大数据应用项目实践:MapReduce实操
浙江理工大学 2024 大数据应用项目实践 实操 MapReduce
实操文档和项目代码
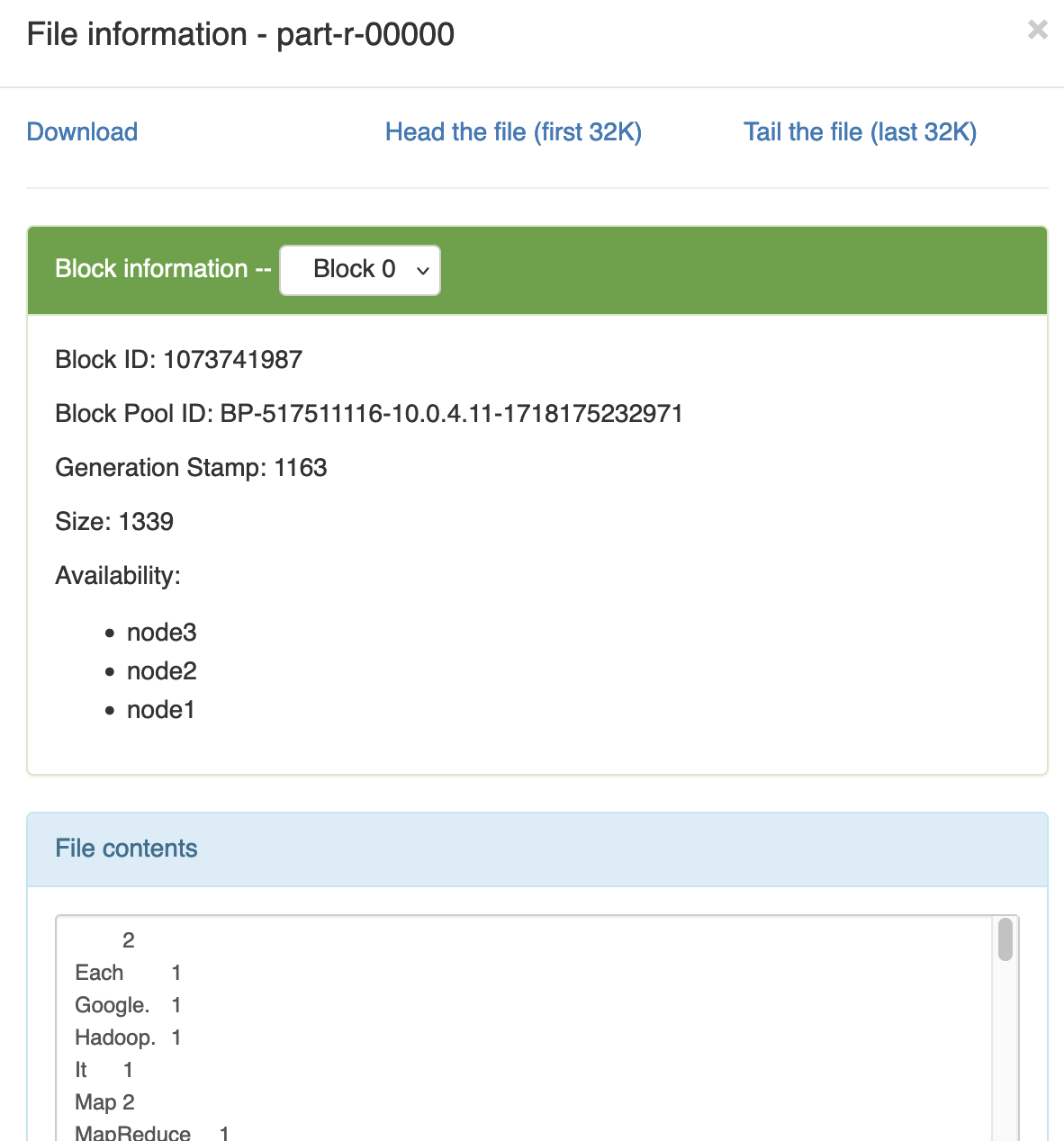
1.6 WordCount案例实操 1 需求 在给定的文本文件中统计输出每一个单词出现的总次数
2 数据准备 wordcount.txt
MapReduce is a programming model and processing technique for distributed computing, developed by Google. It enables the processing of large datasets across a cluster of computers in a parallel, reliable, and fault-tolerant manner. The model divides the task into two main functions: the Map function, which processes and filters data to produce key-value pairs, and the Reduce function, which aggregates and summarizes these pairs to produce the final output. The Map function takes input data and transforms it into a set of intermediate key-value pairs. Each pair consists of a key and a corresponding value, which are then shuffled and sorted by the system. This sorting and shuffling step is crucial as it groups all the values associated with the same key together, making it easier for the Reduce function to process them. This division allows for parallel processing, as different keys can be processed simultaneously on different nodes in the cluster. The Reduce function takes the grouped key-value pairs and performs an aggregation operation, such as summing, averaging, or concatenation, depending on the specific use case. The output of the Reduce function is then written to a distributed storage system, completing the processing cycle. MapReduce's ability to scale horizontally by adding more nodes to the cluster makes it highly efficient for handling massive datasets, making it a foundational technology for many big data processing frameworks like Hadoop.
3 分析 按照mapreduce编程规范,分别编写Mapper,Reducer,Driver,如图所示。
4 环境准备 创建一个Maven工程,在pom.xml的<project>中添加以下依赖:
<dependencies > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.12</version > </dependency > <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-core</artifactId > <version > 2.8.2</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.7.2</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > 2.7.2</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 2.7.2</version > </dependency > </dependencies >
在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=info, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5 编写程序 编写mapper类
package com.bigdata.mapreduce.wordcount;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class WordcountMapper extends Mapper <LongWritable, Text, Text, IntWritable>{ Text k = new Text (); IntWritable v = new IntWritable (1 ); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" " ); for (String word : words) { k.set(word); context.write(k, v); } } }
编写reducer类
