 2 年为阶段开展工作。
- 2013-2014:NFV 概念早期阶段。
- 2015-2016:NFV Release 2,设备和服务的端到端互通。
- 2017-2018:NFV Release 3,丰富 NFV 架构框架。
- 2019-2020:NFV Release 4,MANO 与 NFV 增强。
- 2021-2022:NFV Release 5,在 Release 4 基础上的新特性,以及面向 5G 的 NFV 增强。
- 2023-2024:NFV Release 6,包含接口、建模等的架构和基础设施,用于扩展当前特性并引入新特性。
高层 NFV 框架
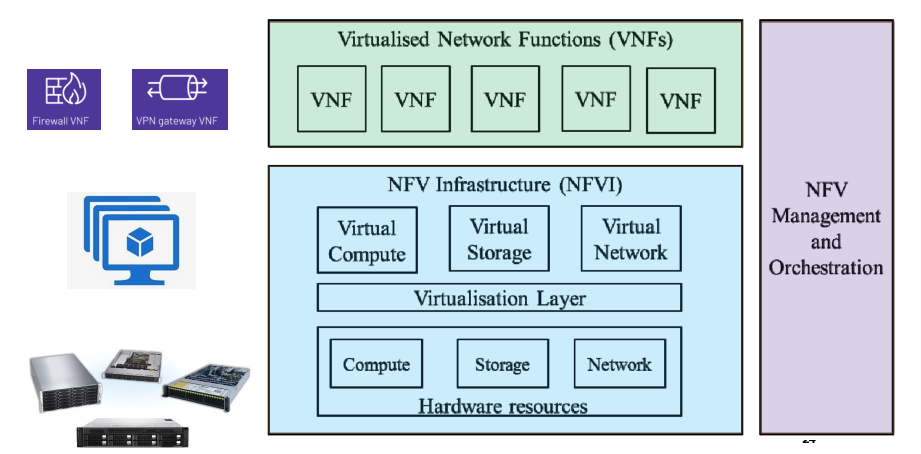
虚拟机 vs 容器
(本页为 VM 与 Container 对比示意图)
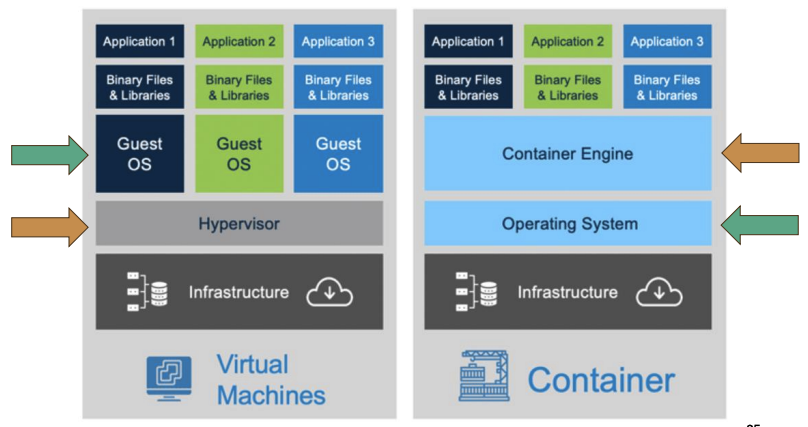
NFV 中的网络服务
(本页为 NFV 网络服务示意图)
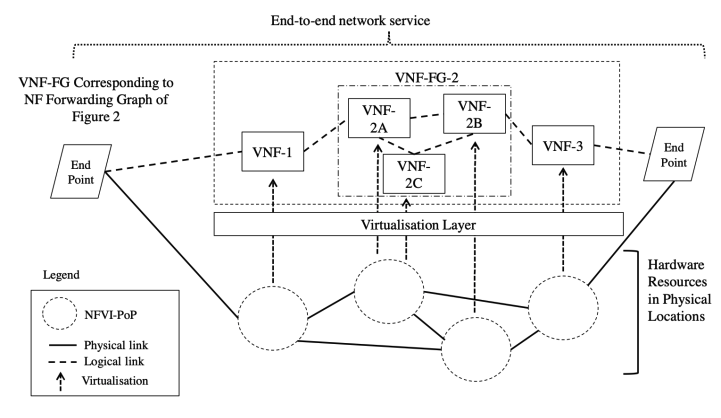
NFV 的关键好处
- 降低运营商 CAPEX 和 OPEX。
- 增强网络灵活性。
- 改进服务交付。
研究问题
- 安全威胁:Hypervisor 漏洞、来自不同厂商的组件集成。
- 编排:资源分配、多域编排。
- 可靠性。
- 网络服务异常检测。
- NFV 中的 AI。
SDN 与 NFV 的集成
关键差异
| 维度 | SDN | NFV |
|---|---|---|
| 关注点 | 网络操作的集中式控制 | 网络功能虚拟化 |
| 核心技术 | 解耦控制平面和数据平面 | 将网络功能作为 VNF 运行 |
| 硬件依赖 | 需要支持 SDN 的设备,例如 OpenFlow | 运行在标准服务器上,例如 x86 |
| 主要用例 | 流量工程、网络自动化 | 虚拟防火墙、虚拟交换机、电信 |
NFV + SDN:增强服务交付
- 新服务可以结合 NFV 与 SDN 实现。
- NFV 提供虚拟计算。
- SDN 提供网络可达性。
- 二者结合可更灵活地组合服务链与网络路径。
网络切片
NETWORK SLICING
- 网络切片是一种把一个物理网络划分为多个虚拟网络的技术。
- 每个虚拟网络都可针对特定需求进行定制。
- 底层物理基础设施包括网络、计算和存储资源。
- 详见下一个lecture
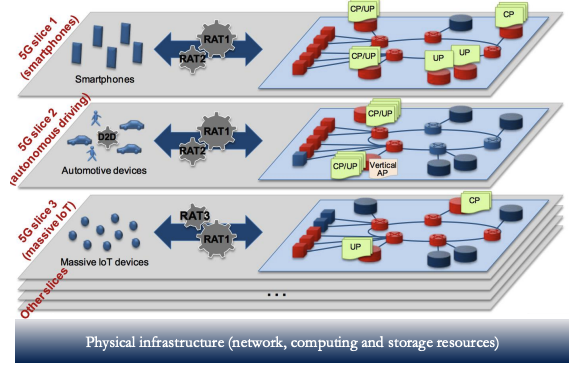
课后问题
回答由 AI 生成
- “将控制与转发解耦”如何改进网络管理?
控制平面和转发平面分离后,控制器集中决定路由和策略,交换机只负责按规则转发。这样网络管理更集中、更易配置,也更容易编程和快速更新策略。
After separating the control plane from the forwarding plane, the controller centrally decides routing and policies, while switches only forward packets according to rules. This makes network management more centralized, easier to configure, easier to program, and faster to update policies.
- “将网络功能与硬件分离”如何促进网络服务交付?
网络功能和硬件分离后,防火墙、NAT、负载均衡等功能可以作为软件运行在通用服务器上,而不是依赖专用设备。这样服务部署、扩展、升级和迁移都更快,成本更低,灵活性更高。
After separating network functions from hardware, functions such as firewalls, NAT, and load balancing can run as software on general-purpose servers instead of relying on dedicated devices. This makes service deployment, scaling, upgrading, and migration faster, cheaper, and more flexible.