package com.bigdata.mapreduce.wordcount;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;public class WordcountReducer extends Reducer <Text, IntWritable, Text, IntWritable>{int sum;IntWritable v = new IntWritable (); @Override protected void reduce (Text key, Iterable<IntWritable> value, Context context) throws IOException, InterruptedException { sum = 0 ; for (IntWritable count : value) { sum += count.get(); } v.set(sum); context.write(key,v); } }
编写驱动类
package com.bigdata.mapreduce.wordcount;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordcountDriver { public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration); job.setJarByClass(WordcountDriver.class); job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); job.waitForCompletion(true ); } }
6 运行 在Maven中package打包,将生成的wordcount-1.0-SNAPSHOT.jar上传至虚拟机中
然后将wordcount.txt放到 HDFS 的/wordcount/input/路径下
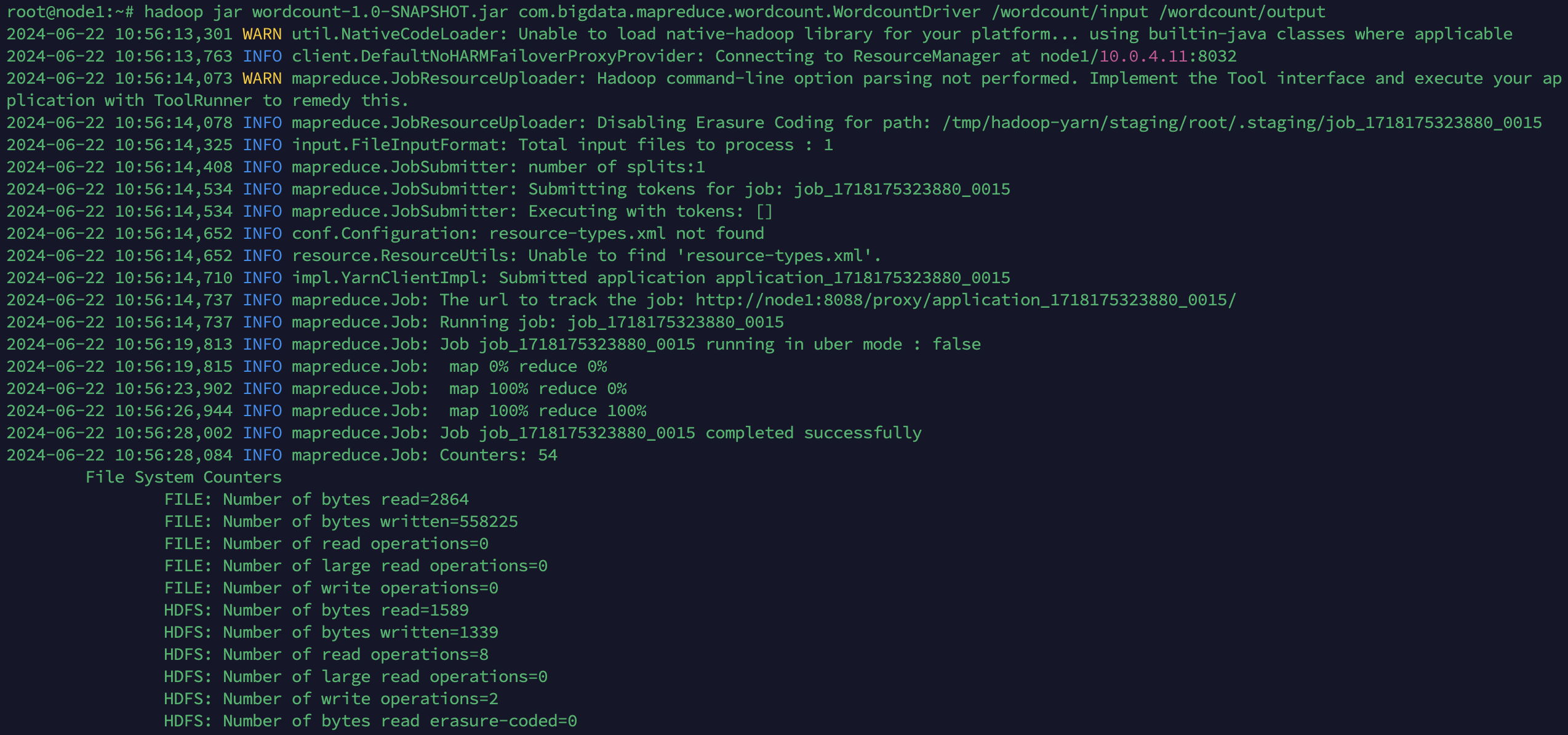
在虚拟机中执行以下命令运行
hadoop jar wordcount-1.0-SNAPSHOT.jar com.bigdata.mapreduce.wordcount.WordcountDriver /wordcount/input /wordcount/output
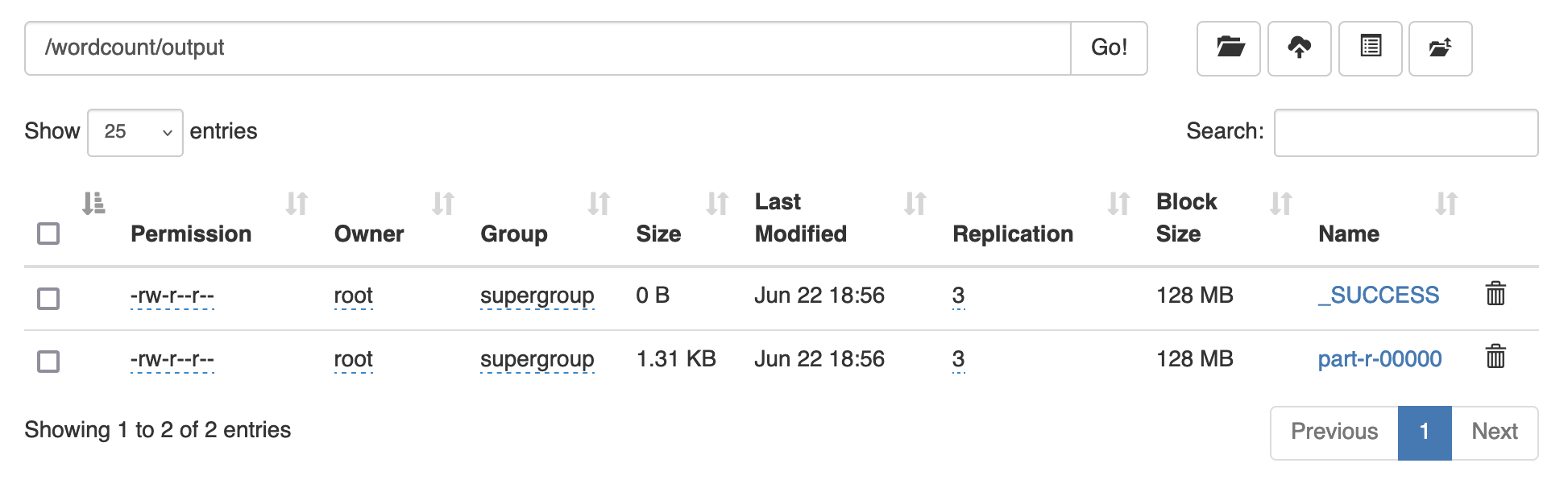
随后前往 /wordcount/output/ 查看结果
2.4 序列化案例实操 1 需求 统计每一个手机号耗费的总上行流量、下行流量、总流量
2 数据准备 注意数据间的分隔是制表符不是空格,若要改成空格,需要更改代码
phone_data.txt
1 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 2 13600001111 A1-B2-C3-D4-E5-F6:CU 192.168.100.10 19 16 7282 572 120 3 13722223333 A2-B2-C3-D4-E5-F6:CT 192.168.100.11 10 82 2881 828 182 4 13822223333 A3-B2-C3-D4-E5-F6:CT 192.168.101.12 12 83 2821 823 122
3 分析 基本思路:
Map阶段:
(1)读取一行数据,切分字段
(2)抽取手机号、上行流量、下行流量
(3)以手机号为key,bean对象为value输出,即context.write(手机号,bean);
Reduce阶段:
(1)累加上行流量和下行流量得到总流量。
(2)实现自定义的bean来封装流量信息,并将bean作为map输出的key来传输
(3) MR程序在处理数据的过程中会对数据排序(map输出的kv对传输到reduce之前,会排序),排序的依据是map输出的key
4 编写mapreduce程序
环境准备与上文相同
实操手册中的代码疑似有误,这里已改正:
在Reducer中存在一个累加逻辑的错误。将上行流量累加时使用了getSumFlow(),这个方法返回的是总流量,而不是单独的上行流量。并且在Reducer中没有正确地累加上行流量。
(1)编写流量统计的bean对象
package com.bigdata.mapreduce.flowsum;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.Writable;public class FlowBean implements Writable { private long upFlow ; private long downFlow; private long sumFlow; public FlowBean () { super (); } public FlowBean (long upFlow, long downFlow) { super (); this .upFlow = upFlow; this .downFlow = downFlow; this .sumFlow = upFlow + downFlow; } @Override public void write (DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } @Override public void readFields (DataInput in) throws IOException { this .upFlow = in.readLong(); this .downFlow = in.readLong(); this .sumFlow = in.readLong(); } @Override public String toString () { return upFlow + "\t" + downFlow + "\t" + sumFlow; } public long getUpFlow () { return upFlow; } public void setUpFlow (long upFlow) { this .upFlow = upFlow; } public long getDownFlow () { return downFlow; } public void setDownFlow (long downFlow) { this .downFlow = downFlow; } public long getSumFlow () { return sumFlow; } public void setSumFlow (long sumFlow) { this .sumFlow = sumFlow; } }
(2)编写mapper
package com.bigdata.mapreduce.flowsum;import java.io.IOException;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class FlowCountMapper extends Mapper <LongWritable, Text, Text, FlowBean>{ FlowBean v = new FlowBean (); Text k = new Text (); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t" ); String phoneNum = fields[1 ]; long upFlow = Long.parseLong(fields[fields.length - 3 ]); long downFlow = Long.parseLong(fields[fields.length - 2 ]); v.setUpFlow(upFlow); v.setDownFlow(downFlow); k.set(phoneNum); context.write(k, v); } }
(3)编写reducer
package com.bigdata.mapreduce.flowsum;import java.io.IOException;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;public class FlowCountReducer extends Reducer <Text, FlowBean, Text, FlowBean> { @Override protected void reduce (Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sum_upFlow = 0 ; long sum_downFlow = 0 ; for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); } FlowBean resultBean = new FlowBean (sum_upFlow, sum_downFlow); context.write(key, resultBean); } }
(4)编写驱动
package com.bigdata.mapreduce.flowsum;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class FlowsumDriver { public static void main (String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration); job.setJarByClass(FlowsumDriver.class); job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); boolean result = job.waitForCompletion(true ); System.exit(result ? 0 : 1 ); } }
5 运行 运行步骤与上文类似,其中hadoop命令如下
hadoop jar flowsum-1.0-SNAPSHOT.jar com.bigdata.mapreduce.flowsum.FlowsumDriver /flowsum/input /flowsum/output
预期输出:
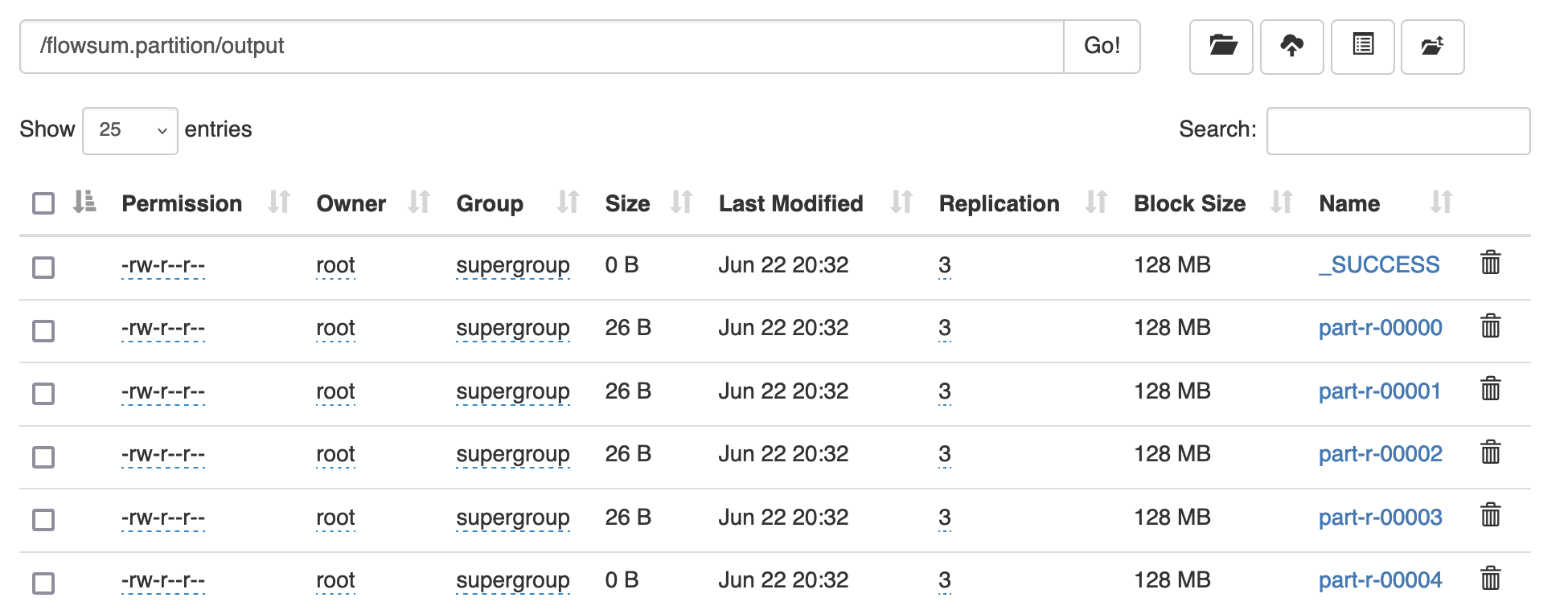
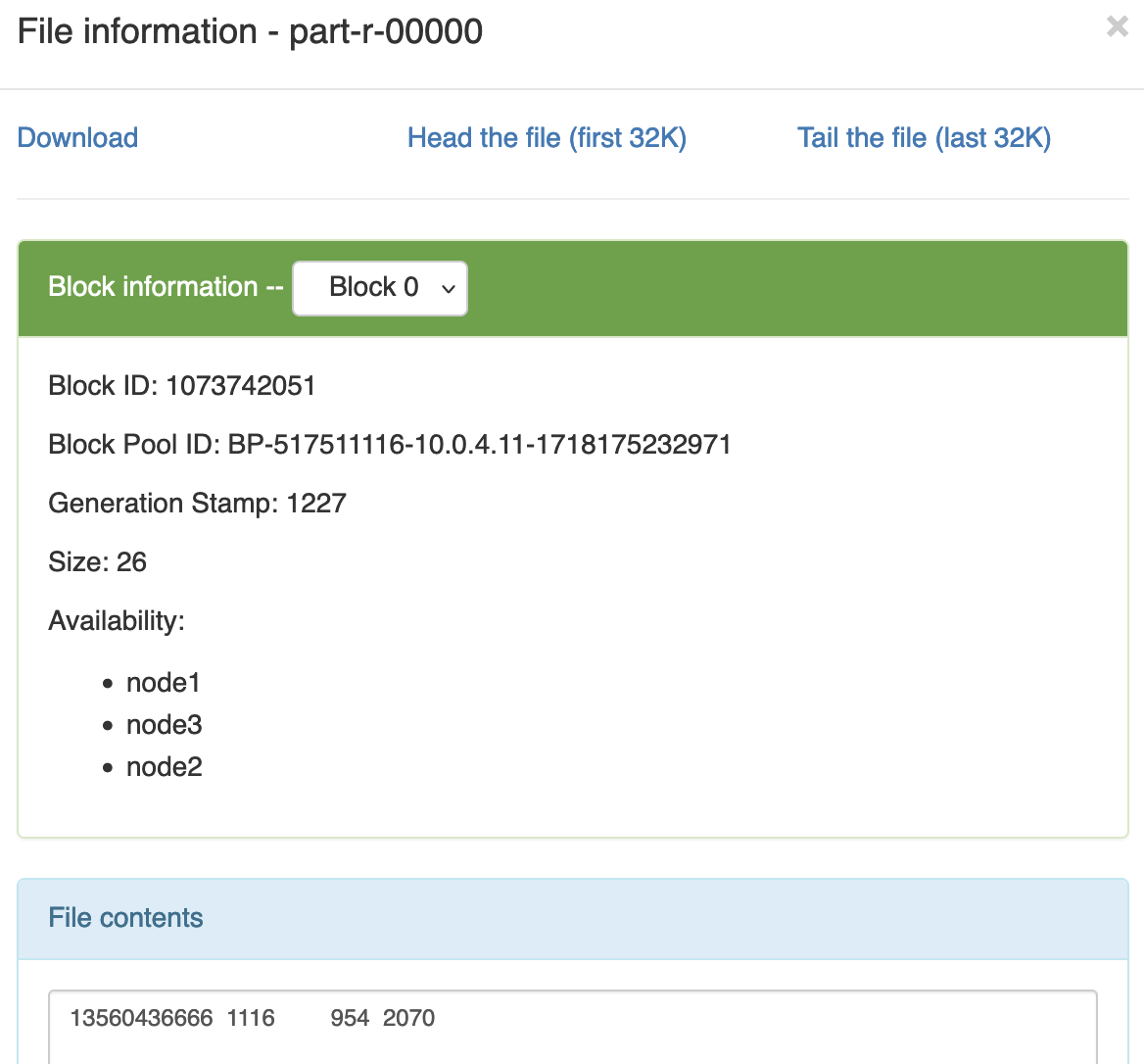
3.4.3 Partition分区案例实操 1 需求 将统计结果按照手机归属地不同省份输出到不同文件中(分区)
2 数据准备 注意数据间的分隔是制表符不是空格,若要改成空格,需要更改代码
phone_data.txt
1 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 2 13600001111 A1-B2-C3-D4-E5-F6:CU 192.168.100.10 19 16 7282 572 120 3 13722223333 A2-B2-C3-D4-E5-F6:CT 192.168.100.11 10 82 2881 828 182 4 13822223333 A3-B2-C3-D4-E5-F6:CT 192.168.101.12 12 83 2821 823 122
3 分析 (1)Mapreduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask。默认的分发规则为:根据key的hashcode%reducetask数来分发
(2)如果要按照我们自己的需求进行分组,则需要改写数据分发(分组)组件Partitioner
(3)在job驱动中,设置自定义partitioner: job.setPartitionerClass(CustomPartitioner.class)
4 代码编写 在案例2.4的基础上,增加一个分区类