网络切片
网络切片
NETWORK SLICING
- 网络切片是运行在共享物理基础设施上的、隔离的端到端(E2E)虚拟化网络,并且可以被独立控制和管理。
- 它用于高效承载广泛的服务类型,并满足多样化的 SLA 需求。
网络切片的实现步骤
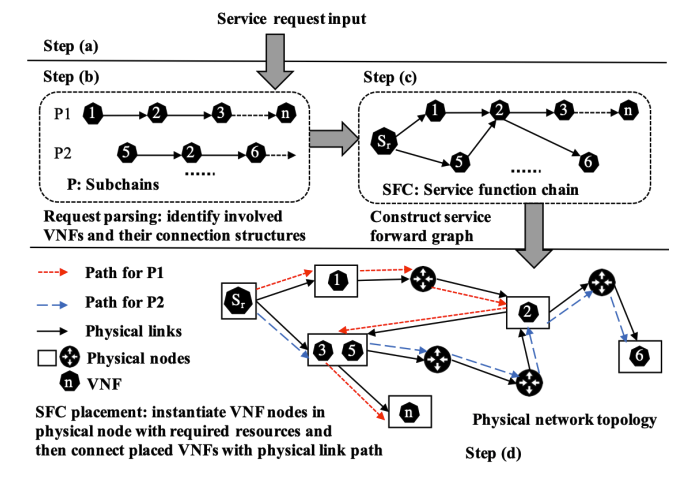
- SDN 和 NFV 是网络切片的两项使能技术。
- NFV:用于虚拟计算。
- SDN:用于网络可达性。
网络切片中的关键脆弱性
- 隔离失效。
- 配置错误,包括资源分配、性能参数和安全策略方面的问题。
- 不安全的应用程序编程接口(APIs),尤其是在动态管理和编排过程中。
- 供应链脆弱性。
网络数字孪生
NETWORK DIGITAL TWIN
什么是数字孪生?
- 数字孪生(DT)是在物理对象或系统生命周期内,以双向通信方式构建的虚拟表示。
- 通过历史数据、实时数据和合成数据,数字孪生能够在许多“假如”场景中支持理解、学习、推理和知情决策。
为什么使用DT?
- 实时数字副本(高保真)和安全沙箱。
- “假如”实验。
- 双向通信。
- 人机交互:参与感与展示。
什么是网络DT?
网络数字孪生是一组虚拟模型/信息,用于模拟真实有线或无线网络(网络之网络)的:
- 架构、组件和过程。
- 上下文,例如状态、配置和关系。
- 行为。
其核心特征包括:
- 通过来自物理对应体的数据进行动态更新。
- 具有预测能力。
- 能够为实现价值的决策提供信息。
- 虚拟世界与物理世界之间的双向交互是核心。
网络数字孪生中的物理孪生通常包括架构、组件、过程、上下文和行为;数字孪生通常包括数据管理、建模、数据分析、测试和可信性,并通过决策机制与物理侧形成闭环。
如何构建网络DT?
- 输入是什么?
- 网络配置、资源/链路利用率、应用流量等。
- 输出是什么?
- 性能指标(时延、吞吐量等)、标签(正常、异常)、分类结果(Telnet、HTTP 等)。
- 如何保证双向通信?
- 可采用仿真、模拟、AI/ML 建模等方法。
研究问题
- 监测、数据收集和存储。
- 可扩展性。
- 处理不确定性和可信性。
原生 AI 网络
面向网络的 AI
- 网络将产生海量数据。
- AI/智能将在网络中发挥关键作用。
“补丁”“附加组件”“事后补救”
将 AI 作为补丁式、附加式或事后补救式能力时,可能出现以下问题:
- 碎片化自动化:只自动化孤立功能,缺少跨整个网络协议栈的无缝编排。
- 碎片化数据源:依赖来自不同系统组件的数据,这些数据可能并不完全兼容。
- 响应时间较慢:AI 没有深度嵌入网络功能,决策过程更慢。
- 可扩展性挑战:没有针对真实网络条件进行优化,例如多尺度异构性。
- 适应性挑战:缺少直接来自网络的上下文数据访问能力。
AI:从“补丁”到“嵌入”
将 AI 嵌入网络基础设施,有助于实现端到端和系统级优化。
AI:“嵌入”带来的语境变化
AI 生命周期管理需要考虑多类要素:
- AI 要素:
- 数据、模型/算法、(再)训练、评估和退役。
- 应用要素:
- 时延敏感性、带宽、可靠性需求、能效、移动性等。
- 网络要素:
- 连接、功能、计算、存储/RAM 等。
- 社会要素:
- 安全、可信性、可持续性、公平性、隐私和安全保障等。
AI 编排
AI 编排负责管理 AI 模型目录,并支持版本控制、自动化训练和跨多样环境的可扩展部署。它还会预测所需资源,以优化不同系统环境中的 AI 模型性能和效率。
潜在任务包括:
- AI 模型选择。
- AI 模型链式组合。
- AI 模型放置。
- 计算资源分配(CPU、GPU、TPU)。
- 模型拆分。
- 其他相关任务。
课后问题
- 为什么物理对象/系统与其数字孪生之间的双向通信是必要的?