package com.bigdata.mapreduce.flowsum;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner extends Partitioner <Text, FlowBean> { @Override public int getPartition (Text key, FlowBean value, int numPartitions) { String preNum = key.toString().substring(0 , 3 ); int partition = 4 ; if ("135" .equals(preNum)) { partition = 0 ; }else if ("136" .equals(preNum)) { partition = 1 ; }else if ("137" .equals(preNum)) { partition = 2 ; }else if ("138" .equals(preNum)) { partition = 3 ; } return partition; } }
在驱动函数中增加自定义数据分区设置和reduce task设置
package com.bigdata.mapreduce.flowsum;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class FlowsumDriver { public static void main (String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration); job.setJarByClass(FlowsumDriver.class); job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); job.setPartitionerClass(ProvincePartitioner.class); job.setNumReduceTasks(5 ); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); boolean result = job.waitForCompletion(true ); System.exit(result ? 0 : 1 ); } }
5 运行 运行步骤与上文类似,其中hadoop命令如下
hadoop jar flowsum.partition-1.0-SNAPSHOT.jar com.bigdata.mapreduce.flowsum.FlowsumDriver /flowsum.partition/input /flowsum.partition/output
预期输出:
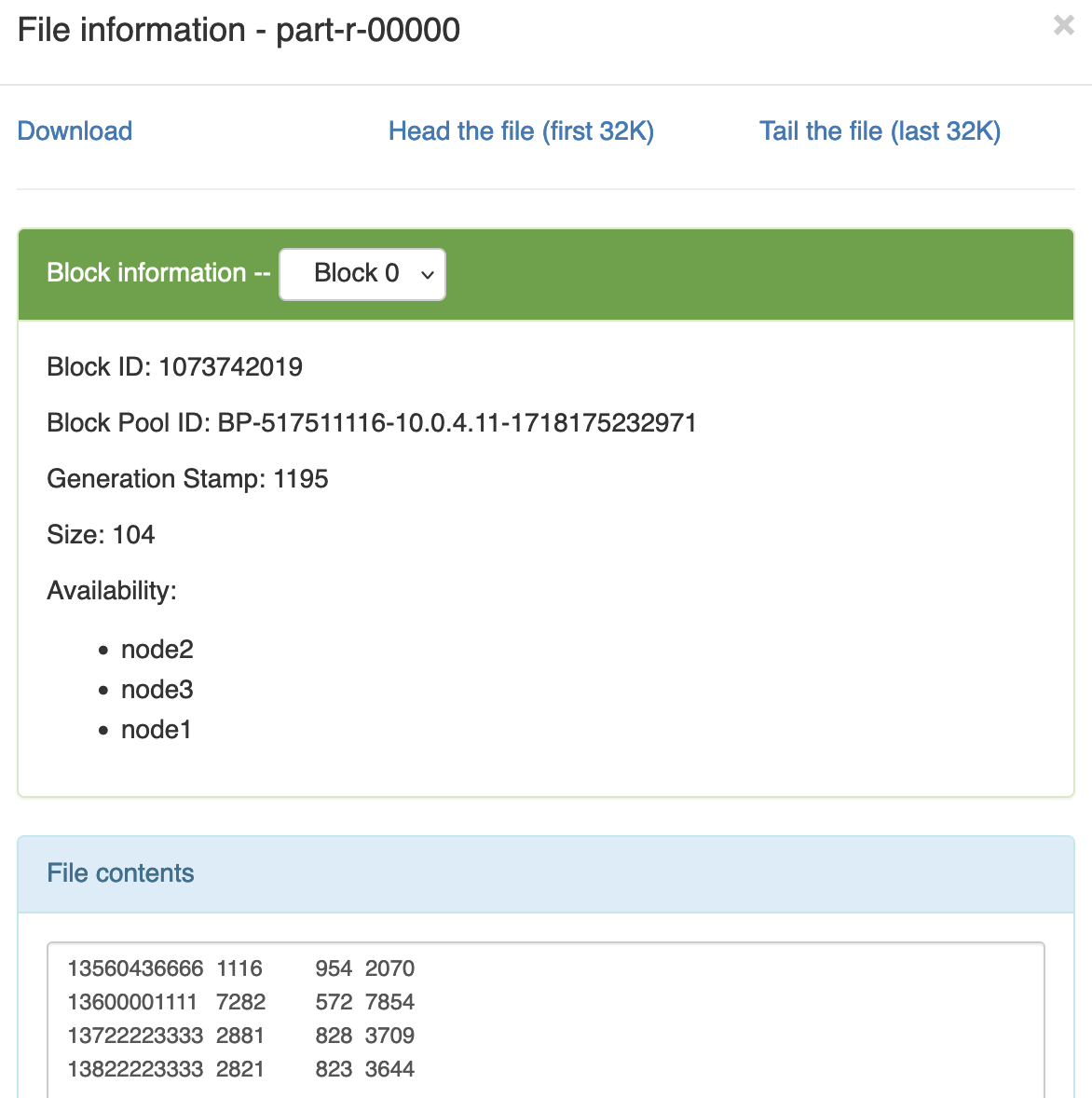
3.4.5 WritableComparable排序案例实操 1 需求 根据案例2.4产生的结果再次对总流量进行排序。
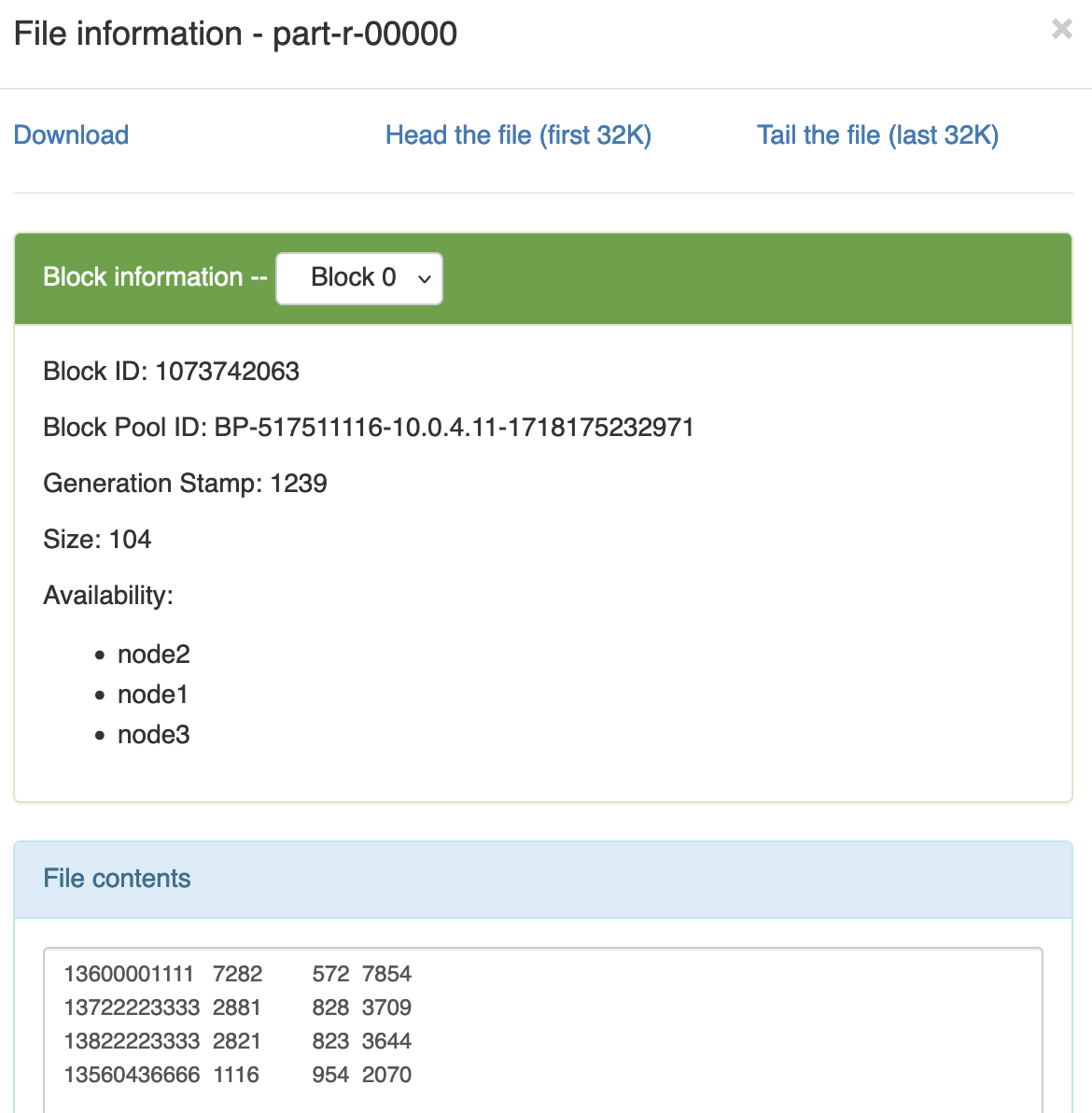
2 数据准备 /flowsum/output
13560436666 1116 954 2070 13600001111 7282 572 7854 13722223333 2881 828 3709 13822223333 2821 823 3644
3 分析 (1)把程序分两步走,第一步正常统计总流量,第二步再把结果进行排序
(2)context.write(bean<总流量>,手机号)
(3)FlowBean实现WritableComparable接口重写compareTo方法
@Override public int compareTo (FlowBean o) { return this .sumFlow > o.getSumFlow() ? -1 : 1 ; }
4 代码实现 (1)FlowBean对象在在需求1基础上增加了比较功能
package com.bigdata.mapreduce.sort;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class FlowBean implements WritableComparable <FlowBean> { private long upFlow; private long downFlow; private long sumFlow; public FlowBean () { super (); } public FlowBean (long upFlow, long downFlow) { super (); this .upFlow = upFlow; this .downFlow = downFlow; this .sumFlow = upFlow + downFlow; } public void set (long upFlow, long downFlow) { this .upFlow = upFlow; this .downFlow = downFlow; this .sumFlow = upFlow + downFlow; } public long getSumFlow () { return sumFlow; } public void setSumFlow (long sumFlow) { this .sumFlow = sumFlow; } public long getUpFlow () { return upFlow; } public void setUpFlow (long upFlow) { this .upFlow = upFlow; } public long getDownFlow () { return downFlow; } public void setDownFlow (long downFlow) { this .downFlow = downFlow; } @Override public void write (DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } @Override public void readFields (DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } @Override public String toString () { return upFlow + "\t" + downFlow + "\t" + sumFlow; } @Override public int compareTo (FlowBean o) { return this .sumFlow > o.getSumFlow() ? -1 : 1 ; } }
(2)编写mapper
package com.bigdata.mapreduce.sort;import java.io.IOException;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class FlowCountSortMapper extends Mapper <LongWritable, Text, FlowBean, Text>{ FlowBean bean = new FlowBean (); Text v = new Text (); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t" ); String phoneNbr = fields[0 ]; long upFlow = Long.parseLong(fields[1 ]); long downFlow = Long.parseLong(fields[2 ]); bean.set(upFlow, downFlow); v.set(phoneNbr); context.write(bean, v); } }
(3)编写reducer
package com.bigdata.mapreduce.sort;import java.io.IOException;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;public class FlowCountSortReducer extends Reducer <FlowBean, Text, Text, FlowBean>{ @Override protected void reduce (FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text text : values) { context.write(text, key); } } }
(4)编写driver
package com.bigdata.mapreduce.sort;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class FlowCountSortDriver { public static void main (String[] args) throws ClassNotFoundException, IOException, InterruptedException { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration); job.setJarByClass(FlowCountSortDriver.class); job.setMapperClass(FlowCountSortMapper.class); job.setReducerClass(FlowCountSortReducer.class); job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); boolean result = job.waitForCompletion(true ); System.exit(result ? 0 : 1 ); } }
5 运行 运行步骤与上文类似,其中hadoop命令如下
hadoop jar sort-1.0-SNAPSHOT.jar com.bigdata.mapreduce.sort.FlowCountSortDriver /flowsum/output /sort/output
预期输出:
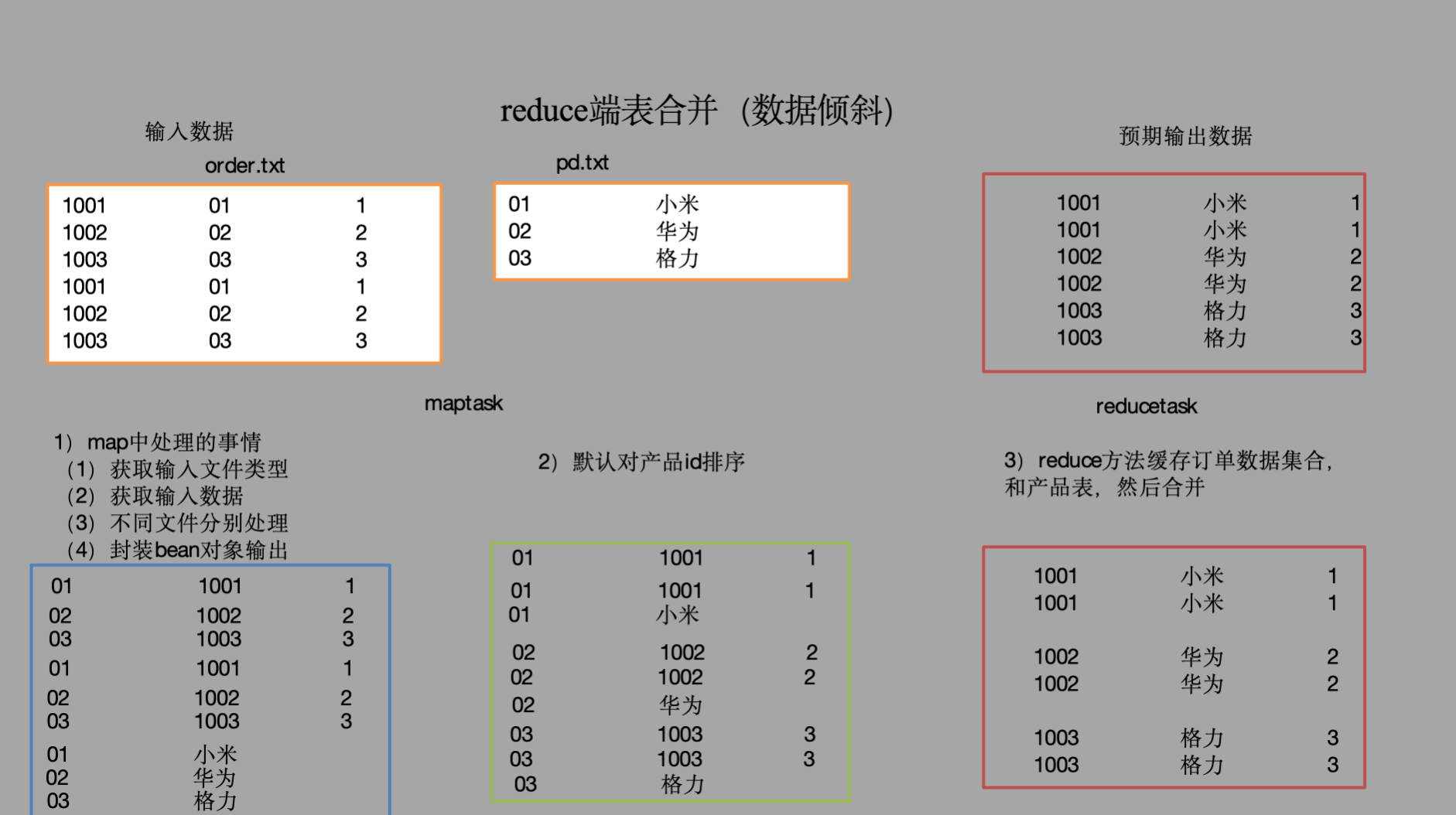
3.6.2 Reduce join案例实操 1 需求 数据准备
注意数据间用制表符分隔,不是空格
合并表:
order.txt
id | pid | amount
1001 01 1 1002 02 2 1003 03 3 1001 01 1 1002 02 2 1003 03 3
pd.txt
pid | name
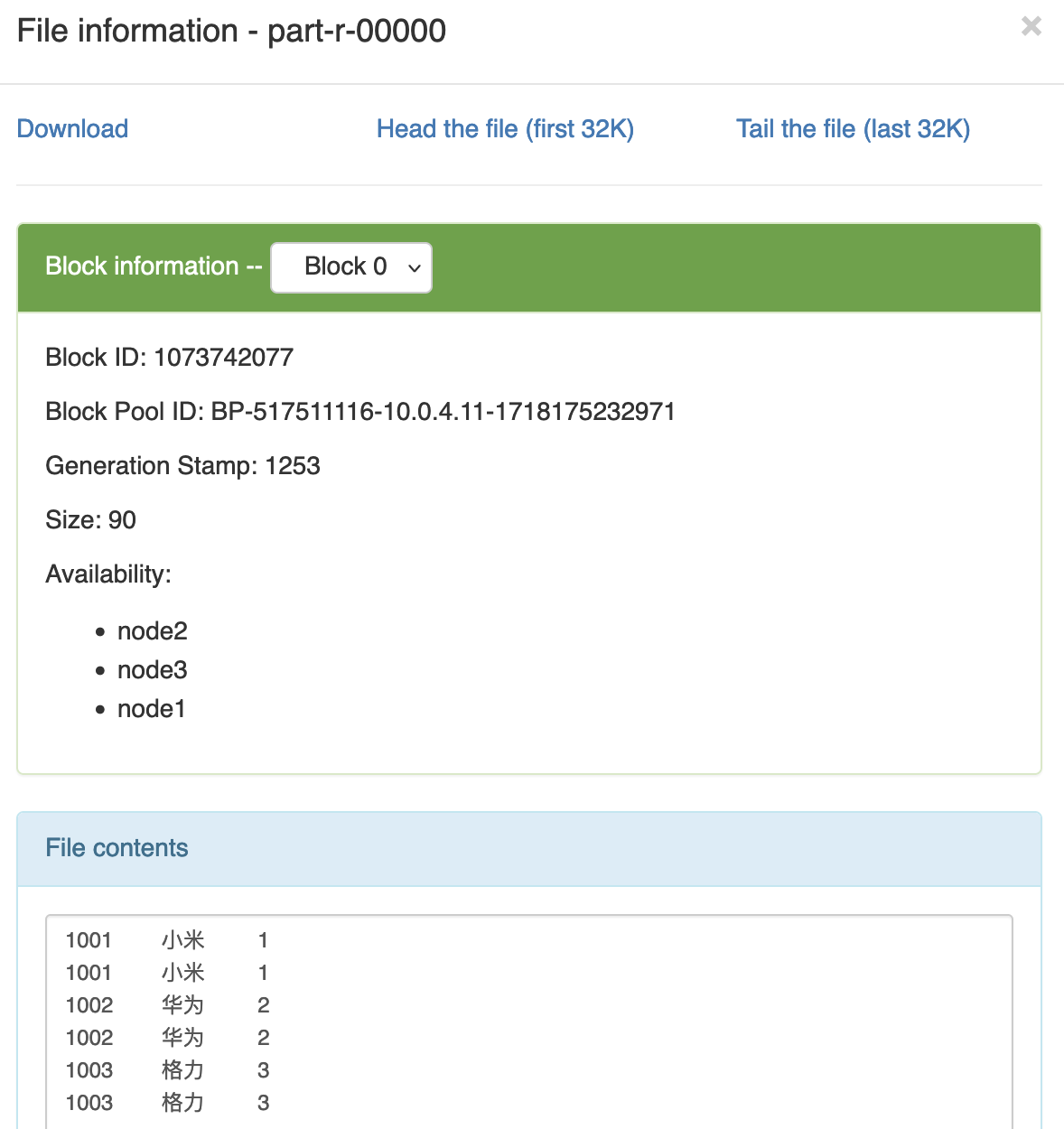
预期输出
1001 小米 1 1001 小米 1 1002 华为 2 1002 华为 2 1003 格力 3 1003 格力 3
通过将关联条件作为map输出的key,将两表满足join条件的数据(包含数据来源于哪一个文件的标识),发往同一个reduce task,在reduce中进行数据的串联,如图所示
2 代码实现 1)创建商品和订单合并后的bean类
package com.bigdata.mapreduce.table;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.Writable;public class TableBean implements Writable { private String order_id; private String p_id; private int amount; private String pname; private String flag; public TableBean () { super (); } public TableBean (String order_id, String p_id, int amount, String pname, String flag) { super (); this .order_id = order_id; this .p_id = p_id; this .amount = amount; this .pname = pname; this .flag = flag; } public String getFlag () { return flag; } public void setFlag (String flag) { this .flag = flag; } public String getOrder_id () { return order_id; } public void setOrder_id (String order_id) { this .order_id = order_id; } public String getP_id () { return p_id; } public void setP_id (String p_id) { this .p_id = p_id; } public int getAmount () { return amount; } public void setAmount (int amount) { this .amount = amount; } public String getPname () { return pname; } public void setPname (String pname) { this .pname = pname; } @Override public void write (DataOutput out) throws IOException { out.writeUTF(order_id); out.writeUTF(p_id); out.writeInt(amount); out.writeUTF(pname); out.writeUTF(flag); } @Override public void readFields (DataInput in) throws IOException { this .order_id = in.readUTF(); this .p_id = in.readUTF(); this .amount = in.readInt(); this .pname = in.readUTF(); this .flag = in.readUTF(); } @Override public String toString () { return order_id + "\t" + pname + "\t" + amount + "\t" ; } }
2)编写TableMapper程序
package com.bigdata.mapreduce.table;import java.io.IOException;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileSplit;public class TableMapper extends Mapper <LongWritable, Text, Text, TableBean>{ TableBean bean = new TableBean (); Text k = new Text (); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { FileSplit split = (FileSplit) context.getInputSplit(); String name = split.getPath().getName(); String line = value.toString(); if (name.startsWith("order" )) { String[] fields = line.split("\t" ); bean.setOrder_id(fields[0 ]); bean.setP_id(fields[1 ]); bean.setAmount(Integer.parseInt(fields[2 ])); bean.setPname("" ); bean.setFlag("0" ); k.set(fields[1 ]); }else { String[] fields = line.split("\t" ); bean.setP_id(fields[0 ]); bean.setPname(fields[1 ]); bean.setFlag("1" ); bean.setAmount(0 ); bean.setOrder_id("" ); k.set(fields[0 ]); } context.write(k, bean); } }
3)编写TableReducer程序
package com.bigdata.mapreduce.table;import java.io.IOException;import java.util.ArrayList;import org.apache.commons.beanutils.BeanUtils;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;public class TableReducer extends Reducer <Text, TableBean, TableBean, NullWritable> { @Override protected void reduce (Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException { ArrayList<TableBean> orderBeans = new ArrayList <>(); TableBean pdBean = new TableBean (); for (TableBean bean : values) { if ("0" .equals(bean.getFlag())) { TableBean orderBean = new TableBean (); try { BeanUtils.copyProperties(orderBean, bean); } catch (Exception e) { e.printStackTrace(); } orderBeans.add(orderBean); } else { try { BeanUtils.copyProperties(pdBean, bean); } catch (Exception e) { e.printStackTrace(); } } } for (TableBean bean:orderBeans){ bean.setPname (pdBean.getPname()); context.write(bean, NullWritable.get()); } } }