回答由 AI 生成
Two-way communication is essential because the digital twin needs real-time data from the physical object to stay accurate, and the physical object needs feedback or control from the digital twin to improve its operation. Without this, it is only a passive model.
双向通信是必要的,因为数字孪生需要物理对象的实时数据来保持准确,而物理对象也需要数字孪生提供反馈或控制来优化运行。否则它只是一个被动模型。
附录*
*收录试卷中出现但可能不考察的题目
Eg. IGMP
来源:EENGM4211 - 2023 Q6
IGMP 未在课件中出现过
IGMP = Internet Group Management Protocol(互联网组管理协议)
IGMP 用于管理主机是否加入某个组播组(multicast group),实现主机与路由器之间的组成员通信。
Q6: Which of the following statement(s) is/are incorrect about IGMP protocol (all versions)?
(8 Pts)
a. IGMP messages can cause network congestion as a result of membership responses from network members.
✅ 正确:IGMP 查询后,多个主机同时响应 → congestion
b. IGMP is not critical for group management in multicast operation. The underlying routing protocol can take care of multicast group management.
❌ 错误:路由协议(如 PIM)不能替代 IGMP
c. IGMP supports general membership queries to keep track of the group membership of the groups in the network connected with the router.
✅ 正确
d. IGMP is a network layer protocol.
✅ 正确
e. To avoid network congestion, every node agrees on a fixed time interval at which they send the membership responses to the router.
❌ 错误:使用 随机延迟(random delay)
Eg. Multicast algorithms
来源:EENGM4211 - 2023 Q7
此题 GPT 和 Gemini 说法不一致
source-based tree 未在课件中出现过
Q7: For the multicast routing algorithms, choose the correct statement(s) from the following.
(8 Pts)
a. Both source-based tree and shared tree take into account the minimum route from source to destination in their respective settings.
b. Source-based routing tree mechanism for multicast is lightweight and preferred over the shared routing tree mechanism in all network topologies and conditions.
c. Source-based routing tree is beneficial in a sparse network whereas shared routing tree is more suitable for a dense network.
d. Shared routing tree for multicast is more favorable for a sparse network where we have fewer nodes in the network and it is easy to distribute the routing tree incurring low communication overhead.
e. Minimum end-to-end delay is not a priority in the construction of source-based tree.
Q8: Consider tree-based multicast mechanism and choose invalid statement(s) from the following statements.
(8 Pts)
a. In the core-based tree for multicast, if senders need to send a packet, they first send the packet to the core which the core then forwards to the intended receivers.
b. The core node (in CBT) has the multicast tree and therefore it is a natural choice for the packets from the senders to be delivered to the multicast group members.
c. Selection of Rendezvous Point - RP in Protocol Independent Multicast (PIM) sparse mode is not critical for the performance of the multicast function.
d. The core in CBT does not necessarily has the multicast tree. It uses reverse path forwarding to all the multicast group members.
e. The advantage of PIM is that it does not need a management protocol (IGMP) to manage the group memberships in multicasting.
Eg. TCP/UDP/IP
来源:EENGM4211 - 2023 Q13
Q13: Is the following statement correct? Do you agree or disagree? Elaborate on your choice. (5 Pts)
“TCP/UDP/IP provides the best effort services to the applications through acknowledgments and retransmission with guarantees on the delay and packet loss. Therefore, it is easier for multimedia applications to operate at their desired functionality”.
Answer:
Disagree.
TCP/UDP/IP provides best-effort service with no guarantees on delay or packet loss. TCP improves reliability but not delay, and UDP provides no reliability. Hence, multimedia applications cannot rely on it for required performance.