4)编写TableDriver程序
package com.bigdata.mapreduce.table;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class TableDriver { public static void main (String[] args) throws Exception { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration); job.setJarByClass(TableDriver.class); job.setMapperClass(TableMapper.class); job.setReducerClass(TableReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(TableBean.class); job.setOutputKeyClass(TableBean.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); boolean result = job.waitForCompletion(true ); System.exit(result ? 0 : 1 ); } }
缺点:这种方式中,合并的操作是在reduce阶段完成,reduce端的处理压力太大,map节点的运算负载则很低,资源利用率不高,且在reduce阶段极易产生数据倾斜(同一个reduce接收到的数据量很大)
3 运行 运行步骤与上文类似,其中hadoop命令如下(order.txt和pd.txt放在/table/input中)
hadoop jar table-1.0-SNAPSHOT.jar com.bigdata.mapreduce.table.TableDriver /table/input /table/output
预期输出:
7.3 辅助排序和二次排序案例 1 需求 有如下订单数据
订单id 商品id 成交金额
现在需要求出每一个订单中最贵的商品。
2 输入数据 GroupingComparator.txt
注意数据间用制表符分隔,不是空格
0000001 Pdt_01 222.8 0000001 Pdt_06 25.8 0000002 Pdt_03 522.8 0000002 Pdt_04 122.4 0000002 Pdt_05 722.4 0000003 Pdt_01 222.8 0000003 Pdt_02 33.8
3 分析 (1)利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce。
(2)在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值。
4 代码实现 (1)定义订单信息OrderBean
package com.bigdata.mapreduce.order;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class OrderBean implements WritableComparable <OrderBean> { private int order_id; private double price; public OrderBean () { super (); } public OrderBean (int order_id, double price) { super (); this .order_id = order_id; this .price = price; } @Override public void write (DataOutput out) throws IOException { out.writeInt(order_id); out.writeDouble(price); } @Override public void readFields (DataInput in) throws IOException { order_id = in.readInt(); price = in.readDouble(); } @Override public String toString () { return order_id + "\t" + price; } public int getOrder_id () { return order_id; } public void setOrder_id (int order_id) { this .order_id = order_id; } public double getPrice () { return price; } public void setPrice (double price) { this .price = price; } @Override public int compareTo (OrderBean o) { int result; if (order_id > o.getOrder_id()) { result = 1 ; } else if (order_id < o.getOrder_id()) { result = -1 ; } else { result = price > o.getPrice() ? -1 : 1 ; } return result; } }
(2)编写OrderSortMapper
package com.bigdata.mapreduce.order;import java.io.IOException;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class OrderMapper extends Mapper <LongWritable, Text, OrderBean, NullWritable> { OrderBean k = new OrderBean (); @Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t" ); k.setOrder_id(Integer.parseInt(fields[0 ])); k.setPrice(Double.parseDouble(fields[2 ])); context.write(k, NullWritable.get()); } }
(3)编写OrderSortPartitioner
package com.bigdata.mapreduce.order;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Partitioner;public class OrderPartitioner extends Partitioner <OrderBean, NullWritable> { @Override public int getPartition (OrderBean key, NullWritable value, int numReduceTasks) { return (key.getOrder_id() & Integer.MAX_VALUE) % numReduceTasks; } }
(4)编写OrderSortGroupingComparator
package com.bigdata.mapreduce.order;import org.apache.hadoop.io.WritableComparable;import org.apache.hadoop.io.WritableComparator;public class OrderGroupingComparator extends WritableComparator { protected OrderGroupingComparator () { super (OrderBean.class, true ); } @SuppressWarnings("rawtypes") @Override public int compare (WritableComparable a, WritableComparable b) { OrderBean aBean = (OrderBean) a; OrderBean bBean = (OrderBean) b; int result; if (aBean.getOrder_id() > bBean.getOrder_id()) { result = 1 ; } else if (aBean.getOrder_id() < bBean.getOrder_id()) { result = -1 ; } else { result = 0 ; } return result; } }
(5)编写OrderSortReducer
package com.bigdata.mapreduce.order;import java.io.IOException;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Reducer;public class OrderReducer extends Reducer <OrderBean, NullWritable, OrderBean, NullWritable> { @Override protected void reduce (OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }
(6)编写OrderSortDriver
package com.bigdata.mapreduce.order;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class OrderDriver { public static void main (String[] args) throws Exception, IOException { Configuration conf = new Configuration (); Job job = Job.getInstance(conf); job.setJarByClass(OrderDriver.class); job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReducer.class); job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path (args[0 ])); FileOutputFormat.setOutputPath(job, new Path (args[1 ])); job.setGroupingComparatorClass(OrderGroupingComparator.class); job.setPartitionerClass(OrderPartitioner.class); job.setNumReduceTasks(3 ); boolean result = job.waitForCompletion(true ); System.exit(result ? 0 : 1 ); } }
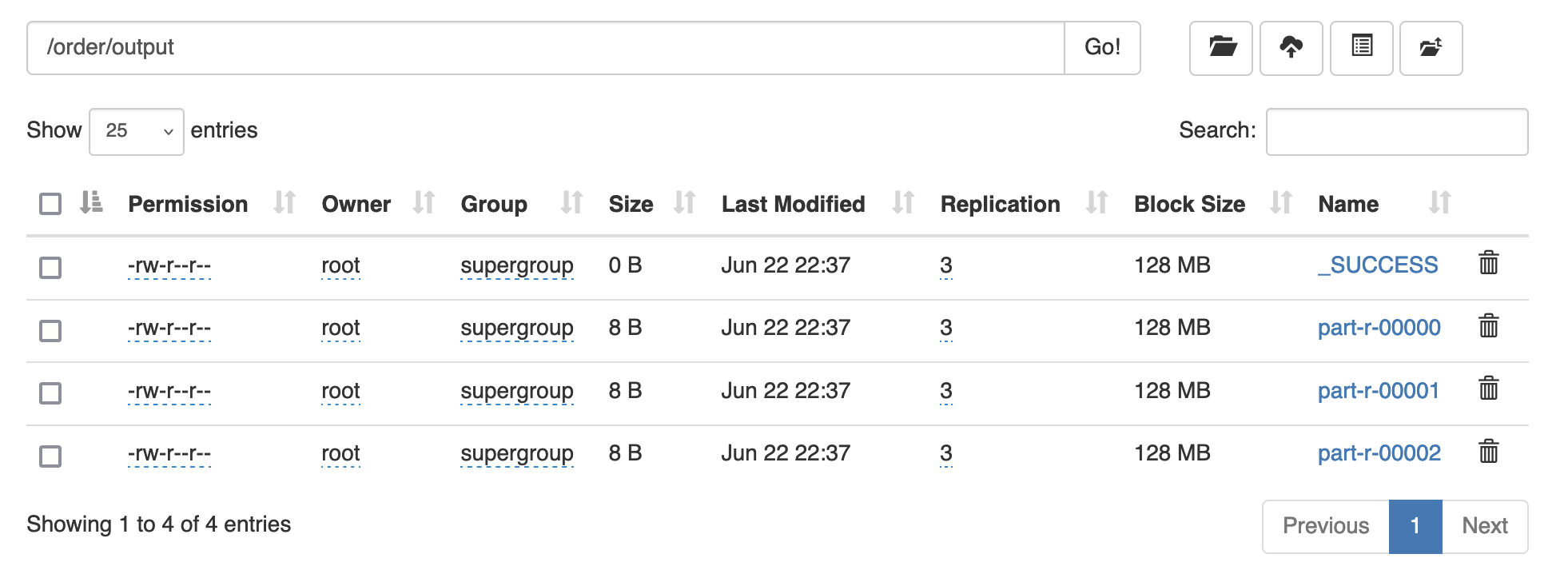
5 运行 运行步骤与上文类似,其中hadoop命令如下(order.txt和pd.txt放在/table/input中)
hadoop jar order-1.0-SNAPSHOT.jar com.bigdata.mapreduce.order.OrderDriver /order/input /order/output
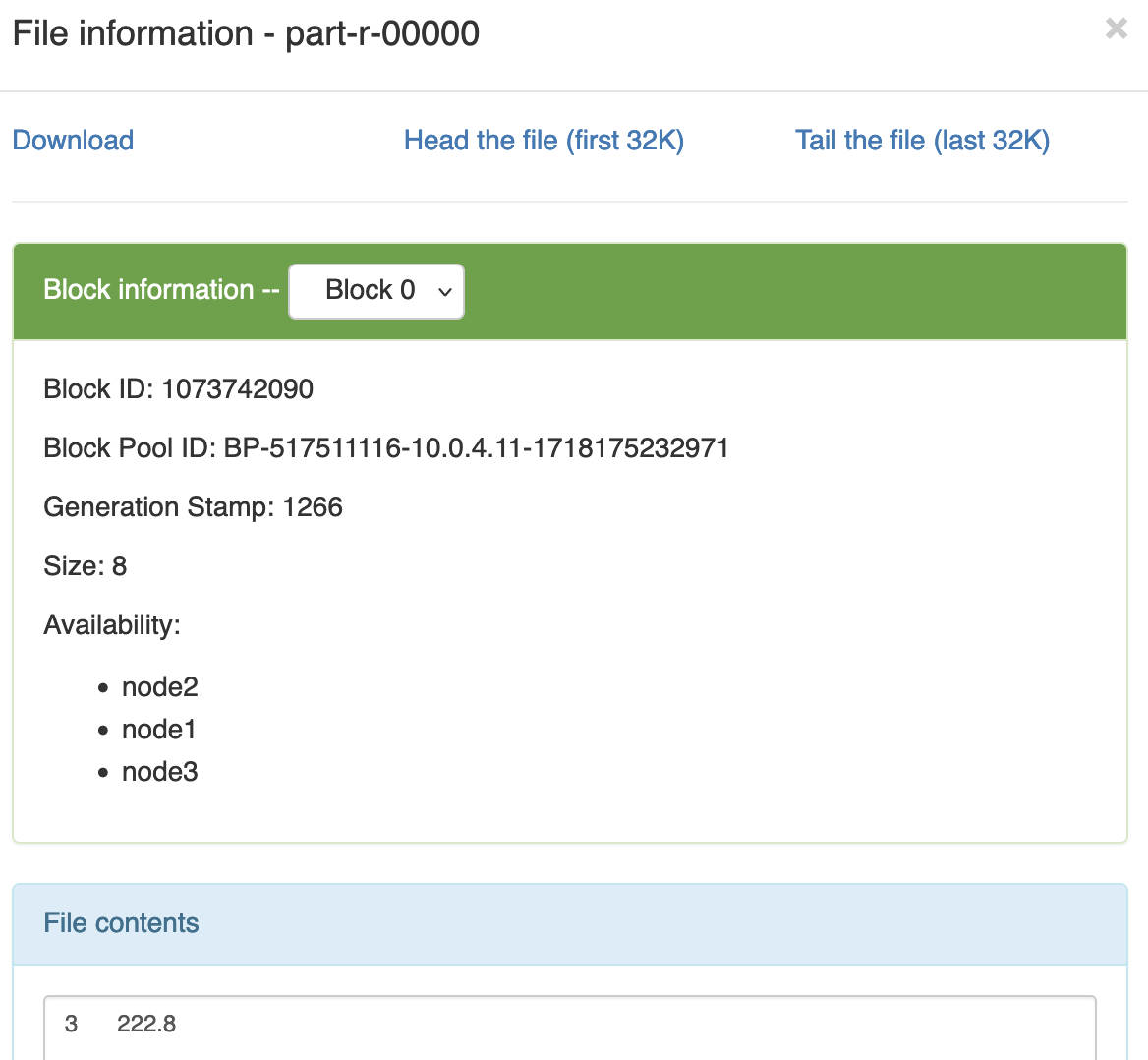
预期输出: